卜钰家
(澳门大学协同创新研究院,澳门 999078)
由于房地产行业近年的迅速发展,房价也连年增长,这让很多想要买房的人感到十分头疼,所以房价的走势日益受到人们的重视。因此,通过对房价走势的研究,能够为我国的经济发展、人民生活水平的改善提供科学依据。我国每年都会发布相应的统计资料和数据,所以如何把房价走势从众多的房地产统计数据中发掘出来,就成了人们关注的焦点以及研究热点。
文中提出了一种基于遗传算法优化的BP神经网络房价预测模型,以2006—2017年国家统计局以及成都市政府发布的国民经济和社会发展概况的统计信息为基础,对2018年至2020年的成都市房价进行预测,将预测的房价与实际的房价进行分析。
BP神经网络通常有三层或三层以上结构[1],包括输入层、输出层,以及一个或多个隐含层,图1是一种三层BP神经网络结构。
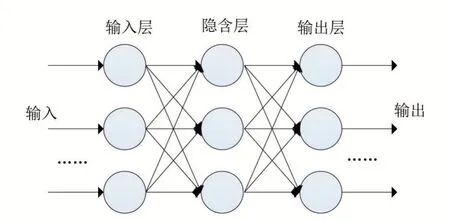
图1 三层BP神经网络结构
BP神经网络采用梯度下降法,通过反向传播不断调整网络的权值和阈值,使网络的实际输出值和期望输出值之间的均方误差最小。其训练过程包括输入信号正向传播和误差信号反向传播。这两个过程循环进行,不断计算输出误差和调整权值,直到均方误差达到设定标准[2]。
2.1 数据选择和预处理
选取实验数据十分关键,这一步骤会直接影响模型最终的准确度。能够合理准确地反映房价走势,且有针对性和代表性是选取实验数据的标准。按照这个标准,本文的研究选取七个房价相关影响因素,包括地区生产总值、年末总人口、职工平均工资、居民储蓄年末余额、开发住宅投资额、开发企业住宅竣工房屋面积、人均可支配收入。实验数据来自国家统计局2006—2020年成都市的数据以及成都市政府发布的国民经济和社会发展概况的统计信息,其数据如表1所示。

表1 2006-2020年中国房价及其相关影响因素数据
为了解决初始数据中的因素数据的数量级有明显差别的问题,也为提高模型的训练效率,选取mapminmap函数对初始数据的输入和输出进行归一化处理。Matlab内部将此变化为[ymin,ymax],其公式为
然后将数据转化到[ ]-1,1 ,在Matlab中通过以下步骤:
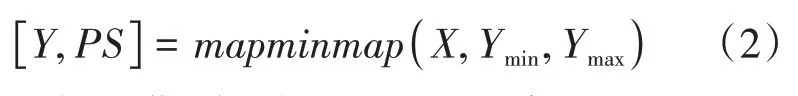
将数据X归一化到区间[Ymin,Ymax]内,Ymin和Ymax为调用mapminmap函数时设置的参数,若不设置这两个参数,会归一化到[-1,1]内。在模型训练结束后,再用mapminmap函数对输出数据进行反归一化处理,将其还原。
2.2 建立训练模型
对数据进行预处理后,接下来就是确认模型的输入和输出。本文建立三层结构的BP神经网络。将前两年的影响因素作为输入值,用第三年的房价作为输出值,这样可以得到13组样本数据。模型的输入层和输出层的神经元数分别为14和1。将样本数据分为两个部分:训练样本为2008—2017年的9组数据,测试样本为2018—2020年的3组数据。
2.2.1 确定隐含层节点数
采用试凑法选取网络的隐含层节点。用经验公式得到一个估计值作为初始值,再用试凑法来确定最佳节点数。常用的经验公式为[3]
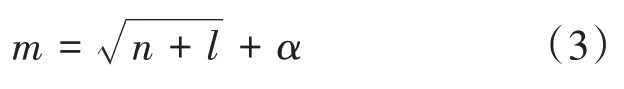
其中,m为隐含层节点数;
n为输入层节点数;
l为输出层节点数;
α为1~10之间的整数。本文设定输入层神经元个数为14,输出层神经元个数为1,经过公式得出隐含层神经元个数大致5~15之间,最后确定隐含层神经元个数为6。制定训练次数为1000,不同的隐含层节点数在训练后得到的均方误差如表2所示。
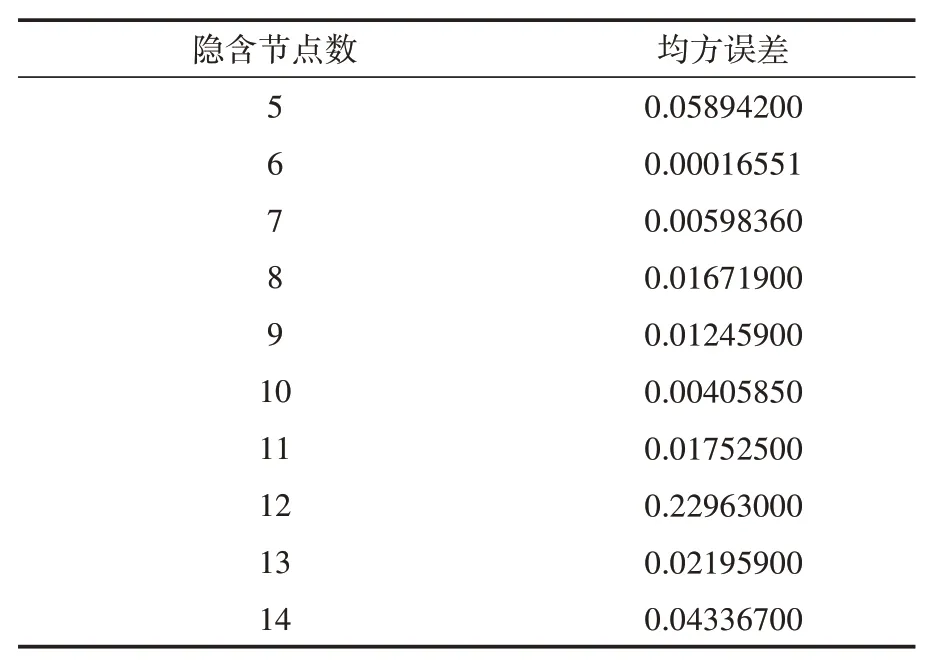
表2 不同隐含层节点网络训练后的均方误差
2.2.2确定转移函数
本文建立的BP神经网络中,隐含层的传递函数为tansig函数,输出层的传递函数为purelin函数[4]。
2.3 BP神经网络模型训练和仿真结果
基于Matlab2018b中的神经网络工具箱构建BP神经网络模型,将2018—2020年的3组数据作为测试样本。从表3可以看出,对2018—2020年房价预测的误差情况。
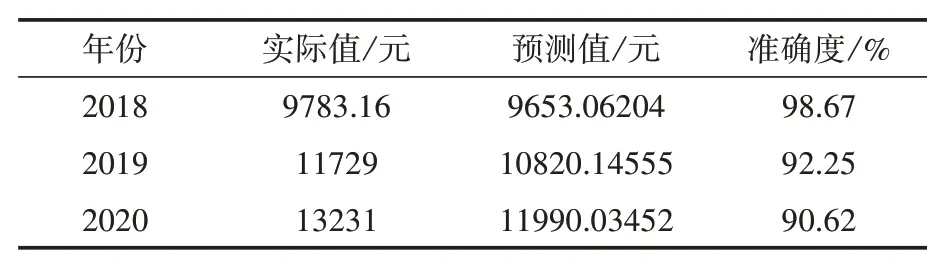
表3 BP神经网络模型的房价预测结果
遗传算法(Genetic Algorithm,GA)是模拟生物进化的一种有很好全局搜索能力的算法。通过适应度函数的过滤以及类似自然界中的选择、交叉、变异等操作产生新的种群,这样循环来提高群体中个体的适应度,直到满足一定条件。BP神经网络容易陷入局部最优[5]。因此,用遗传算法改进BP神经网络(以下简称GA-BP神经网络),可以增强模型全局搜索的能力。
3.1 使用遗传算法优化BP神经网络
遗传算法可以优化BP神经网络的权值和阈值[6]。为实现遗传算法优化BP神经网络,需要如下操作:
(1)种群的初始化
个体由各层权值和阈值组成。本文用实数编码的方式对个体进行编码[7]。编码长度:
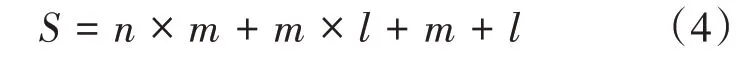
其中,m为隐含层节点数;
n为输入层节点数;
l为输出层节点数。遗传算法的全局搜索能力容易因为种群数量的改变而改变,所以要针对特定问题来确定种群的规模。此次实验初始种群的规模为40。
(2)选择适应度函数
将神经网络误差平方和的倒数作为适应度函数。BP神经网络预测误差越小,对应的适应度函数就越大,适应性越好。

其中,SE为神经网络的预测输出与期望输出之间的误差平方和。
(3)个体选择
选择normGeomSelect方法对种群中的个体进行选择,概率设置为0.6。
(4)交叉与变异操作
交叉运算是遗传算法中产生新个体的方法之一,通过使用交叉算子从全局的角度改善个体编码结构[8]。变异算子具有局部搜索能力,它进一步扩展了种群的多样性。变异操作是对群体中的个体串的某些基因座上的基因值作变动,从而产生新个体,使遗传算法具有局部的随机搜索能力[9]。
(5)循环操作
循环步骤(2)至步骤(4),直到满足误差要求或达到最大训练次数为止[10]。
3.2 GA-BP神经网络模型的训练结果
将遗传算法优化后得到的权值和阈值带入原模型,再次训练,对测试样本进行预测。比较预测得到的房价与真实房价,从表4可以看出,对2018—2020年房价预测的误差情况。
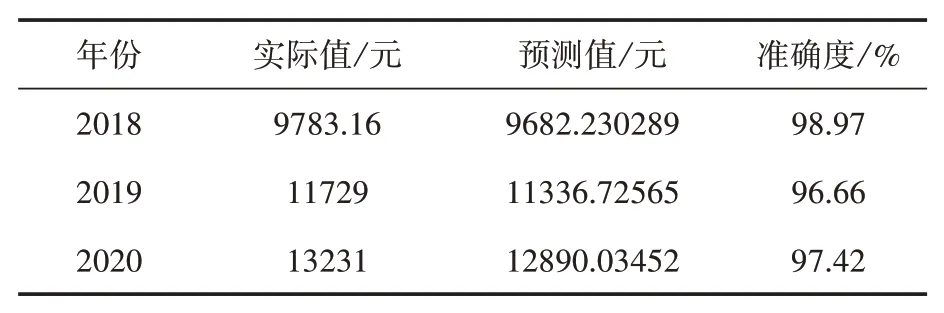
表4 GA-BP神经网络模型的房价预测结果
将BP神经网络模型和GA-BP神经网络模型所得到的预测值进行比较,如表5所示。由表5可得出,GA-BP神经模型平均相对误差要低于BP神经模型,由此能够看出经过遗传算法优化后的BP神经模型能够更好地预测出房价。
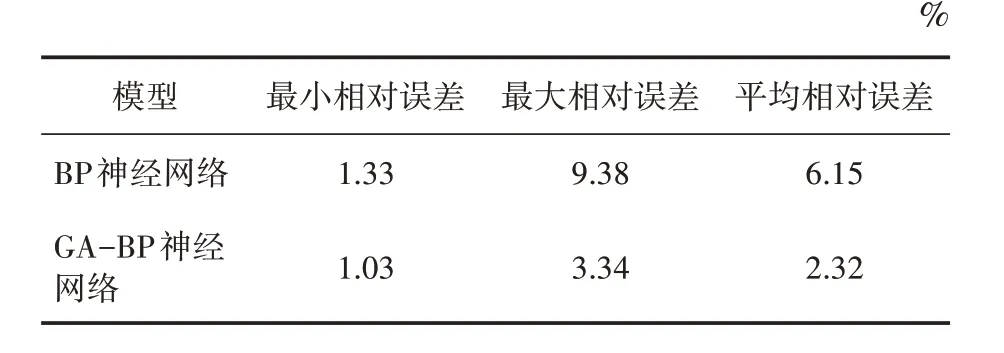
表5 两种模型的房价预测误差统计
在设定的目标误差为0.001,最大训练步数为10000次的情况下,BP神经网络的训练误差曲线如图2所示,GA-BP神经网络的训练误差曲线如图3所示。BP神经网络在第6817步时收敛,GA-BP模型在第3179步时收敛,可得GABP神经网络的收敛速度快于BP神经网络的收敛速度。结合两个模型的误差曲线和平均相对误差,可知GA-BP神经网络加快了网络的收敛速度,提高了模型预测精度。
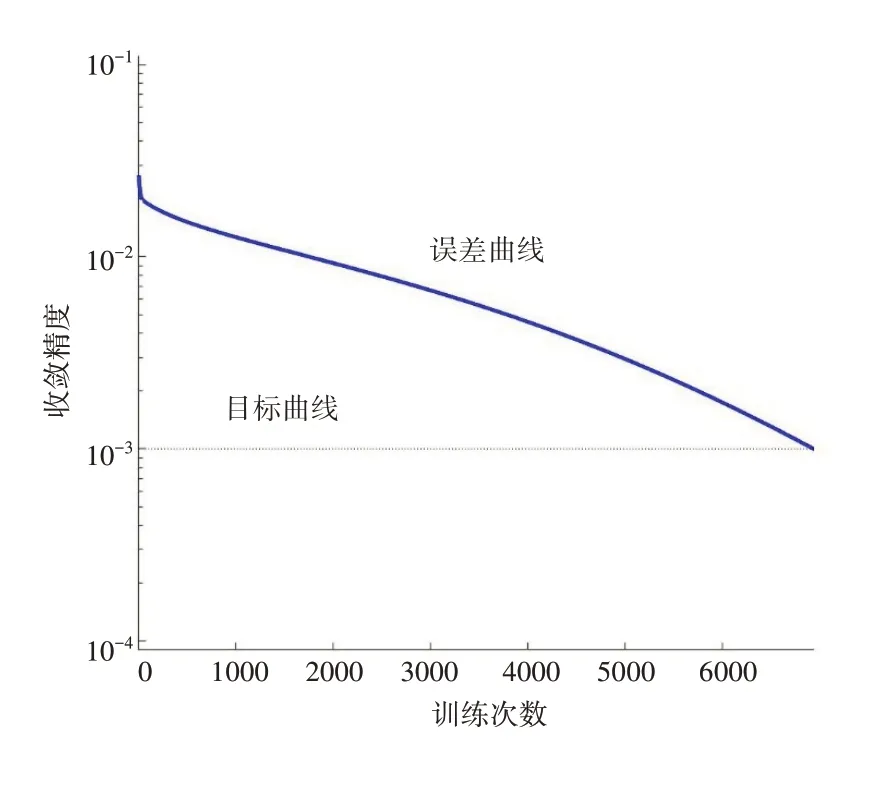
图2 BP神经网络训练误差曲线
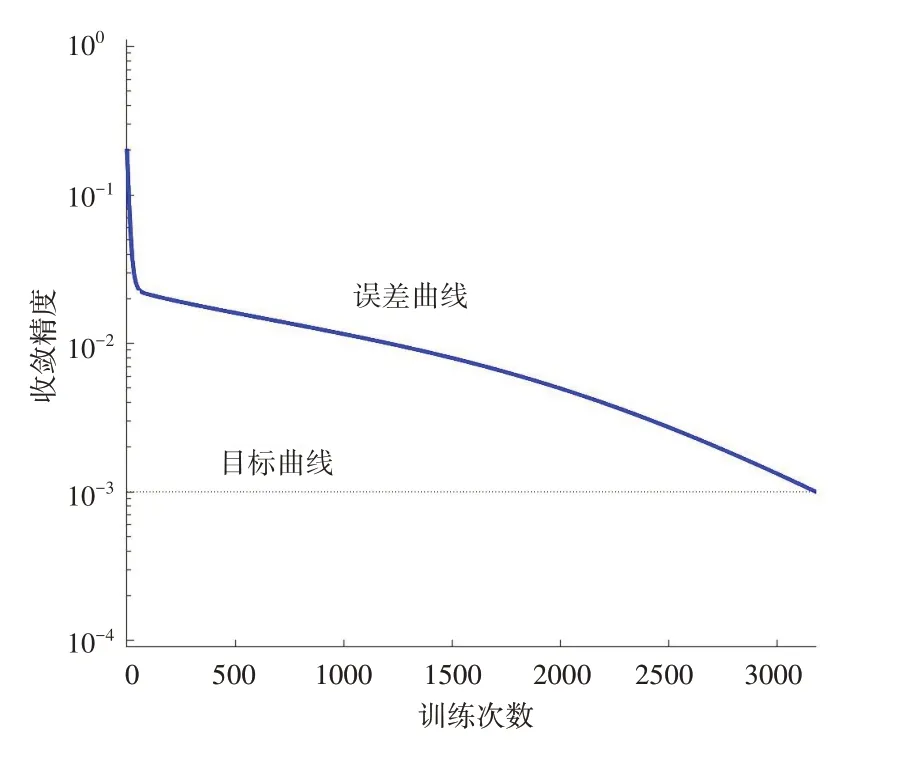
图3 GA-BP神经网络训练误差曲线
BP神经网络容易陷入局部最优,而遗传算法有良好的全局搜索能力,提升BP神经网络的收敛速度和预测精度。选取2006—2017年成都市房价及其相关影响因素作为训练数据,用BP神经网络和GA-BP神经网络这两种模型来预测2018—2020年的房价。分析得知,GA-BP神经网络在预测精度和收敛速度方面都优于BP神经网络,可以更好地预测房价。但是影响房价的因素是多元的,并且分析影响房价的所有因素是不现实的。一些突发事件会让房价突然上涨而导致预测值和真实值偏差较大,所以在预测房价的时候还需要考虑多方因素。
猜你喜欢 遗传算法房价神经网络 基于递归模糊神经网络的风电平滑控制策略现代电力(2022年2期)2022-05-23盛松成:什么才是中国房价持续上涨的真正原因?房地产导刊(2021年8期)2021-10-13基于遗传算法的高精度事故重建与损伤分析汽车工程(2021年12期)2021-03-08两大手段!深圳土地“扩权”定了,房价还会再涨?房地产导刊(2020年11期)2020-12-28神经网络抑制无线通信干扰探究电子制作(2019年19期)2019-11-23防范未然 “稳房价”更要“稳房租”中华建设(2019年8期)2019-09-25基于神经网络的中小学生情感分析电子制作(2019年24期)2019-02-23基于遗传算法的智能交通灯控制研究电子制作(2019年24期)2019-02-23一种基于遗传算法的聚类分析方法在DNA序列比较中的应用中央民族大学学报(自然科学版)(2017年1期)2017-06-112016房价“涨”声响起商业文化(2016年3期)2016-04-19