李笑萌,张亚飞,郭军军,高盛祥,余正涛
(昆明理工大学信息工程与自动化学院,云南省人工智能重点实验室,云南 昆明 650500)
跨语言摘要任务旨在为给定的一篇源语言文本生成另一种语言的摘要.跨语言摘要的传统方法是将源语言文本翻译到目标语言,然后对翻译后的文本进行摘要[1-2];
或者先对源语言文本进行摘要,然后将源语言摘要翻译到目标语言[3-5].然而,目前机器翻译(MT)性能仍不能达到预期效果,存在结果错误传播的问题,尤其针对越南语等低资源语言,错误传播的问题更为显著.
近年来,跨语言摘要任务的研究方法主要是基于端到端的跨语言摘要方法.Zhu等[6]基于端到端的模型,利用大规模跨语言摘要数据来实现跨语言摘要性能的提升,这也是第一个使用大规模的平行语料训练端到端跨语言摘要模型的方法,但是目前缺乏大规模高质量的跨语言摘要数据集.为了在少量的标注数据下使得端到端的跨语言摘要模型获得更好的性能:Yana等[7]基于训练后的MT模型和单语摘要(MS)模型,将两者作为教师模型来教授跨语言摘要的学生模型;
后来,Duan等[8]将Transformer模型作为MS教师模型和学生模型的主干,进一步提升摘要的质量.但是这种教师-学生模型只能把有限的知识传递给学生模型.因此,为了使模型具备更好的跨语言学习的能力,基于预训练语言模型的跨语言摘要方法被提出,该方法通过预训练语言模型,使模型提前具备跨语言学习的能力,从而使模型获得更好的性能.Xu等[9]提出了一种混合语言预训练模型,通过掩码语言模型(MLM)、MS等进行预训练,为了提高模型跨语言学习的能力,预先训练的模型基于MT模型等提前从大量MT标注数据中学习语言知识.以上跨语言摘要任务主要是在汉英等富资源情况下进行,对于越南语等低资源语言情况并不适用.
目前,也有少量的研究是基于知识增强的方法来获得较好的低资源跨语言摘要效果.Li等[10]提出自动摘要的正确性问题,通过联合学习摘要生成和文本隐含知识,提出了隐含感知解码器,通过用隐含信息丰富的编码器和解码器,来提高摘要的准确性.该研究结果表明:通过文本隐含知识增强模型的表征可提高摘要的准确性,这也说明将基于知识的学习融入摘要模型对于摘要模型性能的提升非常重要.传统的基于知识增强的跨语言摘要方法是通过构建双语词典,将作为输入的源语言文本和目标语言的参考摘要通过对齐的双语词典映射至同一语义空间,实现跨语言摘要.但是对于越南语等低资源来讲,获取对齐的双语词典数据十分困难,较难实现跨语言语义对齐,而汉越概率映射对是一种针对语料库级别的全局知识,能够尽可能地反映双语之间的对应关系.基于数据驱动的端到端的跨语言摘要模型在低资源情况下由于没有先验知识指导,不能有效关注到源语言文本中的核心内容,导致生成的摘要出现内容偏差的问题,而关键词包含了源文的重要内容,是对源文的有效增强,因此从源语言文本中挖掘关键词信息并映射至目标语言生成相关的上下文,对于生成简洁、语义正确的跨语言摘要尤为重要.2017年,See等[11]提出指针生成器网络,实现了从源文本复制单词.受See等[11]的启发,本文认为通过指针生成器网络实现关键词的概率映射作为先验知识,可以增强模型跨语言表征的能力,指导摘要的生成.因此,针对标注数据稀缺导致的跨语言对齐困难等问题,本文提出了关键词概率映射,不仅关注了文本中的重要信息,且在一定程度上解决了跨语言对齐困难的问题.总体来说,本文的主要贡献包括以下两个方面:
1) 提出了融合关键词概率映射的汉越低资源跨语言摘要方法(low resource cross-language summarization of Chinese-Vietnamese combined with keyword probability mapping,C-Vcls),通过获取关键词的概率映射信息来改善汉越低资源跨语言摘要较难实现跨语言语义对齐,摘要质量差的问题;
2) 在构建的10万汉越低资源跨语言摘要数据集上进行对比实验,结果证明本文所提模型在汉越低资源跨语言摘要任务上的有效性和优越性.
本文C-Vcls模型基于Transformer框架,由融合关键词概率映射的文本表征和融合关键词概率映射的解码端构成,模型框架如图1所示.首先,获取源语言文本的关键词G,与源语言文本X的隐状态表征Z通过编解码注意力机制获取第s个关键词与源语言文本的联合表征∂s,查询得到每一个关键词对应汉越概率映射对中的源语言词,通过注意力机制获得第s个关键词(词向量表示为ws)对应到目标语言词(词向量表示为w)的概率P(ωs⟹ω),最后通过指针网络,结合解码端生成的目标词的概率大小PN(ω)获得最后的分布P(ω).
1.1 融合关键词概率映射的文本表征
给定一组跨语言摘要数据集D:D={X,Y},其中X为源语言文本输入序列,即X={x1,x2,…,xn},Y为目标语言参考摘要输入序列,即Y={y1,y2,…,ym}.n,m跟随源序列长度变化,n>m.
编码端输入的源语言文本通过编码器得到输出的隐状态表征Z,如式(1)所示.
Z=[z1,z2,…,zl,…,zn].
(1)
本文使用的关键词抽取方法为关键词提取算法TextRank[12].基于此算法,对每篇源语言文本提取q个最重要的关键词,即关键词集合G由式(2)所示:
G={g1,g2,…,gs,…,gq}=
TextRank(x1,x2,…,xn).
(2)
然后,通过编解码注意力机制对关键词和源语言文本进行联合表征,构建关键词到源语言文本的注意力,计算第s个关键词gs对于源语言文本的注意力得分,如式(3)所示.
(3)
为了对关键词信息进行跨语言对齐,映射至目标语言,本文采用汉越概率映射对进行实现.汉越概率映射对的构建在本文构建的汉越跨语言摘要数据集D上进行.设C={c1,c2,…,ci,…,cj}为D中源语言词的集合,V={v1,v2,…,vk,…,vr}为D中相对应的目标语言的映射候选词的集合,j,r表示集合的大小.如图1中概率映射对构建模块可知,在对应关系中,可以映射为源语言词“我”的映射候选词有“Chúng”“ti”,其中“我→ti”表示一个映射对,利用统计的思想,即“我”映射为“Chúng”的概率为1/3,映射为“ti”的概率为2/3.为了实现这一功能,本文利用Dyer等[13]提出的快速对齐方法和统计的思想,通过快速对齐方法得到每一个源语言词ci映射为目标语言vk的概率为:
(4)
其中,ci→vk表示一个映射对,‖{ci|ci→vk}‖表示数据集D中源语言集合中所有满足映射关系ci→vk的词ci的个数,‖{vk|ci→vk}‖表示满足映射关系ci→vk的映射候选词vk的个数,PMP表示汉越概率映射对在数据集D中源语言词可以映射为满足映射关系的映射候选词的概率.
为了将关键词映射到目标语言,本文使用了编解码注意力机制查询得到每一个关键词对应汉越映射对中的源语言词,进而得到该关键词的映射候选词.如图1所示,为了将关键词“我”映射至目标语言,首先查询得到“我”在汉越概率映射对中对应的源语言词的位置,进而得到对应的映射候选词“Chúng”“ti”等,然后利用编解码注意力机制,构建关键词到映射候选词的注意力,即计算出每一个关键词对应其汉越映射概率对的映射概率,取其映射概率最大的映射候选词“ti”作为目标语言关键词.具体如公式(5)所示.

图1 融合关键词概率映射的汉越低资源跨语言摘要方法框架Fig.1 Low resource cross-language summarization of Chinese-Vietnamese combined with Kp-mapping
(5)
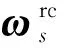
1.2 融合关键词概率映射信息的解码端
在得到关键词的概率映射信息后,融合模块的功能是将关键词概率映射信息融合到跨语言摘要生成过程中,指导摘要的生成.本文利用See等[11]提出的指针网络,通过生成概率Pgen来确定最后生成的摘要词汇分布.
使用O作为解码器在时刻t的隐状态,计算时刻t的生成概率Pgen,Pgen∈(0,1),如式(6)所示.
Pgen=δ(W2(W1O+b1)+b2),
(6)
其中,W1∈Rdmodel×dmodel、W2∈R1×dmodel是学习矩阵,b1∈Rdmodel、b2∈R是偏置向量,dmodel表示此时隐状态的维度,δ是sigmoid函数.本文中,Pgen被用作一个软开关,用于选择从解码端生成一个单词,或者选择从关键词中复制一个单词.那么,生成一个单词的概率P(ω)如式(7)所示.
P(ω)=Pgen∑s∂sP(ωs⟹ω)+
(1-Pgen)PN(ω),
(7)
其中,P(ωs⟹ω)表示关键词ωs映射到词ω的概率大小,PN(ω)表示本模型的解码端生成的词ω的概率大小,P(ω)是通过生成概率Pgen决定的最终生成摘要的词汇分布.
2.1 实验数据
本文数据来自互联网爬取,基于Zhu等[6]提出的往返翻译的策略,获得了质量较高的10万汉越、汉英跨语言摘要数据集(https:∥github.com/Lxmllx/C-Vcls-dataset/tree/master),其中有效词数为数据集文本分词去重后的剩余词数.表1中列出了本文数据集的统计信息.分词处理过程中,汉语使用结巴分词,越南语使用Vu等[14]提出的VnCoreNLP进行分词,英语采用其本身的词级结构.
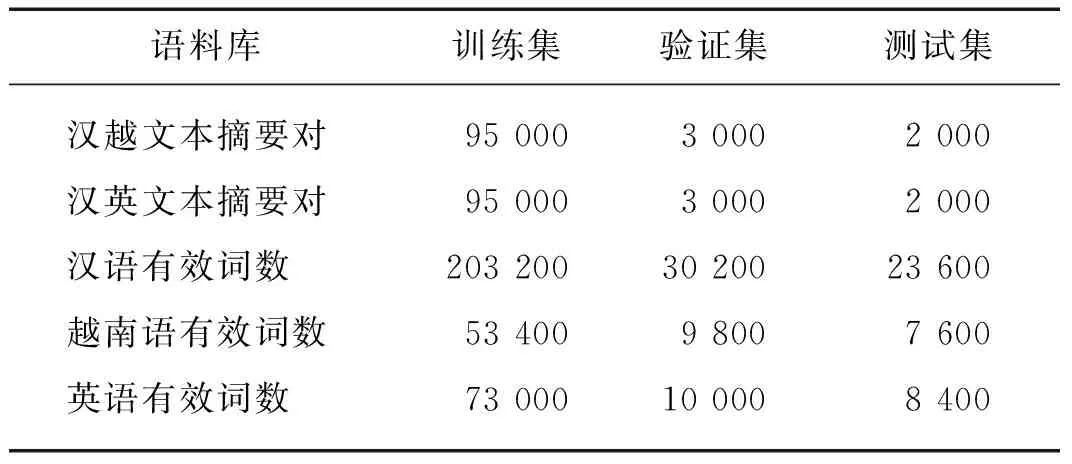
表1 数据集统计结果
2.2 评价指标
本文利用自动摘要中常用的ROUGE(recall-oriented understudy for gisting evaluation)值作为评价指标[15],它通过比较候选摘要与参考摘要中共现的n元词组(n-gram)来评价候选摘要的质量,其计算方法为:
ROUGE-N=
(8)
其中,n-gram表示n元词组,AR表示标准的参考摘要,As表示生成摘要句,N(n-gram)表示参考摘要中n元词组的个数,Nmatch(n-gram)表示生成摘要句与参考摘要句共同包含的n元词组的个数.根据n-gram的不同,本文采用ROUGE-1(一元组、RG-1),ROUGE-2(二元组、RG-2),ROUGE-L(最长子序列、RG-L)来评价参考摘要的好坏.
2.3 实验模型参数设置
本文所有实验均基于Transformer架构,采用Adam优化器,其中,β1=0.9,β2=0.998,ε=1×10-9.在训练过程中使用的标签平滑率els=0.1.在验证时使用波束大小为4且长度罚分α=0.6的波束搜索.本文采用的学习率lr=0.1,批次大小设为2 048,dropout为0.1,编码器和解码器层数、模型隐层大小、前馈隐层大小和头数分别为6,1 024,2 048和8.本文设置编解码器词表大小为:汉语10万,英语和越南语均为1万,未登录词使用
2.4 基准模型
本文选择TETran、TLTran、NCLS模型作为基准模型,所有基准模型的训练集、验证集和测试集划分均与本文模型相同.
1) TETran模型和TLTran模型为传统的跨语言摘要模型,其中TETran模型表示先利用MT模型将源语言文本翻译到目标语言,然后使用LexRank[16]模型对翻译后的源文档进行摘要.TLTran模型表示先利用MS模型对源语言文本进行摘要,然后利用翻译模型将生成的源语言摘要翻译至目标语言.
2) NCLS[6]模型是一种基于Transformer的端到端的跨语言摘要模型.
3) C-Vcls模型是本文实现的基于Transformer的序列到序列模型.此模型引入关键词的概率映射信息作为先验知识.
2.5 实验结果分析
2.5.1 实验结果
为了证明本文融合关键词概率映射方法在汉越低资源跨语言摘要任务上的优势,将本文模型与现有基准模型在汉越跨语言摘要数据集上进行实验对比,表2给出了本文模型与基准模型在汉越跨语言摘要测试集上的RG-1,RG-2和RG-L的对比结果.
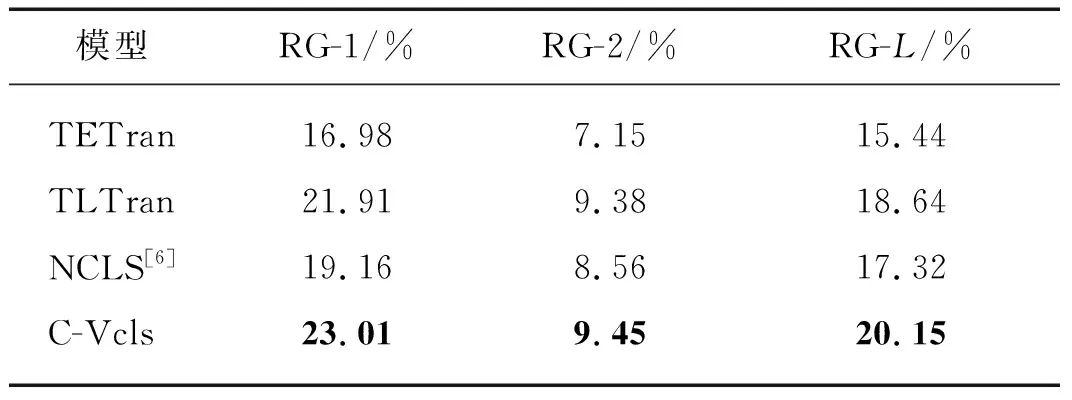
表2 汉越跨语言摘要模型的实验结果对比
由表2可知:TLTran优于TETran,说明先翻译后摘要的方法更容易受MT性能的影响,发生错误传播.C-Vcls模型与传统的TLTran、TETran模型相比,在RG-1,RG-2和RG-L上分别取得了1.10,0.07,1.51和6.03,2.30,4.71个百分点的提升,这也说明了不仅关键词概率映射的策略可以有效缓解越南语MT性能不佳引起的摘要质量差的问题,通过获得源文关键词的联合表征还可以获得更好的上下文表示,使生成的摘要更精准.另外,C-Vcls模型与端到端的NCLS模型相比,在RG-1,RG-2和RG-L上取得了3.85,0.89,2.83个百分点的提升,相较于需要大规模语料的端到端的NCLS模型,本文构建源文关键词的联合表征并融入关键词的概率映射,通过先验知识增强模型的跨语言表征能力,降低了模型对语料规模的要求,从而取得了更优的性能.因此,通过以上分析,可以得出明确结论:本文提出的关键词概率映射方法是一种有效的方法,可以有效提高端到端模型的性能.
2.5.2 融合关键词概率映射方法的有效性分析
在2.5.1节中,融合关键词概率映射方法能有效提高端到端模型的性能.为了进一步证明本文融合关键词概率映射模块在汉越低资源跨语言摘要任务上的合理性,本文设置了多组实验进行验证.
1) 关键词融入的有效性
表3中给出了关键词个数q不同时,C-Vcls模型在汉越跨语言摘要测试集上的RG-1,RG-2,RG-L的比对结果.
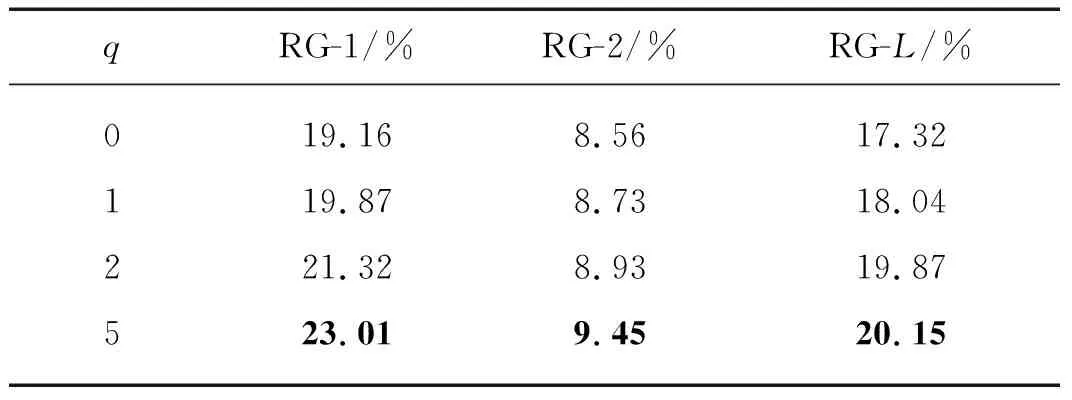
表3 关键词个数对C-Vcls模型的影响
分析表3可知,q=5时,模型取得了更优的性能.随着q从0增加到5,C-Vcls模型在汉越跨语言摘要测试集上指标RG-1、RG-2和RG-L不断增加.与q=0相比,q=5时在指标RG-1、RG-2和RG-L上分别获得了3.85、0.89、2.83个百分点的性能提升.原因可能是随着关键词个数的增多,获得的文本关键信息越多,对摘要的指导性越强,获得的摘要越可靠.综上,表明了关键词等先验知识对摘要模型的指导可以有效提升低资源摘要模型的性能.
2) 概率映射策略的有效性
为验证概率映射策略的有效性,本文在概率映射词典的大小上进行相关实验.根据词频设置概率映射词典大小为25 087,36 368,39 311,42 399,表4中给出了本文模型在汉越跨语言摘要数据集上的RG-1、RG-2、RG-L的比对结果,其中覆盖率为概率映射词典相对于关键词词数的占比(此处由TextRank得到的关键词未进行去重,故覆盖率的分母不一样).
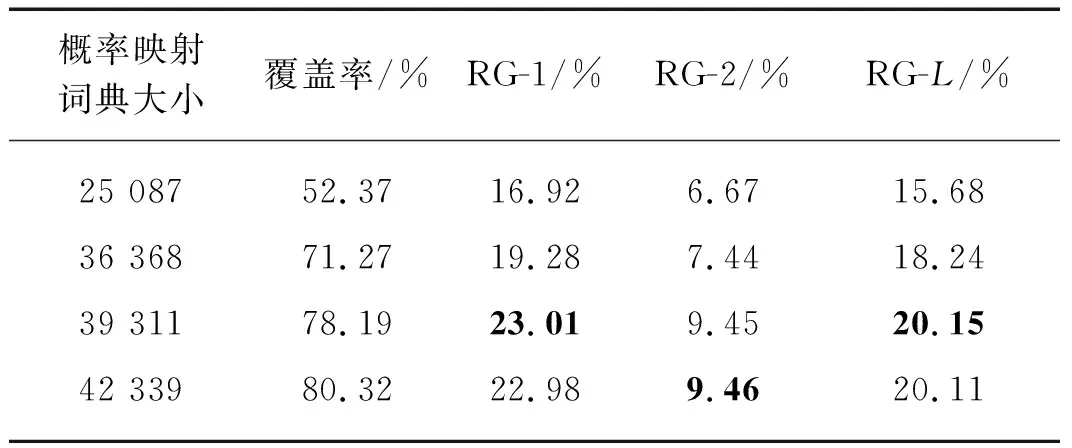
表4 概率映射词典对模型的影响
分析表4可知,概率映射词典大小为39 311是性能最好的,在指标RG-1、RG-2和RG-L上,相较概率映射词典大小为25 087,36 368,42 339时分别有6.09,2.27,4.46,3.73,2.01,1.91;
0.03,-0.01,0.04个百分点的提升.概率映射词典大小为25 087时的汉越跨语言摘要效果较差,主要原因可能是覆盖率仅有52.37%,此时词典的噪声较大,覆盖率较低,在进行映射时不能对关键词进行有效映射,导致部分关键词不起作用,相对于其它模型的结果(表2),甚至会降低摘要的效果;
但是在概率映射词典为39 311和42 339时,摘要效果相对于其它模型的结果(表2),仍有提升,但是两者相差不大,这是由于最终生成摘要的单词分布由概率映射词典、翻译概率、神经网络模型生成单词的分布共同决定,可能产生的不确定性较大.综上,说明了概率映射词典这一策略在汉越跨语言摘要任务上的有效性,但是概率映射词典对于关键词的覆盖率在一定程度上影响了模型的性能.
3) 概率映射以及指针网络对于C-Vcls模型的有效性
为验证本文所结合的概率映射以及指针网络策略的作用,本文在汉越低资源跨语言摘要数据集上进行相关实验.其中,C-Vcls-MP模型是在C-Vcls模型的基础上减少概率映射模块,C-Vcls-PN模型是在C-Vcls模型的基础上减少指针网络模块而选择直接拼接Pgen∑s∂sp(ws⟹w)与(1-Pgen)pN(w)的方式进行关键词的融合.
分析表5可知,C-Vcls模型取得了更好的效果.C-Vcls模型较C-Vcls-MP模型在指标RG-1、RG-2和RG-L上取得了4.77,4.52和3.21个百分点的提升,该结果表明当关键词不进行概率映射时,摘要结果下降最为严重且摘要性能低于NCLS模型,可能是由于关键词不进行映射时,会给模型引入更多的噪声,说明关键词概率映射模块在模型中起着至关重要的作用,能够建模关键词映射到目标语言作为先验知识指导跨语言摘要的生成.而C-Vcls-PN模型相对于C-Vcls模型,在指标RG-1、RG-2和RG-L上的性能分别下降了2.45,2.74和2.26个百分点;
但是相较NCLS模型,RG-L指标上仍然取得了0.57个百分点的增幅,这也说明,尽管融合的方式不同,但是融入关键词概率映射信息到端到端的模型中确实对模型性能的提升是有帮助的,而且指针网络的融合方式优于直接拼接的融合方式.综合以上分析,本文所提概率映射以及指针网络进行融合的方式对模型的性能提升是有益的.
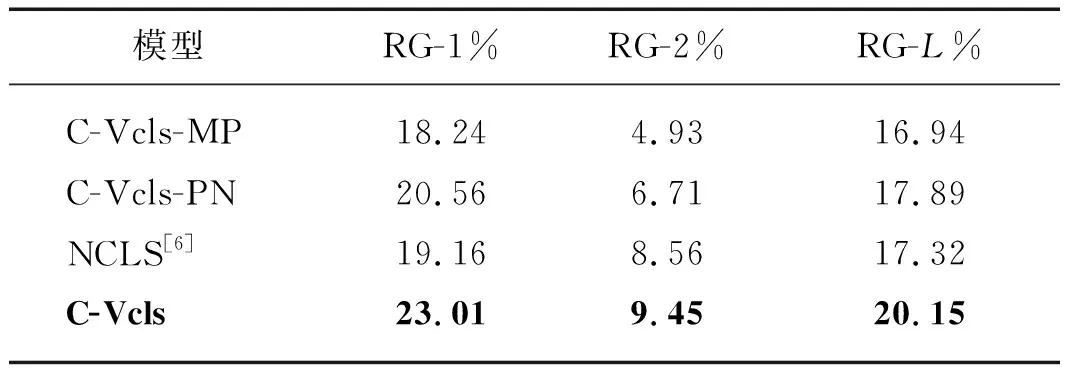
表5 概率映射、指针网络对C-Vcls模型的影响
4) C-Vcls模型与基准模型在汉英跨语言摘要测试集上的对比
为了验证本文所提模型的泛化性,本文在汉英跨语言摘要数据集上进行实验.表6给出了本文模型与基准模型在汉英跨语言摘要数据集上的RG-1、RG-2和RG-L的比对结果.
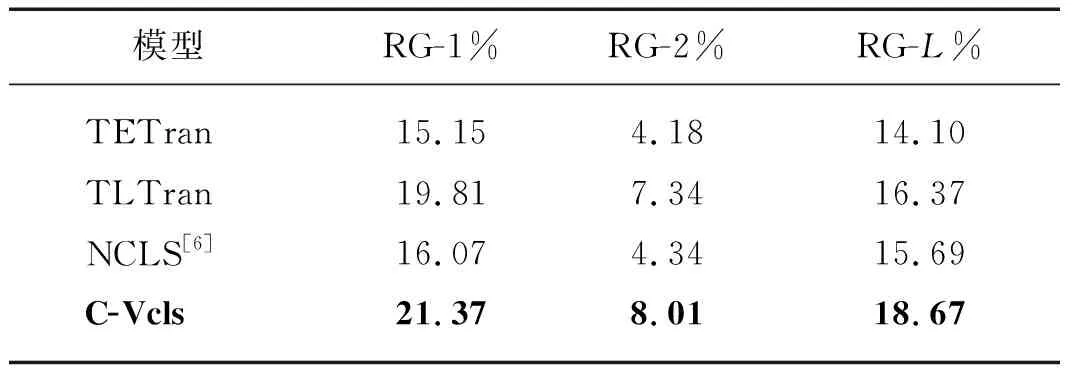
表6 汉英跨语言摘要模型的实验结果对比
分析表6可知,本文模型的指标均优于基准模型.C-Vcls模型较TLTran模型和TETran模型在指标RG-1、RG-2、RG-L上分别有1.56,0.67,2.30和6.22,3.83,4.57个百分点的提升;
较NCLS模型有5.30,3.67,2.98个百分点的提升.根据表2和6可以看出,同样数量级的数据在同样的基准模型上,不同的数据集取得的结果有所差异,且在汉英跨语言摘要数据集上的实验结果低于汉越跨语言摘要数据集.主要原因是因为虽然越南语和英文构造的词典均为1万,但根据越南语和英文文本构造特点及本文数据集的有效词数来看,越南语词典对于测试集文本的覆盖率高于英文词典对于测试集文本的覆盖率,即汉越跨语言摘要的实验结果没有大量未登录词
2.6 实例分析
为了进一步验证算法的有效性,本文列举了不同模型的摘要结果.具体如表7所示,源语言文本与标准摘要都来自汉越跨语言摘要数据集.本文列举出了所有基准模型的输出结果作为对比,为了便于理解,本文给出了对应汉语的翻译结果.
分析表7可知,源语言文本主要讲述19名前往张家口的驴友被困海坨山,其中15名驴友失去联系的事实.由于模型限制,传统模型TETran模型表达出了19名来自河北石家庄的朋友,但是并没有表述出15名前往张家口的朋友在河北失去联系的关键信息;
TLTran模型表现相对较好,但是仍然没有表输出“张家口”的关键事实.而对于端到端的C-Vcls模型和NCLS模型均能表达出“15名驴友”的主要信息,但是NCLS模型,并没有体现出其“失去联系”的关键信息,且内容过于冗杂,而本文提出的融合关键词概率映射的策略,获取源文中的关键词“北京”“失去”“联系”等映射至目标语言,通过有关键词概率映射信息等具有引导性信息的融入增强了模型的跨语言表征能力,提高了摘要的信息覆盖度以及事实性,生成质量更高的文本摘要.

表7 不同模型生成摘要样例
针对汉越低资源跨语言摘要,本文在Transformer框架下,提出关键词概率映射方法.通过实验证明,在低资源情况下,通过获取源语言文本的关键词信息映射至目标语言指导摘要生成的方式,对汉越低资源跨语言摘要任务存在一定的提升,通过实验也可以证明,利用关键词概率映射信息可以为跨语言摘要模型提供更丰富的指导信息,也证明本文提出的方法对低资源跨语言摘要任务可能是更加有效的.多模态等多源信息是对文本内容的高度概括,可以很好的对文本内容进行信息补充.因此,如何利用多模态信息对跨语言摘要进行指导是下一步研究的重点.
猜你喜欢 目标语言词典概率 概率统计中的决策问题中学生数理化(高中版.高考数学)(2022年3期)2022-04-26概率统计解答题易错点透视中学生数理化(高中版.高考数学)(2022年3期)2022-04-26概率与统计(1)中学生数理化·高三版(2021年3期)2021-05-14概率与统计(2)中学生数理化·高三版(2021年3期)2021-05-14米兰·昆德拉的A-Z词典(节选)文苑(2019年24期)2020-01-06米沃什词典文苑(2019年24期)2020-01-06中国大学生对越南语虚词的误用教育教学论坛(2019年18期)2019-06-17教材插图在英语课堂阅读教学中的运用及实例探讨文理导航(2017年25期)2017-09-07“函数及图象”错解词典中学生数理化·八年级数学人教版(2016年4期)2016-08-23漫画词典中关村(2014年5期)2014-05-15