刘 洋
(池州职业技术学院教育系,安徽 池州 247000)
显著目标检测旨在检测图像或视频中最吸引人的区域,以模仿人类视觉的注意力机制[1]。全监督显著目标检测模型依靠有效设计的模块取得了良好的检测性能[2-3]。然而,这些方法严重依赖于精确的像素级别标注数据集,需要耗费大量的人力才能获取。因此,稀疏标记方法[4-7]在近年来吸引了越来越多的关注,其目的是在时间开销和模型性能之间取得平衡。一些方法[8-9]尝试使用图像级标签来检测显著物体。一些方法使用噪声标签训练网络,这些噪声标签通常由其他的显著目标检测方法生成[10]。涂鸦标注[11]是基于降低标记时间成本而提出的,与之前的方法相比,它可以提供局部的真值标签,且作者称他们可以在1~2 s内完成对图像的标注,但对于未经训练的标注人员来说很难做到这一点。该方法尝试提出一种基于点监督的显著性检测方法,与涂鸦标注相比,该方法能使用更少的标注时间来实现可接受的性能。如图1所示,该方法是第一个尝试使用点监督来完成显著目标检测的方法。
该方法提出了一种基于点监督的显著性检测方法,使用了与涂鸦标注相比耗时更少的标注方法,但取得了相似的性能表现,如图1所示。点监督与无监督和图像级别的监督相比,可以直接提供相对准确的位置信息。其次,与其他手工标注方法相比,点监督是最省时的标注方法。此外,当前的弱监督显著性检测模型往往只关注在相应场景中必须关注的目标,而忽略了应该忽略的目标。原因是由于弱监督标签的稀疏性,使得监督信号只能覆盖图像的一小部分,只允许模型了解哪些目标必须高亮显示,但缺乏信息来指导模型应该忽略哪些目标。基于这一观察,本文提出了非显著性抑制方法来明确过滤掉非显著但被检测到的目标。

(a)原始图像
1.1 自适应洪水填充
根据弱监督密集预测任务的常规做法,首先需要制作伪标签,然后使用它们来训练网络。由于稀疏标签仅覆盖目标区域的一小部分,这限制了模型接收目标结构的能力,Feng,et al[12]人利用边缘检测器生成边缘以监督训练过程,不同的是,该方法将边缘直接应用于自适应洪水填充算法。洪水填充算法从一个起始节点开始搜索其邻域(4或8),并提取与其相连的附近节点,直到封闭区域中的所有节点都已处理完毕。它是从一个区域中提取几个连接点,或将它们与其他相邻区域区分开来。然而,由于边缘检测器生成的边缘通常是不连续和模糊的(如图2的顶部所示),将其直接应用于洪水填充算法可能会导致整个图像都被填充。因此,该方法设计了一个自适应掩膜来缓解这个问题,即一个半径随图像大小而变化的圆。具体而言,半径r定义为
(1)
式中:I是输入图像;r(I)是对应于输入图像I的掩膜半径;hl和wl分别表示输入图像的长度和宽度;γ是超参数。
图像I的标注真值可以表示为
(2)

e=E(I),
(3)


图2 提出方法的框架示意图
(4)
式中:g表示获得的伪标签;F(u,v)表示洪水填充算法,其中u和v表示算法的输入参数;S表示图像I的标注真值。
1.2 基于变换器的点监督显著目标检测方法
稀疏标记下的显著目标检测任务的难点在于该模型只能获得局部的标注真值,缺乏全局信息的指导。该方法认为通过标注位置和未标注位置之间的相似性可以建立标注位置和未标注位置之间的联系,以获得未标注区域的显著性值,可以在一定程度上缓解这一问题。考虑到视觉变换器(ViT)建模相似性的特性,该方法利用hyper-ViT(即“ResNet-50+ViT-Base”)作为主干来提取特征并计算自身的相似性。
具体地说,对于大小为3×H×W的输入图像,CNN嵌入部分生成C×H/16×W/16的特征图。ResNet-50的多阶段特征表示为R={Ri|i=1,2,3,4,5}。然后是变换编码器以C×H/16×W/16的位置嵌入总和以及展开的特征作为输入。经过12层的自注意力层后,变换编码器输出了C×H/16×W/16的特征。
边缘保持解码器由两部分组成:显著性解码器和一个近似边缘检测器,如图2所示。显著性解码器由4个级联的卷积层组成,其中每一层都由批量归一化(BN)层、ReLU激活层和上采样层组成,上采样层将变换编码器的特征作为输入。该方法将每层显著性解码器的相应特征表示为D={Di|i=1,2,3,4}。对于后一部分,由于弱标注本身缺乏结构和细节信息,利用一个边缘解码器作为近似的边缘检测器,通过使用真实边缘检测器生成的边缘结果来约束输出结构。近似边缘检测器的输出可以表示为fe=Φ(cat(R3,D2)),其中Φ表示单个3×3卷积层,后面是BN和ReLU层。通过在fe之后添加一个3×3的卷积层,可以获得边缘图e,然后由真实边缘检测器生成的边缘图对其进行约束。
1.3 非显著目标抑制
可以观察到,由于弱监督图像的稀疏性,监督信号只能覆盖图像的一小部分,这导致模型只学习高亮显示的目标物体,而忽略当前场景中哪些目标不应被高亮显示。
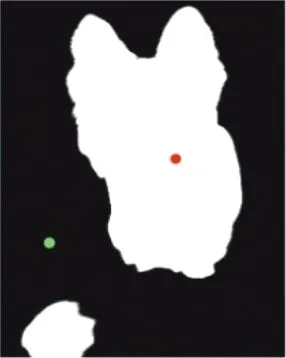
为了抑制不显著的目标物体,本文提出了一种简单而有效的方法,即利用监督信号提供的位置线索,填充生成的高亮物体来达到抑制不显著物体的目的。所获得的显著目标区域(如图3(b)所示)可通过式(5)的方式获得:
Pf=F(S-Sb,P1st),
(5)

由于在第一轮训练期间仅为显著目标提供了内部的局部标签,这可能会导致模型无法准确区分边缘,因此在Pf上使用了尺寸为10的扩展操作(即使用膨胀/空洞卷积)。扩展区域被指定为非特定区域(如图3(b)中的黑色区域所示),而保留区域被指定为背景区域(如图3(b)中的绿色区域所示),表示为P2nd,它被用作第二轮训练的伪标签。图3(c)为原始图像中伪标签的对应位置。
(a)
如图4所示,由于标签的稀疏性,模型倾向于检测不显著的目标。图4(a)表示在点监督下第一轮训练后得到的伪标签,图4(b)则表示对图4(a)生成的伪标签进行非极大值抑制后的伪标签结果。事实上,该模型退化为一个检测前景目标的模型。通过重复使用监督点的位置信息,可以利用非显著抑制方法来成功抑制掉大多数不显著的目标。

图4 非显著抑制的效果示意图
1.4 损失函数
在该网络中,采用了二分类交叉熵损失、部分交叉熵损失和门控CRF损失。对于保留边缘的解码器流,使用二分类的交叉熵损失来约束e,即:
Lbce=∑(r,c)[ylog(e)+(1-y)log(1-e)],
(6)
式中:y表示标注真值;e表示预测的边缘图;r和c分别表示行和列坐标。对于显著性解码流,采用了部分交叉熵损失和门控CRF损失。部分二元交叉熵损失用于关注的确定区域,而忽略不确定区域:
Lpbce=-∑j∈J[gilog(sj)+(1-gj)log(1-sj)],
(7)
式中:J代表标记区域;g代表标注真值;s代表预测的显著性图。为了获得更好的目标结构和边缘信息,在损失函数中使用了门控CRF:
Lgcrf=∑i∑j∈Kid(i,f)f(i,j),
(8)
式中Ki表示像素i周围k×k的覆盖区域。d(i,j)定义为
d(i,j)=|si-sj|,
(9)
式中si和sj是位置i和j处的显著值。f(i,j)表示高斯核带宽滤波器:
(10)

Lfinal=α1Lbce+α2Lpbce+α3Lgcrf,
(11)
式中α1,α2,α3是权重。在实验中,根据经验值都设置为1。
2.1 点监督数据集
为了尽可能减少标记时间消耗,同时提供显著目标的位置信息,通过重新标记DUTS[13]数据集(一个广泛使用的显著性检测数据集,包含10 553个训练图像)来构建一个点监督数据集。对于每幅图像,从4个标注人员的结果中随机选择一个,以减少个人偏见。在图1中,展示了一个点标注的示例,并将其与其他标注方法进行了比较。对于每个显著的目标,只随机选择一个像素位置进行了标记(为了清晰,放大了标记位置的大小)。由于标注方法很简单,即使是初学者也可以在平均2 s的时间内标注一幅图像。
2.2 实验细节
该模型在PyTorch工具箱上实现,使用标注的点监督数据集进行训练。在4个TITAN XP GPU上进行模型的训练。对于变换器部分,使用了 “ResNet50+ViT”作为骨干,并且没有进行任何调整。通过使用提供的预训练权重来初始化嵌入层和变压器编码器层,且ViT是在ImageNet 21K上预先训练的。对于变换器部分,最大学习率设置为0.000 25,对于其他部分,学习率设置为0.002 5。采用随机梯度下降法(SGD)训练网络,并将参数动量设置为0.9,权重衰减设置为5×10-4使用。使用水平翻转和随机裁剪作为数据扩充的方式,批量大小设置为28,第1次训练过程需要20个迭代周期。式(1)中的超参数γ设置为5,第2轮训练使用了相同的参数。在测试过程中,将每个图像的大小重新调整为352×352,然后将其输入到网络中,以预测显著性图。
2.3 与其他方法的比较


表1 与其他方法在ECSSD和PASCAL-S数据集上的定性比较
如图5所示,该方法在两个公开数据集上的精度召回结果优于其他方法。如图6所示,与其他弱监督或无监督方法相比,该方法获得了更准确和完整的显著图,甚至超过了部分全监督方法的预测结果。第1、5和6行分别展示了该模型捕捉整体显著目标的能力,对于具有极其复杂纹理的目标 (第5行)也可以通过该方法进行精确地分割。此外,基于提出的非显著抑制方法,可以精确地提取显著的目标并抑制不显著的目标(如第2~4行所示)。最后一行显示了该模型提取细节的能力。
如图5所示,该方法在两个公开数据集上的精度召回结果优于其他方法。如图6所示,与其他弱监督或无监督方法相比,该方法获得了更准确和完整的显著图,甚至超过了部分全监督方法的预测结果。第1、5和6行分别展示了该模型捕捉整体显著目标的能力,对于具有极其复杂纹理的目标(第5行)也可以通过该方法进行精确地分割。此外,基于提出的非显著抑制方法,可以精确地提取显著的目标并抑制不显著的目标(如第2~4行所示)。最后一行显示了该模型提取细节的能力。

(a)不同方法在ECSSD数据上的精度召回对比

图6 与其他方法的定性比较
2.4 消融实验
首先,为了验证边缘保留解码器的有效性,使用第1轮的结果来评估方法的性能,因为如果第1轮产生不好的结果,将直接影响第2轮的结果。见表2,评估了边缘保持解码器的影响。由边缘检测器产生的边缘监督信息被移除。此时,边缘保持解码器只能聚合浅层的特征,不能显示检测边缘特征,导致整体性能下降。
其次是验证非显著性目标抑制的有效性。由于非显著抑制仅在第2轮训练中使用,在此根据第1轮产生的结果进行消融实验(即表2中的第1行)。表3为消融实验的结果。第1行代表直接使用第1轮生成的伪标签,而不进行CRF处理;第2行代表使用由密集CRF修正的伪标签;第3行代表该方法。实验结果表明,第2行比第1行效果好,说明用CRF优化第1轮的伪标签可以让第2轮训练更好,而使用了非显著抑制后,可以取得更好的效果。
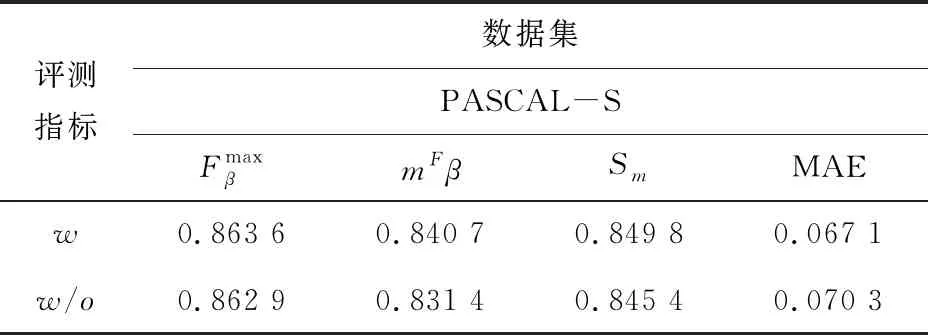
表2 边缘保留解码在PASCAL-S数据集上的有效性验证
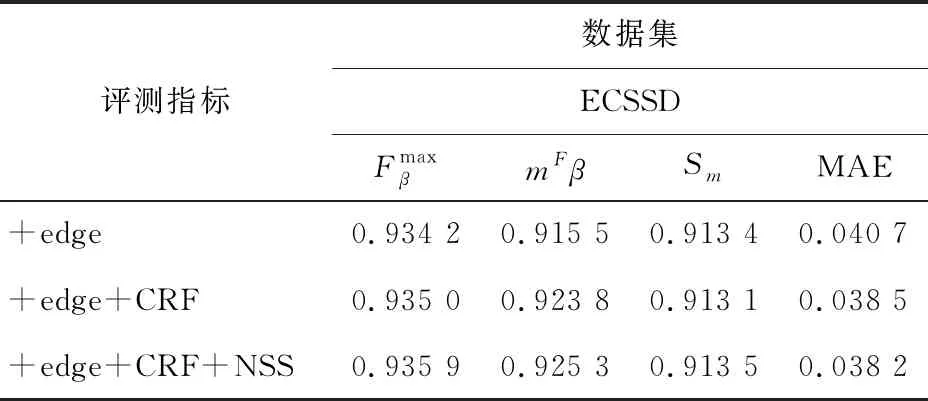
表3 非显著抑制在ECSSD数据集上的消融实验
最后是超参γ的影响。见表4,测试了不同γ值对第1轮训练的影响。实验结果表明,太小的γ会导致产生伪标签监督信息过少,γ值过大会导致伪标签包含错误的区域。这两种情况都会影响模型的性能,选取一个合适的γ才能保证模型效果稳定。

表4 参数的影响
本文方法提出了一个基于点监督的显著目标检测框架。针对伪标签生成和显著性检测等问题,设计了自适应洪水填充算法和基于变换器的点监督检测模型。为了解决现有的弱监督显著目标检测模型的退化问题,该方法提出了非显著目标抑制技术来显示过滤掉非显著但误检测到的目标物体。实验结果表明,该方法具有更强的监督能力,而且取得了优于其他弱监督显著目标检测的精度。
猜你喜欢边缘标签显著性基于显著性权重融合的图像拼接算法电子制作(2019年24期)2019-02-23基于视觉显著性的视频差错掩盖算法西南交通大学学报(2018年5期)2018-11-08无惧标签 Alfa Romeo Giulia 200HP车迷(2018年11期)2018-08-30不害怕撕掉标签的人,都活出了真正的漂亮海峡姐妹(2018年3期)2018-05-09一种基于显著性边缘的运动模糊图像复原方法苏州科技大学学报(自然科学版)(2017年1期)2017-03-20一张图看懂边缘计算通信产业报(2016年44期)2017-03-13论商标固有显著性的认定知识产权(2016年8期)2016-12-01标签化伤害了谁公民与法治(2016年10期)2016-05-17科学家的标签少儿科学周刊·少年版(2015年2期)2015-07-07在边缘寻找自我雕塑(1999年2期)1999-06-28