毛雪丽,米吉提·阿不里米提,艾斯卡尔·艾木都拉
(新疆大学信息科学与工程学院,新疆 乌鲁木齐 830046)
语种识别,是通过计算机对给定的语音信号进行分析处理、自动识别其所属语言种类的过程[1]。作为语音识别及相关领域的一个前端技术,语种识别也被称为语言辨识。随着全球化的发展,跨国语言交流日益增多,导致多语言共生的现象频繁出现,许多领域对语种识别及相关技术的需求也愈加迫切,进而推动了语种识别在多语言语音处理方面的发展。国际上和国内的众多研究机构,如MIT林肯实验室,卡耐基梅隆大学,国内的中科院自动化所、中科院声学所、中科大等,对语种识别技术进行了广泛的研究[2]。但国内外的研究主要集中在英语,法语,西班牙语、德语、阿拉伯语等通用语言上,而对资源匮乏语言的研究相对较少,尤其是资源匮乏的同语系语言的语种识别。一是由于语料资源的缺少,主要表现在语音数据、文本数据、音素集、发音词典等方面。二是由于语言的复杂性和个异性较强,使得不同语言在语音和语法层次有较大的差异性,使得该类语言的语种识别研究面临极大的挑战。
早期的语种识别属于传统方法,主要是基于音素特征和基于声学特征的语种识别等。基于音素特征的语种识别利用不同语种的音素搭配关系作为差异特征。利用音素识别器,得到语音信号的最优音素序列,根据这个序列为每个语种建立N-Gram模型。基于声学特征的语种识别,通过提取语音信号的声学特征,采用概率统计对其进行建模。常用的声学特征有梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficient,MFCC)[3]、感知线性预测系数(Perceptual Linear Predictive,PLP)[4]、移位差分倒谱系数(Shifted Delta Cepstrum,SDC)[5]等。主流的语种识别系统主要有高斯混合模型-全局背景模型(Gaussian Mixture Model-Universal Background Model,GMM-UBM)[6]、高斯超向量-支持向量机(GMM SuperVector-SupportVector Machines,GSV-SVM)[7]和基于全差异空间(Total Tariability,TV)[8]的i-vector 系统等。
近年来,深度神经网络(Deep Neural Networks,DNNs)[9]模型被应用于语种识别,并取得了良好的发展。一方面是从特征提取出发,文献[10]利用DNN提取了深度瓶颈特征(Deep Bottleneck Feature,DBF);
另一方面是从模型出发,文献[11]提出了基于深度神经网络的全差异空间(Total Varaibility,TV)建模方法 进行了语种识别。此外,也出现了深度学习端到端语种识别系统。2014年Google的研究人员将特征提取、特征变换和分类结合到一个神经网络模型中,这是端到端系统首次应用于语种识别任务中[12]。在这之后,研究者开始采用不同的神经网络进行语种识别的研究,包括时延神经网络(Time-Delay Neural Network,TDNN)[13],长短时记忆递归神经网络(Long Short Term Memory-Recurrent Neural Network,LSTM-RNN)[14]等。2016年,Geng等人[15]将注意力机制模型(Attention-based model)引入到语种识别系统中。2017年,Bartz等人[16]利用混合卷积递归神经网络(CRNN)进行语种识别。
在文献[16]的工作基础上,本文利用CNN-BiGRU模型对同语系(阿尔泰语系的哈萨克语和维吾尔语、汉藏语系的汉语和藏语)和跨语系(哈萨克语、维吾尔语、汉语和藏语)语言进行了研究。首先将语音数据转化为相应的灰度语谱图,其次利用CNN提取语谱图的空间特征,之后运用BiGRU提取语谱图的时间序列信息,最终输出语种的分类结果。本文结构安排如下:第三部分介绍采用的的方法,第四部分介绍实验设置,第五部分描述实验并分析结果,第六部分进行总结。
3.1 语谱图生成
语谱图是语音信号在图像域的一种表示方法,它能够表示语音信号不同频段的强度,可以通过傅里叶变换从语音信号中产生。语谱图的横坐标表示时间,纵坐标表示频率,同时语谱图中显示了大量与语音特性有关的重要信息。图1为语音波形及语谱图示例。其中(a)、(b)分别为维吾尔语(Uyghur)的语音波形和语谱图;
(c)、(d)分别为哈萨克语(Kazakh)的语音波形和语谱图。语音信号的语谱图特征的提取流程如图2所示。
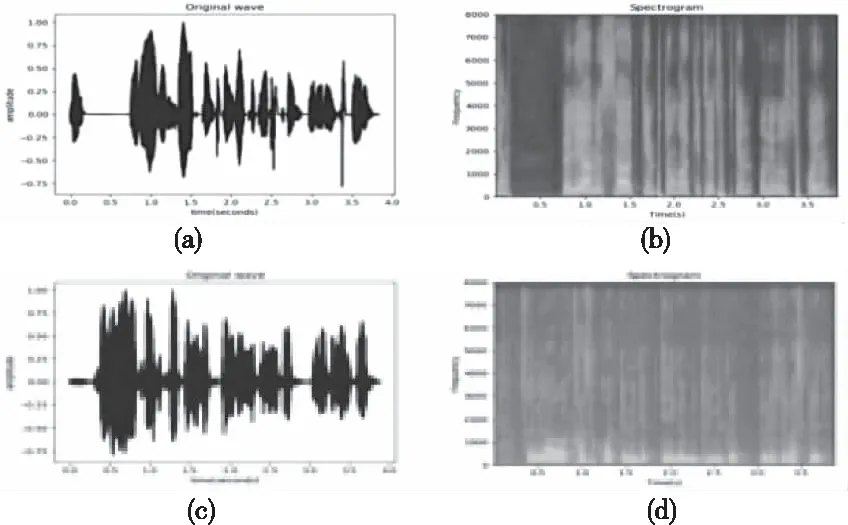
图1 语音波形及语谱图示例

图2 语谱图特征的提取流程
在提取特征之前,通常要对语音信号进行预处理,预处理包括预加重、分帧和加窗。语谱图特征提取的具体步骤如下所示:
1)预加重:将原始语音通过一个高通滤波器,其滤波器函数如式(1)所示。
H(Z)=1-μ/z
(1)
其中,μ值通常介于0.9-1之间,一般选μ值为0.97。
2)分帧:语音信号具有短时平稳性。因此,要进行短时分析,需要进行分帧。分帧时,相邻两帧之间存在重叠部分,是帧移,可以使得相邻两帧可以平滑过渡。常用的帧长为25ms,帧移为10ms。
3)加窗:为了避免频谱的混叠。常见的窗函数有汉明窗(Hamming)、汉宁窗(Hanning)等。汉明窗函数如式(2)所示。

(2)
4)快速傅里叶变换:语音信号完成预处理后,采用快速傅里叶变换(fast Fourier transform,FFT)将语音信号从时域转换到频域,计算过程如式(3)所示

(3)
其中,x(n)是离散时域的语音信号,X(k)是频域的语音信号,N表示傅里叶变换的点数,N=0,1,…,n-1。
5)取功率谱:将语音信号的频谱取模的平方,得到语音信号的功率谱。
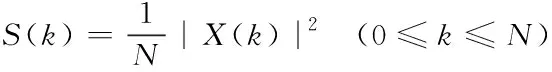
(4)
其中,X(k)是频域的语音信号,S(k)是语音信号的功率谱,N表示傅里叶变换的点数。
6)取对数:对功率谱进行取对数运算,得到语谱图特征。
3.2 双向门控循环单元
卷积网络对图像进行处理时,是把图像整体送入网络,进行一层一层的卷积运算,因而卷积网络对图片的分类有较好的效果。但是,对于与时间序列相关的任务,卷积网络的表现会相对逊色一些。因此,采用了循环网络,它可以很好的处理时间序列任务。Cho等人[17]提出门控循环单元(Gated Recurrent Units,GRU),双向门控循环单元(Bidirectional GRU,BiGRU)是由前向和后向的GRU构成,是一种双向的网络结构。其中,前向GRU学习当前时刻之前的信息,而后向GRU学习当前时刻以后的信息,因此该网络能够学习到时间上下文信息,从而弥补卷积网络的不足。BiGRU网络由输入层、前向GRU和后向GRU以及输出层等四部分组成,其网络结构如图3所示。
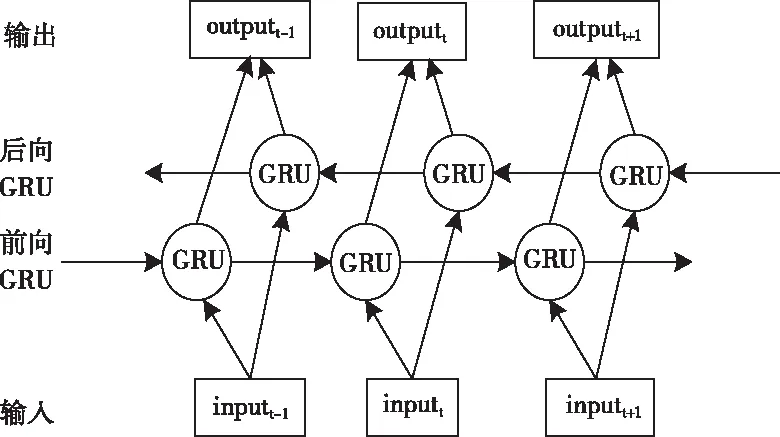
图3 BiGRU网络结构
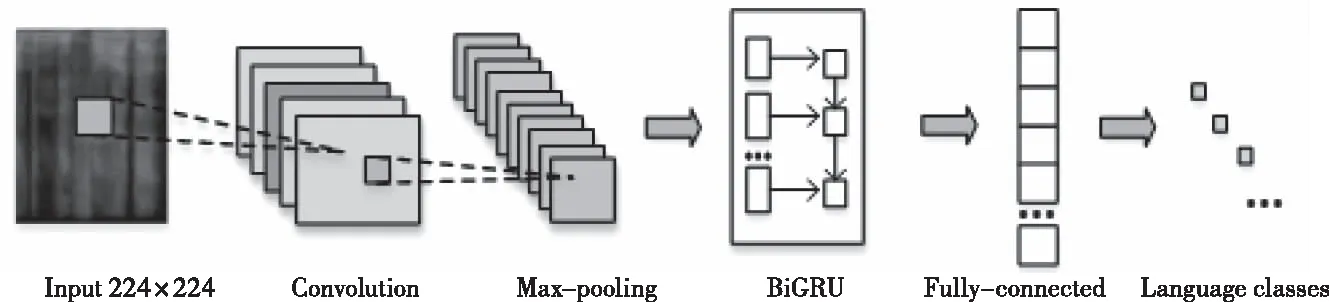
图5 基于CNN-BiGRU的语种识别网络结构
其中,inputt-1、inputt、inputt+1分别表示t-1、t、t+1时刻所对应的输入,outputt-1、outputt、outputt+1分别表示t-1、t、t+1时刻对应的输出。前向GRU,是指沿着时刻的正向顺序,计算其输出。后向GRU,指沿着时刻的反向顺序,计算其输出,最后在相应的时刻将二者的输出一起作为最后的输出。与LSTM相比,GRU少了存储单元的设置,它通过隐藏状态来信息传递,从而使其网络中的学习参数量减少。GRU有更新门和重置门,其中,更新门能够抑制被遗忘的信息和被添加的新信息;
重置门可以反映了对先前信息的遗忘程度。通过更新门和重置门,GRU可以实现对输入值、记忆值和输出值的控制,GRU的结构如图4所示。

图4 GRU网络结构
在t时刻,GRU更新的过程如以下的计算公式所示
rt=σ(Wr·[ht-1,xt])
(5)
zt=σ(Wz·[ht-1,xt])
(6)

(7)

(8)
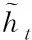
3.3 基于CNN-BiGRU的语种识别模型
本文采用CNN-BiGRU网络进行语种识别,该网络主要包括两个部分。第一部分为卷积网络,能够提取语谱图的局部特征;
第二部分是双向门控循环单元网络,可以更好地捕捉语谱图中的时序信息。卷积网络使用4个卷积层和4个最大池化层。其中,卷积层中卷积核的大小和数目分别为(7*7,16),(5*5,32),(3*3,32),(3*3,32)。每个最大池化层中卷积核的大小为3*3,步长为2。BiGRU中含有1024个神经元(前向和后向的GRU各有512个神经元),之后送入全连接层,实现分类。基于CNN-BiGRU的语种识别网络结构如图5所示,该网络各层的参数信息如表1所示。

表1 CNN-BiGRU网络各层的参数信息
4.1 实验数据集
东方语种识别比赛(AP17 Oriental Language Recognition)的任务是识别汉语、粤语、维吾尔语、哈萨克语等东方语言[18]。本文在该比赛提供的数据集上进行实验,该数据集包含由M2ASR NSFC[19]项目提供的维吾尔语,哈萨克语和藏语三种少数民族语言。本文从东方语种数据集中抽取维吾尔语、哈萨克语、汉语、藏语等4种语言,每种语言各1800条语音数据,按照70% (训练集)、20% (验证集)、10% (测试集)的比例进行划分,数据集结构如表2所示。

表2 数据集结构
4.2 实验设置
本文利用pytorch框架,在NVIDIA GeForce GTX 1080GPU上搭建语种识别模型进行实验。将语音数据经过预处理和特征提取后输入到语种识别模型,训练和验证网络模型时,其输入为224*224的灰度语谱图,批量大小为32*32(batch size),采用Adam优化器,学习率为0.002,损失函数采用交叉熵函数。采用的性能评估指标有精确率、召回率、准确率和F1值。精确率(Precision,P)是指模型预测正确的正例数占预测为正例总样本的比例。召回率(Recall,R)是指模型预测正确的正例数占真正的正例样本的比例。准确率指(Accuracy,acc)是指模型正确分类的样本占总样本的比例,F1是一个综合评价指标,是精确率和召回率的调和平均值。准确率和F1值越高,则表明模型的识别效果越好。
本文实验分为两部分,第一部分是采用本文研究的模型(CNN-BiGRU)对不同的语音特征进行实验,第二部分是采用不同的模型对最好的特征进行实验。使用相同的数据集,不断训练学习,调整参数优化结果,选取最优的结果进行对比。
5.1 不同特征对比实验
选取语谱图特征、FBank特征、MFCC特征等三种不同的特征提取方式,使用本文研究的模型分别对同语系语言(阿尔泰语系的维吾尔语和哈萨克语、汉藏语系的汉语和藏语)以及跨语系语言(维吾尔语、哈萨克语、汉语和藏语)进行实验,分析模型CNN-BiGRU在不同特征下的效果。实验结果如表3、4、5所示。
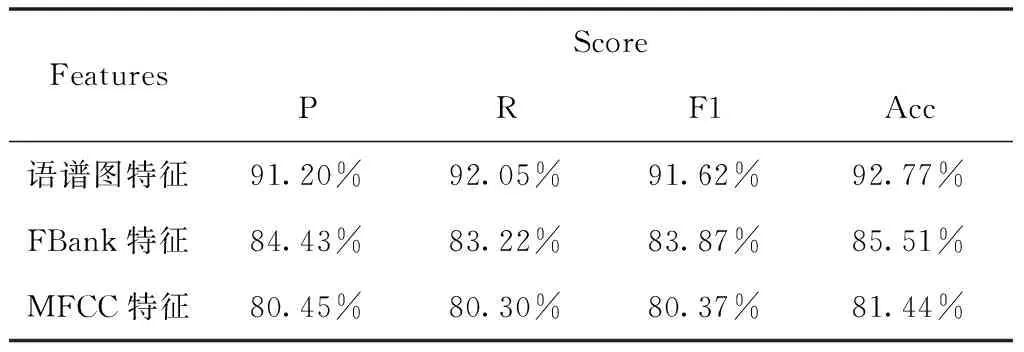
表3 特征对比实验结果(维吾尔语和哈萨克语数据集)

表4 特征对比实验(汉语和藏语数据集)
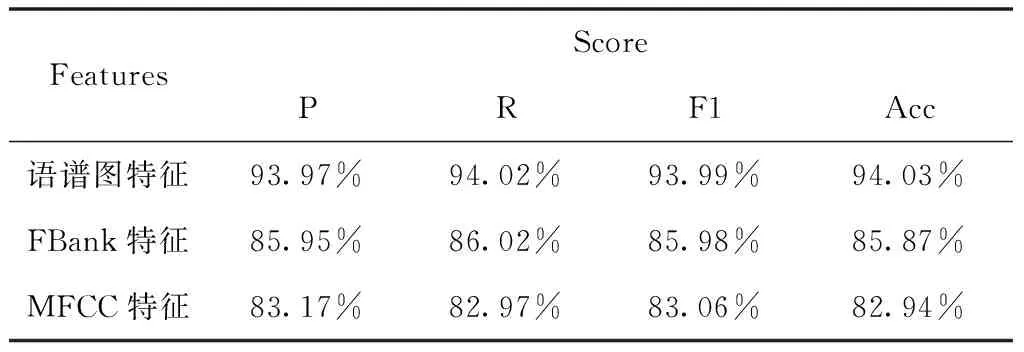
表5 特征对比实验结果(维吾尔语、哈萨克语、汉语和藏语数据集)
从表3、4、5中可以看出,在语谱图特征、FBank特征、MFCC特征等三种特征之中,使用语谱图特征进行实验的效果最好,而使用MFCC特征进行实验的效果最差,这是由于语谱图特征是语音数据的频域表示,包含的语音信息最为丰富,而FBank、MFCC特征是在语谱图基础上进行一系列变换生成的,会导致部分语音信息丢失,从而影响实验效果。同时可以看出在同语系(阿尔泰语系、汉藏语系)语种识别中,汉藏语系的汉语和藏语的识别效果要优于阿尔泰语系的维语和哈萨克语,这是由于汉语和藏语之间的发音差异远比维吾尔语和哈萨克语大,使得网络提取和学习特征更容易,识别效果更好。
5.2 不同模型对照实验
设置CNN、GRU、LSTM、CNN-BiLSTM、CNN-BiGRU等五种模型作为对照实验,分别对同语系语言 (阿尔泰语系的维吾尔语和哈萨克语、汉藏语系的汉语和藏语) 以及跨语系语言 (维吾尔语、哈萨克语、汉语和藏语) 的语谱图特征进行实验,分析不同模型在语谱图特征下的性能。实验结果如表6、7、8所示。
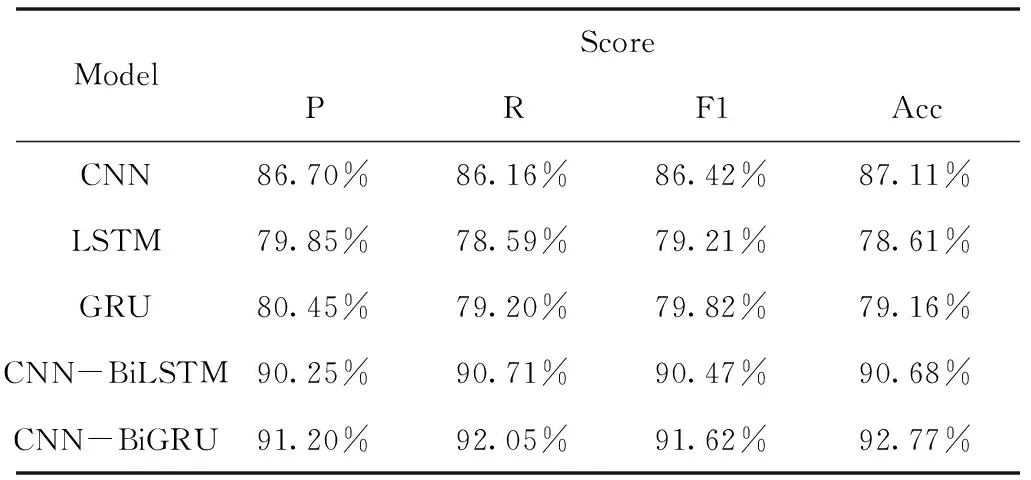
表6 模型对比实验结果(维吾尔语和哈萨克语数据集)

表7 模型对比实验结果(汉语和藏语数据集)

表8 模型对比实验结果(维吾尔语、哈萨克语、汉语和藏语数据集)
从表6-8可看出,LSTM模型的的F1和Acc均为几种模型中最低的,这是由于LSTM主要关注的是时序信息,无法像卷积网络一样很好地捕捉到语谱图的图像特征。对比几种不同的循环神经网络模型,可以看出,GRU模型作为LSTM模型的优化,两者的性能非常接近,但是GRU模型的性能比LSTM模型略好。同时CNN与GRU/LSTM两种模型融合后的网络性能均优于CNN、GRU和LSTM模型。其中CNN-BiGRU的准确率相对CNN、GRU有所提升,CNN-BiLSTM的准确率相对CNN、LSTM亦是如此,说明融合后的网络能够更好地利用语谱图图像特征和时序信息,从而提升语种识别的准确率和F1值,获得较好的结果。
本文构建了CNN-BiGRU网络语种识别模型,对两个同语系语言(阿尔泰语系的维吾尔语、哈萨克语,汉藏语系的汉语和藏语)和跨语系语言(维吾尔语、哈萨克语、汉语和藏语)进行了语种识别。通过提取不同的特征和设置不同模型的比较实验,进行了结果分析。实验发现,最有效的特征是语谱图特征,表现最好的模型是CNN-BiGRU网络。实验提取语音数据的有效特征,并提取语谱图的视觉特征和时序信息特征,将其送入神经网络模型训练学习,最终分类输出语言类别。通过实验可以表明,本文提出的方法在同语系语言及跨语系语言的语种识别上都取得了较好的结果,但是本文涉及的语种较少,语料数据也比较少。在接下来的工作中,将会继续在较大语料以及其它语种、方言上进行语种识别的探索,进一步开展相关研究。
猜你喜欢 哈萨克语维吾尔语语种 《波斯语课》:两个人的小语种时代邮刊(2021年8期)2021-07-21浅析维吾尔语表可能语气词中国民族博览(2019年10期)2019-11-29统计与规则相结合的维吾尔语人名识别方法自动化学报(2017年4期)2017-06-15维吾尔语话题的韵律表现新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12哈萨克语附加成分-A新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12从喻体选择对比哈萨克语和汉语比喻的民族差异语言与翻译(2015年3期)2015-07-18现代哈萨克语命令语气单句语调对比实验研究语言与翻译(2015年1期)2015-07-18蒙古语-哈萨克语部分词同源关系研究语言与翻译(2015年1期)2015-07-18维吾尔语词重音的形式判断语言与翻译(2015年4期)2015-07-18走出报考小语种专业的两大误区高中生·天天向上(2009年11期)2009-12-17