蔡瑞初,张盛强,许柏炎
(广东工业大学 计算机学院,广州 510006)
代码注释是程序源代码功能含义的可读注解,在软件维护过程中起到关键作用[1-2],然而由于编写代码注释的时间成本较高,软件项目中经常出现注释不全、不清晰,甚至无注释等情况。为了解决上述问题,软件工程社区提出了代码注释自动生成任务,其目标是通过机器学习的方法自动将程序代码转化为自然语言注释。代码注释生成作为自然语言生成[3-5]的一项重要任务,在近年来受到广泛关注[6-7]。
现有代码注释生成方法一般将源代码表示为序列形式或者抽象语法树(Abstract Syntax Tree,AST)形式。早期经典的研究方法[8]使用循环神经网络作为编码器对源代码序列进行建模。这种方法在建模过程中只关注源代码的序列信息,忽略了源代码的结构信息,导致生成的注释质量较差。为了捕获源代码中的结构信息,文献[9]将源代码表示为AST 中的一系列组合路径,并对每条路径进行编码。文献[10]提出一种基于结构的遍历方式来遍历AST,以获得更多的结构信息。文献[11]将源代码转化为多视角图,并将结构信息融入深度自注意力网络(Transformer)[12]。以上方法虽然从不同结构形式对源代码的结构特征进行建模,但是缺少对不同结构形式的融合过程,也缺乏充分考虑程序代码的语法结构的类型和层次信息,使得在面对复杂程序代码时生成的注释存在准确率低和可读性差的问题。
针对上述结构编码方面的缺陷,本文建立一种结构感知的混合编码(Structure-aware Hybrid Encoding,SHE)模型,包括序列编码、语法结构编码和聚合编码三层编码过程,能够同时捕获源代码的节点序列信息和语法结构信息。设计一种结构化感知的图注意力(Structure-aware Graph Attention,SGAT)网络作为SHE 的语法结构编码层,考虑了源代码的语法结构的层次和类型信息,以提升模型对复杂代码的结构学习能力。
根据对源代码的处理方式,可将现有的研究方法分为三类:基于序列的方法,基于树的方法和基于图的方法。
基于序列的方法直接将源代码转化为序列结构形式。文献[8]将源代码转化为序列,并使用带有注意力机制[13]的循环神经网络来生成注释。文献[14]使用两个编码器分别学习源代码的序列信息和API的序列信息,并在解码时通过API 知识辅助注释的生成。
基于树的方法通过语法解析器将源代码转化为AST。为了捕获源代码中的结构信息,文献[9]将源代码表示为AST 中的一系列组合路径,并在解码时使用注意力机制来选择相关路径。文献[15]所提出的模型采用两个门控循环单元(Gated Recurrent Unit,GRU)[16]分别对源代码序列和AST 进行编码,并在解码时通过融合源代码的序列信息和AST 的结构信息来构建上下文向量。文献[17]提出一种用于代码注释生成的编码器-解码器框架,该框架将源代码视为N 叉树并通过与类型相关的编码器和受类型限制的解码器以捕获更多的结构信息。
基于图的方法将源代码转化为图的形式。文献[18]将门控图神经网络(Gated Graph Neural Network,GGNN)[19]融入现有的序列编码器,使得模型能够捕获弱结构化数据中的长距离依赖关系。文献[20]使用图神经网络(Graph Neural Network,GNN)[21]来提取源代码的结构特征。文献[22]将源代码转化为基于注意力机制的动态图,并设计一种混合型GNN 来捕获局部和全局结构信息。
与上述三种结构编码研究方法不同,本文将源代码转化为程序图,并提出一种基于结构感知的混合编码模型(SHE)。通过融合序列编码层和图编码层以更好地捕获源代码的节点序列信息和语法结构信息。
在代码修复任务上,文献[23-24]均采用了序列模型和图模型堆叠的三层编码过程。但是,本文与上述工作采用了不同的序列编码层或图网络编码层。更进一步地,代码注释生成对比代码修复需要更好地理解代码的语法结构中蕴含的语义信息。本文提出的结构化感知的图注意力网络(SGAT)通过更好地考虑源代码的语法结构的层次和类型信息,以对复杂代码有更好的学习能力。
2.1 问题定义
首先对代码注释生成任务进行必要的公式化定义。当给定一段源代码C时,代码注释生成任务的目标是生成能够准确描述该源代码的自然语言注释Y={y1,y2,…,y||M}。为了更好地捕获源 代码的上下文信息和结构信息,同时考虑了源代码的序列表示和抽象语法树(AST)表示。长度为N的源代码序列表示为C={w1,w2,…,w|N|},其中wi代表源代码中的第i个词。源代码C的AST 表示需要通过语法解析器得到。将AST 树形表示进一步构建成程序图表示G。
2.2 程序图构建
程序图G={V,E}。在程序图G上,V表示节点vi的集合,节点vi={wi,τi}具有节点值wi和节点类型τi。节点构建过程如下:首先,通过语法解析器将源代码转化为AST 树形表示,AST 包含非终端节点和终端节点,其中,非终端节点代表特定的语法规则,终端节点代表文本标记(token),如标识符、字符串和数字;
然后,所有AST 上的节点都分配有对应的节点值和节点类型,即wi和τi。值得注意的是,当终端节点的节点值由多个单词构成时,将该终端节点拆分为多个类型相同的子节点。在程序图G上,E表示边{vi,vj,lij}的集合,lij表示节点vi和vj所连接的边类型。不同类型的边构建过程如下:首先,将default 语法边表示为AST 中节点的连接关系,用于语法信息的学习;
然后,在AST 中引入多种具有语义依赖信息的边。使用NextNode 边连接兄弟节点,以便信息能够在兄弟节点之间以更近的距离传播。使用SameToken 边连接所有具有相同节点值的节点,使得信息能够跨长距离传播。此外,为每条边添加相应的反向边(reverse),并为每个节点添加相应的自循环边(self-loop),以便对反向依赖和自依赖进行建模。
节点类型和语法边是由对应编程语言的语法解析器自动生成的,而具有语义依赖信息的边的构建过程是通用的。因此,本文提出的程序图构建过程具有通用性,可快速扩展到不同的编程语言。以Python 源代码为例,其对应的程序图和注释如图1所示。
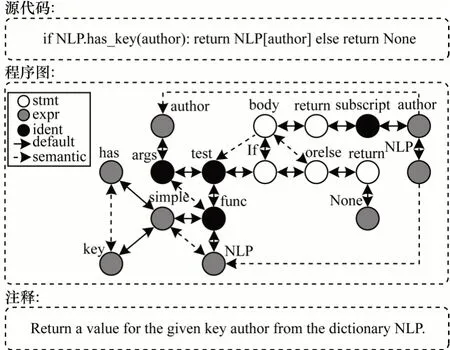
图1 Python 源代码对应的程序图和注释Fig.1 Corresponding program graph and comment for Python source code
2.3 模型架构
本文提出的SHE 模型整体架构如图2 所示,该模型包含以下三部分:程序图向量化,结构感知混合编码器和解码器。

图2 SHE 模型的整体架构Fig.2 Overall architecture of SHE model
在程序图G向量化阶段,主要对程序图的节点进行初始向量化操作,并作为结构感知混合编码器的输入。
在结构感知混合编码器阶段,主要包括了序列编码、语法结构编码和聚合编码三层编码过程。其核心是通过融合序列编码层和图编码层以更好地捕获源代码的上下文信息和语法结构信息。同时,为了更好地学习语法结构信息,本文设计的结构化感知的图注意力(SGAT)网络将节点类型和边类型的信息引入网络结构。
在解码器阶段,主要应用Transformer 和复制机制[25]有效避免自然语言生成任务中经典的未登录词(Out of Vocabulary,OOV)问题。
2.4 程序图向量化
首先,创建词典的词嵌入矩阵D,该词典可通过词id 进行查找。其次,将节点值映射到词典中的词id。根据词id 可得到节点值嵌入:
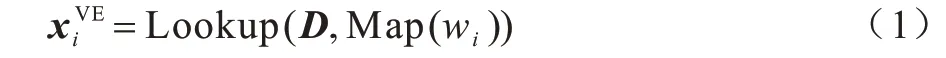
其中:Map 表示将词wi映射为词id 的函数;
Lookup表示词嵌入查找函数。
SHE 的Transformer 序列编码层通过注意力机制学习节点序列的表示,但无法自动捕获节点序列的位置信息。因此,需要将位置信息融入输入特征。根据节点vi所在的位置i可得到节点位置嵌入。

其中:dp表示位置嵌入的维 度;
表示节点vi的位置嵌入在第k维的值,当k为偶数时使用式(2)计算,当k为奇数时使用式(3)计算。
将节点值嵌入和位置嵌入相加后,可得到节点的输入特征X={x1,x2,…,x||N}。

2.5 结构感知混合编码器
2.5.1 Transformer 序列编码层
源代码片段长度一般较长,经典的长短期记忆网络无法很好地捕获源代码序列中的长期依赖关系。因此,采用Transformer 来提取源代码的上下文信息。Transformer 序列编码层由多个相同的层堆叠而成,并在每一层中应用多头注意力机制(multi-head attention)。将节点输入特征X={x1,x2,…,x||N}输送到Transformer序列编码层,可得到节点的输出特征P={p1,p2,…,p||N}。计算过程如式(6)~式(10)所示:


Transformer 的计算公式可简化如下:

2.5.2 SGAT 语法结构编码层
SHE 的语法结构编码层负责捕获源代码的复杂结构信息。现有的工作一般只考虑抽象语法树(AST)中节点的连接关系和层次信息,而忽略编码中的语法类型信息,导致无法很好地区分结构相似但语义不同的子树或者子图。源代码的语法类型包含不同的语义信息。通过引入语法类型信息,使得模型能够区分上述复杂语法结构。由于现有的图注意力网络无法很好地适用于多节点类型和多边类型的情况,因此本文提出结构化感知的图注意力网络(SGAT)用于程序图的结构学习。
将节点类型信息和边类型信息作为SGAT 语法结构编码层的可学习参数,而不是直接将节点类型信息和边类型信息作为特征输入编码器,使得SGAT能够更好地学习不同的语法结构表示,提升模型对复杂程序的结构学习能力。具体地,对于程序图G中的节点vi,分别计算其与邻居节点vj的相关系数oij:

其中:pi和pj表示经过Transformer 序列编码层优化后的 节点特 征;
τi和τj表示节点的类型;
lij表示节点之间的边类型;
Ni表示节点vi的邻居节点集合;
Wτi和Wτj表示与节点类型相关的权重矩阵;
rlij表示与边类型对应的向量;
a表示注意力机制,用于计算相关系数。
进一步地,将相关系数oij进行归一化,可得到归一化注意力系数gij:

其中:LeakyReLU 表示非线性激活函数;
exp 表示以自然常数e 为底的指数函数。
在得到归一化注意力系数gij后,对特征进行加权求和操作,可得到节点的输出特征Q={q1,q2,…,q||N}。

其中:Wτj和rlij表示注意力机制所对应的权重矩阵和向量;
σ表示非线性激活函数。
同时,采用多头注意力机制进一步提升模型的表现能力,具体如下:
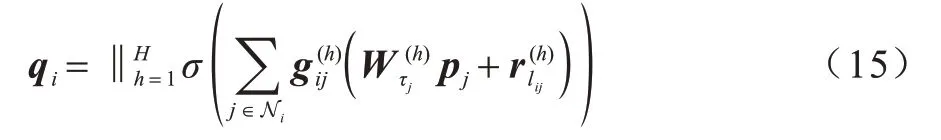
其中:H表示多头注意力机制的头数;
‖表示拼接操作。
SGAT 的计算公式可简化如下:

SGAT 通过对程序图中不同的节点类型和边类型引入可学习的参数,使得模型能够区分不同的节点类型和边类型的语义信息,因此能够更准确地捕获源代码中的结构信息。同时,通过多头注意力机制使得学习过程更加稳定,进一步提升了模型性能。
2.5.3 Transformer 聚合编码层
Transformer 序列编码层通过多头注意力机制来感知节点序列的全局信息,SGAT 语法结构编码层基于图的信息传播来捕获程序图的局部结构信息。为了聚合代码的上下文信息和语法结构信息,SHE 采用Transformer 聚合编码层有效地聚合前两层编码的结构表示并输出到解码器。通过该聚合编码层,可获得节点的最终输出特征U={u1,u2,…,u||N}。

首先,将节点序列的初始输入特征输送到Transformer 序列编码层,以提取源代码中的序列信息。其次,将优化后的特征输送到SGAT 语法结构编码层,以捕获源代码的复杂结构信息。为了防止网络退化问题,式(17)使用了残差连接。最后,采用Transformer 聚合编码层聚合前两层的信息并输出到解码器。
2.6 解码器
解码阶段采用Transformer 解码器来生成代码注释。同时,引入复制机制以提高生成的注释的质量。该解码器包含两种注意力机制:一种是基于掩码的多头注意力机制;
另一种是基于编码器-解码器的多头注意力机制。基于掩码的多头注意力机制仅用于解码器,其允许解码器结合之前输出的单词序列来决定当前阶段所输出的单词。在训练过程中,为了防止未来信息的泄露,需要遮掩未来阶段的单词。基于编码器-解码器的多头注意力机制则用于编码器和解码器之间,其能够让解码器捕捉到编码器的输出信息。
通过Transformer 解码器,可得到解码阶段t的目标词典的概率分布Pv:

其中:Softmax 表示归一化指数函数;
Wgen表示可学习的参数矩阵;
st表示解码阶段输出的隐藏状态。
在构建目标词典时,通常会过滤掉出现频次较低的单词,以限制目标词典的大小。这些出现频次较低的单词不存在于目标词典中,被称为未登录词(OOV)。但是,源代码中表示数值或字符的低频词包含重要的信息,其经常出现在目标注释中。如果忽略了包含重要信息的低频词,将使得生成的注释出现准确率降低的问题。为了缓解OOV 现象,采用复制机制以一定的概率从输入中复制单词。
在解码阶段t,计算隐藏状态st与聚合编码层的输出特征U={u1,u2,…,u||N}的归一化注意力系数fti:

其中:score 表示计算相关系数的函数。
在得到归一化注意力系数fti后,计算生成概率pg∈[0,1]:
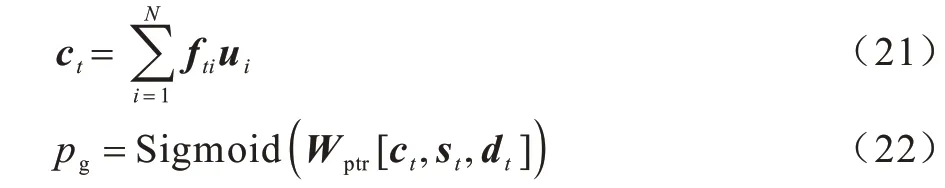
其中:Wptr表示可学习的参数矩阵;
ct表示通过加权求和得到的上下文向量;
dt表示当前解码阶段的输入;
Sigmoid 表示非线性激活函数。
由生成概率pg可得到解码阶段t的目标词典的概率分布Pfin(m):
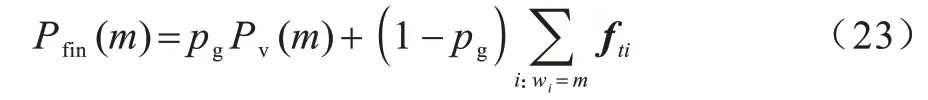
其中:m表示目标词典中的某个单词;
wi表示节点vi的节点值。因此,每个单词的最终输出概率由其生成概率和复制概率共同决定。
通过最小化交叉熵损失函数对模型进行训练:
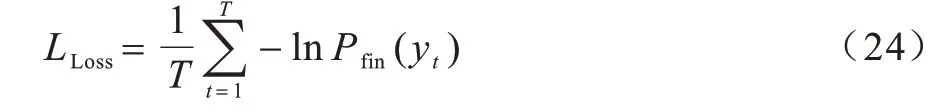
其中:yt表示解码阶段t的目标单词。
3.1 数据集
实验数据采用文献[26]提供的Python 数据集和文献[14]提供的Java 数据集。Python 数据集包含55 538 个训练样本、18 505 个验证样本和18 502 个测试样本。Java 数据集包含69 708 个训练样本、8 714 个验证样本和8 714 个测试样本。使用相应的语法解析器将源代码转化为AST。对于Python 源代码,生成的AST 包含14 种节点类型。对于Java 源代码,生成的AST 包含15 种节点类型。在AST 的基础上,通过添加多种具有语义依赖信息的边来构建程序图。
3.2 评价指标
为了更准确地评估模型效果,实验采用BLEU[27]、ROUGE[28]和METEOR[29]三种被广泛使用的评价指标从不同角度考虑生成的注释的质量。BLEU 与ROUGE类似,但BLEU侧重于计算准确率,而ROUGE 更加关注召回率。METEOR 通过引入同义词集,在计算得分时考虑了同义词及词性变换的情况。
3.3 参数设置
实验基于PyTorch 框架在RTX 3090 GPU 上进行训练。在训练过程中,使用Adam[30]作为优化器,并使用0.000 05 作为初始学习率。在权重初始化过程中,使用Xavier[31]作为初始化器。对于编码器和解码器,多头注意力机制的隐藏层单元数设置为64,头数设置为8,单词嵌入的维度设置为512。在编码过程中,节点的最大数量设置为400。在解码过程中,生成的注释的最大长度设置为50。
3.4 基准模型
为了全面评估SHE 的性能,选用多个具有代表性的模型进行对比和分析。
1)CODE-NN[8]是第一个使用端到端的方式将源代码转化为注释的模型,通过使用带有注意力机制的LSTM[32]来解决代码注释生成任务,并取得了显著的效果。
2)DeepCom[10]通过基于结构的遍历方式获得模型所需的输入序列。相比于通过前序遍历方式所获得的序列,基于结构的遍历方式所获得的序列可还原为原始的AST,在提取结构信息上更加有效。
3)Tree2Seq[33]使用基于树 的LSTM 作为编码器,以显式地捕获结构信息。
4)RL+Hybrid2Seq[26]利用LSTM 和基于AST 的LSTM 来分别提取源代码的序列特征和结构特征,并采用强化学习的方式来训练模型。
5)API+CODE[14]通过源代码中的API 知识来辅助代码注释生成。
6)Dual Model[34]将代码生成和代码注释生成作为对偶任务,进一步提升了生成的注释的质量。
7)Trans[35]是一种用于表示源代码中的标记之间的相对位置的方法,并在解码过程中应用了复制机制来辅助注释生成。
8)SiT[11]是一 种Transformer的变体。SiT 将源代码转化为多视角图,并将结构信息融入Transformer。
3.5 结果分析
3.5.1 模型性能分析
不同模型在Python 数据集和Java 数据集上的实验结果如表1 和表2 所示,其中加粗表示最优的结果。CODE-NN 的评价指标得分低于其他模型,因为其没有建立语言模型,不能很好地捕获源代码的序列信息和结构信息。DeepCom、Tree2Seq 和RL+Hybrid2Seq 通过不同方式对源代码进行建模,使得模型能够捕获源代码中的结构信息。API+CODE 通过API 知识指导注释的生成,在Java 数据集上取得了较高的得分。Dual Model 将代码生成任务和代码注释生成任务视为对偶任务,进一步提升了生成的注释的质量。Trans 和SiT 使用Transformer 来学习源代码的表示,提升了模型的表现能力。
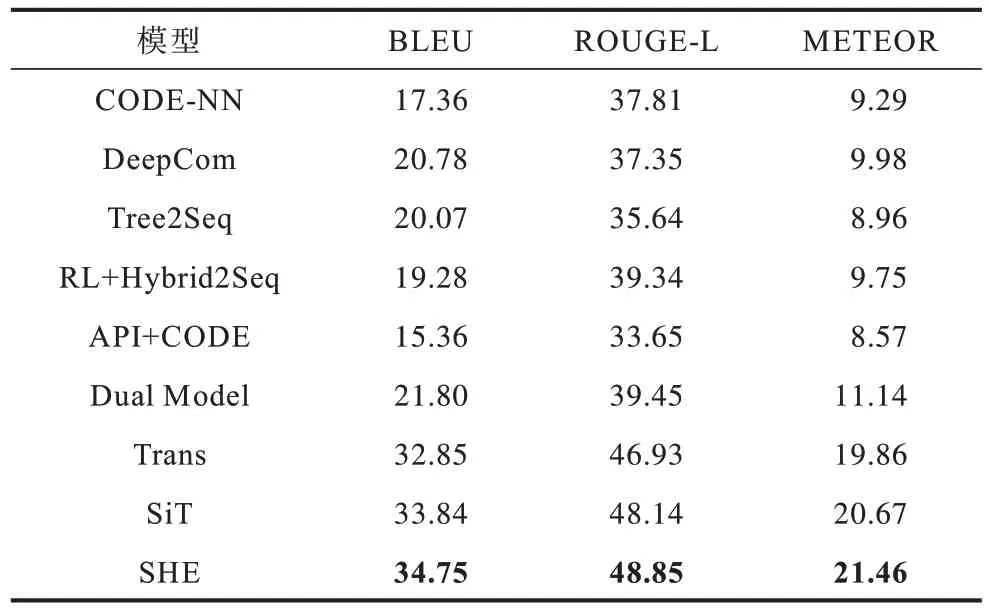
表1 不同模型在Python 数据集上的性能对比结果 Table 1 Performance comparison results of different models on Python dataset %

表2 不同模型在Java 数据集上的性能对比结果 Table 2 Performance comparison results of different models on Java dataset %
由表1 和表2 可知,SHE 在Python 数据集和Java数据集上的评价指标得分均高于所有基准模型。与SiT 模型相比,SHE 在Python 数据集上的BLEU、ROUGE-L 和METEOR 得分分别提高了2.68%、1.47%和3.82%,在Java数据集上的BLEU、ROUGE-L 和METEOR 得分分别提高 了2.51%、2.24% 和3.55%。实验结果表明,SHE 能够更好地捕获源代码的节点序列信息和复杂的语法结构信息。
3.5.2 模型收敛速度分析
模型的收敛速度决定模型达到最佳性能时所需时间的长短。不同模型在Java 训练集上的收敛速度对比结果如图3 所示。通过设置ROUGE-L 和BLEU性能参考线观察,SHE 需要约90 个训练轮数到达参考线,而SiT 则需要约175 个训练轮数。可见,SHE具有结构化感知的混合编码结构,对复杂语法结构有更高效的学习能力,模型有更快的收敛速度。
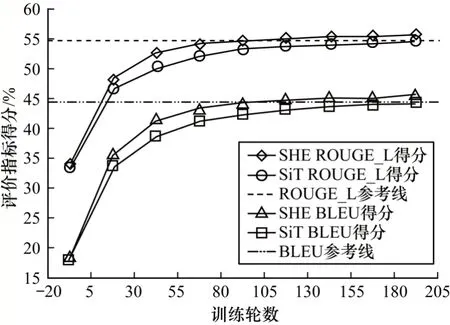
图3 不同模型在Java 训练集上的收敛速度对比结果Fig.3 Comparison results of convergence speed of different models on Java training set
3.5.3 模型参数分析
多头注意力机制的头数和隐藏层单元数是影响模型性能的重要参数。为方便对比,将所有编码层的多头注意力机制的头数和隐藏层单元数均设置为相同的值。
不同头数的模型在Python 数据集上的实验结果如表3 所示,当多头注意力机制的隐藏层单元数设置为64时,随着头数的增加,模型的性能越来越好,这说明在一定程度上增加头数能够使得网络从不同子空间捕获到更丰富的特征。
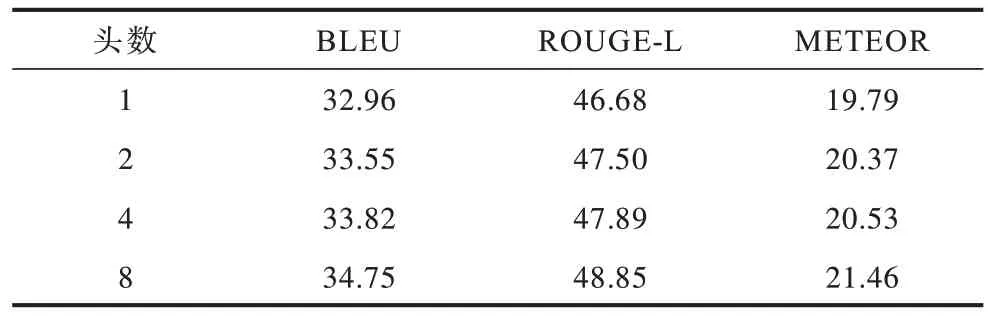
表3 不同头数的模型在Python 数据集上的实验结果 Table 3 Experimental results of models with different number of heads on Python dataset %
如表4 所示,在多头注意力机制的头数设置为8的情况下,随着隐藏层单元数的增加,模型在不同评价指标上的得分也越来越高,这说明在一定程度上增加隐藏层单元数能够提升网络的表现能力。

表4 不同隐藏层单元数的模型在Python 数据集上的实验结果 Table 4 Experimental results of models with different number of hidden layer units on Python dataset %
3.5.4 代码长度分析
代码长度是衡量模型表现能力的重要因素之一。不同代码长度的模型在Python 数据集上的实验结果如图4 所示。
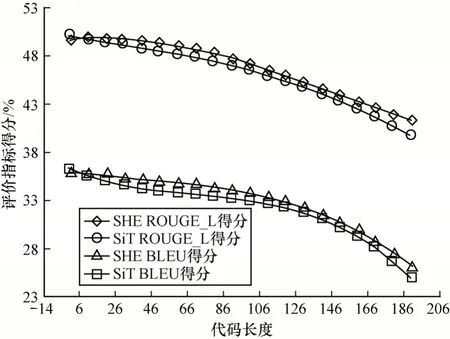
图4 不同代码长度的模型在Python 数据集上的实验结果Fig.4 Experimental results of models with different code lengths on Python dataset
随着代码长度的增加,不同模型所取得的BLEU 得分和ROUGE_L 得分均呈下降趋势,这说明代码长度越长,模型越难捕获源代码的完整信息。在相同代码长度的情况下,SHE 所取得的BLEU 得分和ROUGE_L 得分高于SiT,这说明SHE 对于更复杂的程序代码仍然具有良好的结构学习能力。
3.5.5 节点排列顺序分析
程序图中节点的排列顺序与AST 中节点的排列顺序一致。通过不同的遍历方式可得到不同的节点排列顺序。为了探究程序图中节点的排列顺序对模型性能的影响,设计相关对比实验。不同的节点排列顺序在Python 数据集和Java 数据集上的实验结果如表5 和表6 所示。由表5 和表6 可知,在Python 数据集和Java 数据集上,对于SiT 和SHE,按不同遍历方式排列所取得的指标得分在相应的模型中均没有明显的差距,这可能是因为按不同遍历方式所得到的节点序列的排列顺序虽然不同,但仍然包含AST 中的有效信息。

表5 不同节点排列顺序的模型在Python 数据集上的实验结果 Table 5 Experimental results of models with different node arrangement orders on Python dataset %
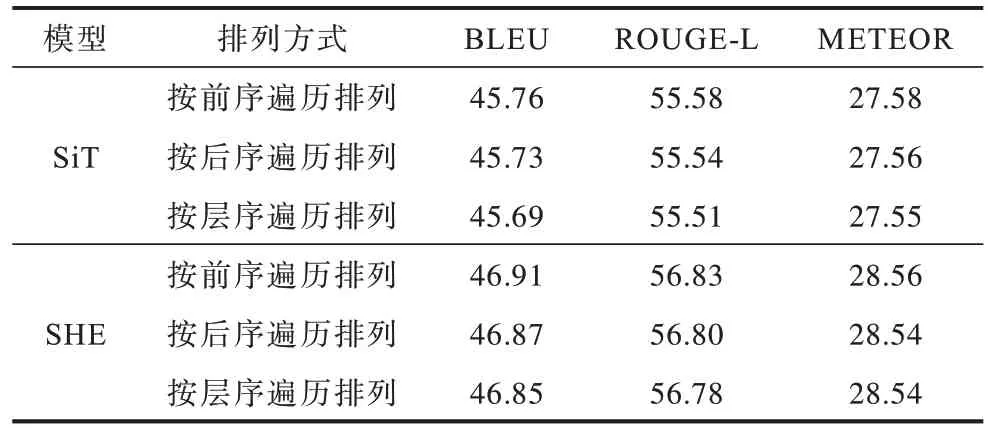
表6 不同节点排列顺序的模型在Java数据集上的实验结果Table 6 Experimental results of models with different node arrangement orders on Java dataset %
3.6 消融实验分析
为了进一步探究模型各组成部分的作用,设计消融实验。在Python 数据集上的消融实验结果如表7 所示,其中,加粗表示最优的结果,No-SGAT 表示仅考虑源代码的节点序列信息,No-ET-NT 表示不区分程序图的节点类型和边类型,No-ET 表示不考虑程序图的边类型信息,No-NT 表示不考虑程序图的节点类型信息,No-AEL 表示不采用Transformer聚合编码层。
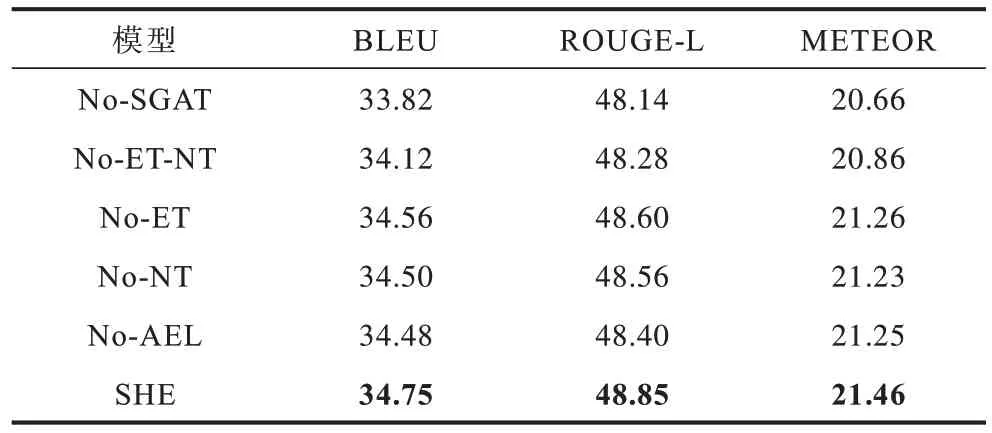
表7 在Python 数据集上的消融实验结果 Table 7 Results of ablation experiments on Python dataset %
由表7 可以看出:仅考虑源代码的节点序列信息,将导致模型的性能下降;
在不区分程序图的节点类型和边类型的情况下,模型取得的评价指标得分均有所提升,这说明将源代码转化为程序图能够提高模型的表现能力;
在考虑节点类型信息或边类型信息的情况下,模型的性能得到进一步提升,这表明节点类型信息和边类型信息能够提升编码模型对复杂程序的结构学习能力;
不采用Transformer 聚合编码层使得模型无法有效聚合前两层的信息,降低了模型捕获源代码的节点序列信息和语法结构信息的能力。
3.7 案例展示
为了进一步分析模型所生成的注释的质量,进行案例展示。Python 示例和Java 示例具体如下:


由上述可以看出,SHE 所生成的注释更准确和流畅。对于Python 示例,虽然源代码中没有出现单词“binary”,但SHE 所生成的注释仍然能够准确地预测出单词“binary”。对于Java 示例,由于源代码中的方法名不足以描述该代码段的主要功能,因此SiT 生成的注释的质量较差。但是,SHE 生成的注释仍然具有较高的可读性和准确性。
本文针对代码注释生成任务,提出一种结构感知的混合编码(SHE)模型,通过融合序列编码层和图编码层,能够同时捕获程序代码的节点序列信息和语法结构信息。针对程序代码的语法类型信息,设计一种结构化感知的图注意力(SGAT)网络,提升了编码模型对于复杂程序代码的结构学习能力。实验通过包含多种编程语言的代码注释生成的数据集验证了SHE 模型对比基准模型的提升效果,且能生成更准确的代码注释,同时消融实验也验证了SGAT网络的有效性。在未来的工作中,将进一步改进程序图的构建方式,使得程序图包含更多的语义信息,以对复杂程序代码有更好的结构学习能力。同时,将进一步优化序列编码层与图编码层的融合方式,以更好地捕获程序代码的序列信息和语法结构信息。
猜你喜欢语法结构源代码集上基于TXL的源代码插桩技术研究现代信息科技(2021年21期)2021-05-07Cookie-Cutter集上的Gibbs测度数学年刊A辑(中文版)(2020年2期)2020-07-25链完备偏序集上广义向量均衡问题解映射的保序性数学物理学报(2019年6期)2020-01-13分形集上的Ostrowski型不等式和Ostrowski-Grüss型不等式井冈山大学学报(自然科学版)(2019年4期)2019-09-09软件源代码非公知性司法鉴定方法探析中国司法鉴定(2018年4期)2018-07-30基于语法和语义结合的源代码精确搜索方法计算机应用(2017年10期)2017-12-14长沙方言中的特色词尾青春岁月(2016年22期)2016-12-23浅析古代汉语的名词动用青春岁月(2016年21期)2016-12-20培养阅读技巧,提高阅读能力考试周刊(2016年34期)2016-05-28揭秘龙湖产品“源代码”中国房地产业(2016年8期)2016-03-01