田昕怡,牛 彬,钟睿君,孙淑娴
(国网天津市电力公司营销服务中心,天津 300000)
随着计量设备的推广普及,计量设备在运行过程中出现的可靠性问题与电子行业发展联系较为密切,且不容忽视。对集成电路、电子计算机、雷达等电子设备而言,一旦发生计量失误,可能会导致设备损坏,甚至威胁到人身安全,后果将不堪设想,因此对于计量设备系统来说,可靠性的评估与预测具有深远的意义[1]。
本文将计量设备的可靠性测试或实际运行中得出的失效数据(故障间隔时间、故障次数等)视为—个时间序列,即为一组依赖于时间t的随机变量序列。这些变量之间有一定的依存性和相关性,而且表现出了一定的规律性,如果能根据这些失效数据建立尽可能合理的统计模型,就能用这些模型来解释数据的规律性,就可以利用已得到的失效数据来预测未来数据,也就能据此来预估计量设备的可靠性[2]。
本文从可靠性基础出发,基于计量设备指定模块的失效,讨论计量设备模块的失效,建立失效数据分布数学模型,以便对失效进行评价。本文的研究成果可为提高计量设备的可靠性、改善智能计量设备寿命提供支持,对实际使用过程中的运行维护有一定的参考价值。
不同模型对数据信息提取的侧重点不同,单一模型的预测效果往往受到质疑,利用组合模型对设备可靠性进行预测一度成为热点。一些研究表明,利用分解技术提取时间序列中的不同特征成分,对不同特征的数据分别采用不同的模型,有助于提高可靠性预测的精度。本文关注于基于机器学习的设备可靠性预测,旨在利用失效数据的变化规律,实现对设备可靠性的预测。本文以上述失效数据为研究对象,构造出基于ARIMA(Autoregressive Integrated Moving Average Model)模型[3]和GRU(Gate Recurrent Unit)模型[4]的设备可靠性预测方法。实验表明,本文所提出的算法取得了较好的效果,实用性也较好。
计量设备的可靠性是一个复杂的非线性动力学系统,具有显著的非线性、时变性特征[5],导致根据设备的已有数据对可靠性进行预测成为一大难题。
近年来,有一些研究者利用神经网络对时间序列进行了大量的预测研究。潘晓明等[6]利用不同的神经网络算法产生神经网络集成个体,用遗传算法动态求解集成个体的非负权重系数,进行最优组合集成建模,相对传统的简单平均集成模型具有预测精度高、稳定性好、易于操作的特点。刘磊[7]提出了一种基于RBF神经网络的预测模型。智晶等[8]提出了一种基于主成分的遗传神经网络的预测模型,其有以下2个特点:利用主成分方法选取输入变量和利用遗传算法优化神经网络参数。吴华星对基于神经网络的预测方法进行了研究,他分析了传统的BP(Back Propagation)算法,通过引入调节参数ρ解决了要同时调整算法中学习速率η和动量参数α的问题。陈嶷瑛等[9]提出了一种基于神经网络的预测模型,从他们的研究成果来看,关注点主要集中在对输入数据的处理、对神经网络的参数学习及对神经网络的集成方法方面。
但这些传统预测方法有诸多前提假设,常见的有设备的可靠性数据为平稳时间序列、可靠性数据与其影响因素之间为线性关系等。但此类数据普遍存在非线性、非平稳特征,因此这些方法在实际应用中很难达到理性的预测效果。人们对机器学习的不断深入挖掘、了解,使它在设备的可靠性数据预测方面发挥了重要的作用,它对所研究的数据没有假设限制,更不受人为先验知识的影响。
此外,国内外学者还提出通过时间序列分析方法来处理设备可靠性分析的问题,该方法是将失效数据作为时间相关序列,根据过去和现在的数据来对未来的数据进行预测。该方法不需要对故障过程做任何先前的假设就可以对数据进行分析,与传统的一些可靠性预测模型相比具有一定的优势,同时还可以发现那些被假设条件所隐藏的数据特性。如LU等[10]用时间序列方法对部件实时可靠性进行建模,以反映单一部件的实时可靠性;
JAYARAM等[11]在假设退化量分布为正态时,给出了基于性能退化数据的半似然可靠性预计方法;
金光等[12]采用Bootstrap仿真方法建立了动量轮寿命分布的模型,评价其可靠性水平,合理的时间序列模型可以对数据的发展趋势进行有效预测。目前相关分析人员已经将双指数平滑法应用在该领域,但是该方法的应用面比较狭窄,有一定的局限性。
本文提出了一种基于ARIMA和GRU的设备可靠性预测模型,该模型利用ARIMA获取数据的线性特征,利用GRU获取数据的非线性特征,通过调整合适的参数使模型的学习能力强,预测精度比较高。
2.1 建立ARIMA模型
ARIMA模型的全称为自回归移动平均模型,是统计模型(Statistic Model)中最常见的一种用来进行时间序列预测的模型。差分自回归移动平均模型ARIMA是将自回归模型(AR)、移动平均模型(MA)和差分法结合,从而得到了差分自回归移动平均模型ARIMA(p,d,q),其中d是需要对数据进行差分的阶数[13]。在该模型中,本文定义变量如表1所示。

表1 变量定义

表1 (续)
2.1.1 数据预处理
首先对无效数据进行重采样,原数据中时间不是连续的,为了更好地达到预测效果,需要进行插值处理,插值处理可以对数据中的缺失进行合理的补偿,可以对数据进行放大或者缩小。根据找到的这个规律,来对其中尚未有数据记录的点进行数值估计。本模型采用的是线性插值方法[14]。根据数据序列中需要插值的点的左右邻近2个数据点来进行数值的估计。
2.1.2 平稳性检测
ARIMA模型对时间序列的要求是平稳性,做出的数据的趋势图如图1所示,从图中可以看出,该设备的可靠性数据具有波动性。通过平稳性检验,得出p>0.05,可以判断为非平稳序列。该无效数据属于非平稳时间序列,需要运用差分法,转化成平稳时间序列,因此,首先要做的就是做时间序列的差分,直到得到一个平稳时间序列。一般情况下,差分次数不超过2次,就能达到相关要求[15]。

图1 原始数据的趋势图
进行一阶差分后的结果如图2所示,此时,p<0.05,符合平稳序列的要求,因此d取1。

图2 一阶差分结果图
2.1.3模型参数确定
建立模型必须要确定p、d、q这3个参数的值,这里主要是确定p和q的值。这里用平稳序列的自相关图(Autocorrelation Function,ACF)和偏自相关图(Partial Autocorrelation Function,PACF)来对这2个参数进行确定[16],如图3、图4所示。

图3 自相关图(ACF)

图4 偏自相关图(PACF)
自相关函数ACF描述的是时间序列观测值与其过去的观测值之间的线性相关性,计算公式如下:

式(1)中:k为滞后期数,如果k=2,则为yt和yt-2。
偏自相关函数PACF描述的是在给定中间观测值的条件下,时间序列观测值预期过去的观测值之间的线性相关性[17]。提出了中间k-1个随机变量X(t-1)、X(t-2)、…、X(t-k+1)的干扰之后X(t-k+1)对X(t)的影响程度。
p和q取值的一般规则如表2所示[18]。可靠性预测数据描述可靠性数据时间序列观测值与其过去的观测值之间的线性相关性的ACF值和PACF值,最后确定模型里的p、q参数分别为1、1。

表2 模型识别表
2.1.4 模型评估
尝试建立若干个模型,根据赤池信息量(Akaike Information Criterion,AIC)或贝叶斯信息量(Bayesian Information Criterion,BIC)来衡量模型的复杂度,从而选择出更简单的模型[19]。AIC的计算表达式为:

式(2)中:L为极大似然函数;
N为未知参数数量。
AIC同时考虑了模型的拟合程度和简单性,BIC是对AIC的改进。BIC的表达式为:
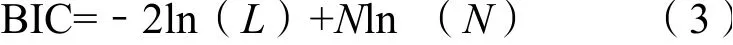
AIC和BIC的值越低越好,其值越低,模型越简单,即k、N取值越小,L取值越大,模型越好。
2.1.5 模型检验
通过对模型进行残差白噪声检验和参数性检验,来判断所建模型是否可取,如果残差序列不是白噪声序列,则返回2.1.3的步骤,重新建立模型,直至通过参数检验和模型的残差白噪声检验[20]。通过检验可得,已通过参数检验和残差白噪声检验的ARIMA模型。
2.2 建立GRU模型
传统的BP神经网络模型相邻层之间是全连接的[21],但是每层的各个节点是无连接的,样本的处理在各个时刻独立,使其不能对时间序列上的变化建模。而循环神经网络(Recurrent Neural Network,RNN)中隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出,使得循环神经网络最大的特点是具有记忆功能[22]。GRU在传统RNN的基础上加了更新门和重置门,既保留了“记忆”这个功能,又使LSTM(Long Short-Term Memory)在BPTT(Back-Propagation Through Time)的过程中避免了梯度爆炸或者消失的缺点[23]。更新门和重置门的作用在于:更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多;
重置门用于控制忽略前一时刻的状态信息的程度,重置门的值越小说明忽略得越多。GRU递归神经网络的示意图如图5所示。

图5 GRU递归神经网络
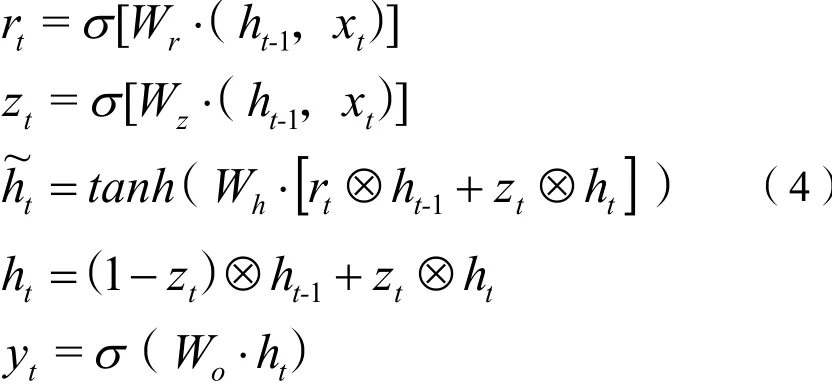
GRU的向前传播公式如下:式(4)中:()中为2个向量相连接,表示矩阵元素相乘。
从式(4)中可以看到,GRU训练需要学习的参数是Wr、Wz、Wh、Wo权重参数,这些权重参数都是拼接的,所以在学习时需要分割出来,即:

在GRU模型中,本文用的是Python的Keras库,GRU模块的激活函数为tanh,确定接收GRU输出的完全连接人工神经网络的激活函数为linear。
2.3 ARIMA-GRU组合模型构建
计量设备的可靠性因受到各种因素的影响,变化规律复杂多变,其中既含有线性趋势,又包含非线性规律,仅使用单一模型进行预测难以完全拟合。本文基于这样的思想构建组合模型,设备可靠性的历史数据首先经过ARIMA模型过滤掉序列数据中的线性趋势,那么非线性规律则包含在ARIMA模型的残差中;
其次,将残差输入GRU模型以提取其中的非线性规律;
最后,将ARIMA模型的预测结果与GRU模型的预测结果相叠加得到最终的预测结果。组合模型的流程框架如图6所示。

图6 ARIMA-GRU组合模型流程图
3.1 数据集
本文实验所用的数据集是由实验室计量设备使用过程或测试过程中记录的数据,包括设备出现故障发生次数和故障时间间隔,选取前150组数据来训练构建模型,用后面45组数据对模型进行模型测试和预测。对于数据集中的失效数据,本文通过对数据中的故障发生数和故障发生时间间隔等变量进行处理分析,分别利用ARIMA模型和GRU模型2种数据分析方案对数据的线性特征和非线性特征进行抓取,从而对计量设备的可靠性进行预测。实验中需利用数据分析技术精准刻画数据变动规律,将分析结果用图表进行可视化展示,针对所给数据,区分训练集和测试集,对比分析预测模型,并对模型进行评估。
3.2 评价指标
为了能全面表现模型的性能,本文使用平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Squared Error,RMSE)作为性能衡量指标进行效果评估,二者都是测量2个向量(预测向量和目标值向量)之间的距离的方法,且值越小,则说明模型的性能越好[24],公式如下:

式(6)(7)中:RMSE(X,h)为使用假设h在示例上测量的成本函数;
X为数据集中所有实例的所有特征值的矩阵(标记特征除外);
h为系统的预测函数,也称为一个假设;
m为在测量RMSE时所使用的数据集中实例的数量;
X(i)为数据集中第i个实例的所有特征值的向量(标签特征除外);
y(i)为标签,即为该实例的真实值。
所有的实验都是在一个搭载NVIDIA Geforce RTX 3090显卡、型号为AMD Ryzen 9 5900X处理器以及内存为64 G的服务器上进行的。在实验中,使用Python3.6开发平台、Tensorflow1.4.0学习框架和CUDA11.0来实现本文的方法。
为了防止过度拟合,本文确定每一层网络节点的舍弃率为默认值0.2,模型训练的Epoch为100,Batch Size为1,学习率设置为2×10-5,权值衰减设置为1×10-6。
3.3 对比试验
为了体现出模型预测效果的优越性,实验在相同数据集上与使用单一模型的方法进行了对比,即只使用ARIMA模型和仅使用GRU模型的方法,并将对比结果汇总,如表3所示。

表3 模型对比结果
由表3可以看出,本文提出的方法在评价指标上是有一定优势的,本文所使用的ARIMA模型和GRU模型结合的计量设备可靠性预测方法比单一模型的MAE值和RMSE值要小,例如,对比单一使用GRU模型,分别在MAE和RMSE指标上优化了32.25%和30.06%。本文方法不仅关注了线性数据,还对非线性数据进行了抓取,从而使模型对数据信息的获取更加全面,所以在设备可靠性预测的任务上表现出一定的优越性,具有较好的实用性。
此外,本文还在实验中通过数据分析技术来准确画出可靠性数据的变化走向,并将实际走向和实验预测的结果可视化展示,如图7、图8、图9所示。
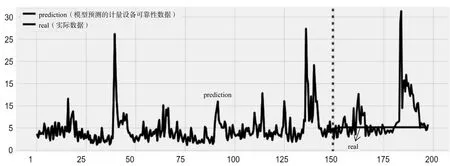
图7 ARIMA模型的预测结果

图8 GRU模型的预测结果

图9 本文方法的预测结果
由上图可以看出,预测结果均从第150组数据开始进行,ARIMA模型预测的结果都和历史的平均值比较接近,当真实值波动不是很剧烈时,ARIMA模型的预测效果会较好一些,但是通常可靠性的原始数据变化比较大,ARIMA模型的预测效果就比较差了;
相比较来看,GRU模型不是只简单看一个平均,所以预测可能会激进偏颇一点,当原始数据波动比较大时,预测的效果更好;
在同时使用ARIMA模型和GRU模型时,对原始数据的使用更加全面,同时关注了波动较大和较小的数据,所以此方法的预测效果更好。
通过实验所得的图和表均可以看出,本文提出的ARIMA和GRU的计量设备可靠性预测模型在预测结果上,效果相对来说都比较理想。单独使用ARIMA模型进行预测时,虽然模型十分简单,只需要内生变量而不需要借助其他外生变量,但是采用ARIMA模型预测时序数据,必须是稳定的,不稳定的数据是无法捕捉到规律的,对于可靠性数据预测走势情况,用ARIMA预测效果不是太好的原因是该数据是非稳定的,所以需要处理转化成平稳序列进行预测。单独使用GRU模型进行预测时,由于GRU是LSTM的一种变体,将LSTM中遗忘门与输入门合二为一为更新门,模型比LSTM模型更简单了[25],非常适合用于处理与时间序列高度相关的问题。如本文所处理的设备可靠性预测问题,通过调整神经个数、网络层数等GRU的具体参数,理论上使预测精度达到很高的水准,但是GRU网络训练时间过长,运行硬件要求高。对于时间跨度过长的数据集来说,当迭代次数达到一定数量级后,实际运行速率比较缓慢,对于实验所设计的100次迭代,2位数神经元的轻量级网络,训练时间可以达到1 h。而从实验结果可以看出,轻量级网络的实际预测精度并不超过ARIMA方法,这也说明GRU在通常网络构建和运行环境下难以展现其所具有的优势。
针对基于过往计量设备无效数据的设备可靠性预测工作中很少有使用多个模型来处理不同类型的数据,大多还只是使用单一的模型来进行数据处理和预测,本文提出了一个基于ARIMA和GRU的设备可靠性预测模型,该模型分别利用ARIMA模型和GRU模型来处理可靠性数据中的线性数据和非线性数据,从而比较全面地抓取数据信息。通过在同一数据集中执行可靠性预测任务,对比了单一使用ARIMA模型和GRU模型的方法,实验证明,本文所使用的基于ARIMA和GRU的计量设备可靠性预测模型性能比较好,更具有实用性。
在未来的工作中,将继续探索新方法和新思路,比如加入其他模型来更有针对性地处理数据,从而使原始数据的抓取更加全面丰富,进而提升模型性能。
猜你喜欢 可靠性计量神经网络 神经网络抑制无线通信干扰探究电子制作(2019年19期)2019-11-23基于神经网络的中小学生情感分析电子制作(2019年24期)2019-02-23合理使用及正确测试以提升DC/DC变换器可靠性电子制作(2018年23期)2018-12-26关注日常 计量幸福特别健康(2018年4期)2018-07-03计量自动化在线损异常中的应用消费导刊(2017年24期)2018-01-31GO-FLOW法在飞机EHA可靠性分析中的应用北京航空航天大学学报(2017年6期)2017-11-235G通信中数据传输的可靠性分析电子制作(2017年2期)2017-05-17论如何提高电子自动化控制设备的可靠性电子制作(2017年2期)2017-05-17计量与测试照明工程学报(2017年2期)2017-05-02基于神经网络的拉矫机控制模型建立重型机械(2016年1期)2016-03-01