张 逸,姚文旭,邵振国,张良羽
(福州大学电气工程与自动化学院,福建省 福州市 350108)
在中国生态文明建设不断推进过程中,大数据、云计算等技术手段已逐步应用于污染治理、气候预测等生态环境领域,成为推进环境治理体系现代化的重要方式[1-2],数字环保与智慧环保体系在环境治理应用与环保产业转型上将发挥重要作用[3-4]。
在企业的污染与环保工况监测问题上,传统方案常采用监测末端水、气的方式,判定企业污染排放是否超标,但许多企业仅在定期监管检查时应付治理,监测缺乏实时性。在智慧环保的背景下,相关人工智能计算方法也应用到了重点企业污染排放物的监测分析中[5],而这些方案成本较高、适用范围较小。近年来,考虑到电力数据具有实时性好、可挖掘价值高等特点[6],相关部门运用电力数据来开展环保与污染治理工作,文献[7-8]通过在污染源企业中的产污、治污、排污等设施处分别安装电力监测装置,利用用电数据判断各个设备是否启用,进而判定环保情况。但此类方案需要对企业中与污染相关的设备一一监测,是一种侵入式的监测方式。当企业内部设备众多时,用电监测设备的数量也随之增加,用电线路改造也相应复杂,对生产影响较大,需要企业配合较多。
随着大数据分析与机器学习等技术发展,非侵入式负荷监测(non-intrusive load monitoring,NILM)受到了广泛的研究与应用[9-10]。NILM 是一种在用户用电入口处监测用电数据,通过事件检测、特征提取等方法分解出各用电负荷情况的监测方法[11-12]。本文研究拟借鉴NILM 思路,使用产污、治污设备所在生产单元电气入口处的用电数据,识别企业环保情况,以克服侵入式监测的不足。
针对工业企业的NILM 场景,由于生产环节复杂,涉及用电设备种类与数量众多,难以实现完整的负荷分解过程,相关的研究与应用中常是根据实际需求合理简化。文献[13]中将完整的企业负荷分解,缩小至以厂房为单位,实现厂房内各个设备的能耗监测;
文献[14]将工业负荷投切时的用电波形与模板进行匹配,识别不同的负荷投切事件。考虑到污染企业的环保监测任务是针对“生产排污时环保环节正常投入”“生产排污时环保环节未投入”等直接反映环保正常与否的工况进行识别,因此,本文在实际污染企业场景,将完整的负荷功率识别任务转换为对环保工况类别的识别。
关于数据需求方面,在传统NILM 中,要想较精准地识别各负荷情况,常需要利用1 kHz 以上的高频采样波形数据,并从中提取谐波、电压-电流轨迹等特征进行计算[15],但高频的数据又面临测量采集要求与长期存储成本较高的问题。随着对电能质量问题的重视,电网与用户两侧均安装了大量在线电能质量监测装置,其监测数据具有特征类型多、频率相对较高、在长期应用过程中监测相对稳定可靠等特点[16-18],故本文采用企业的电能质量监测数据作为后续工况分析识别的数据源。
综上,本文针对环境污染企业的环保监测问题,采用非侵入监测方案,将企业环保监测问题转化为对环保工况的分类与识别。基于电能质量监测数据,首先,对表征生产工况的特征数据进行时序变点检测与聚类,实现企业总体生产工况的划分,进而提取环保工况类别;
然后,采用Stacking 分类模型,对环保相关的工况进行分类学习,识别出环保环节异常的工况;
最后,利用所训练的工况分类模型识别出环保异常工况,并在仿真算例与实际企业数据中验证。
污染企业环保工况与生产工况及环保设备运行情况有关,二者可通过人工现场记录或安装设备状态采集终端的方式获取。但实际中生产设备类型和数量均较多,现场记录和安装终端成本较大。同时,不同生产工况下用电数据常表现出不同特征且差异明显,使得通过数据分析以区分生产工况成为可能。因此,对于企业生产工况,本文通过数据挖掘方式获取,减少实际应用过程中对多种生产设备单独监测的依赖;
对于环保设备运行情况,因设备较少,为保证准确,仍以人为记录或安装采集终端的形式进行运行状态获取。生产工况判断基于变点检测理论,以下进行详细说明。
1.1 时序数据突变点检测
突变点是时序中存在的引起数据前后均值、方差等统计量出现明显变化的点,也可称作变点,突变前后数据特征的变化常反映出实际物理状态的改变[19]。在用电场景中,突变点反映出负荷用电过程的变化,因此,可通过计算时序突变点,寻找用电工况变化的时刻。具体地:对于用电时序:Y={y1,y2,…,yn},假设存在一个由ω个突变点构成的突变点集合T={τ1,τ2,…,τω},其中,每个突变点的位置均为1 至n之间的整数,并定义τ0=0,τω+1=n,则这些突变点将原时序分割为ω+ 1段 子 序 列,其 中,第i段 可 表 示 为:Yi={yτi-1+1,yτi-1+2,…,yi}。
以上多变点检测问题常常转化为求取最小目标函数来求解[20-21],目标函数F(n)的核心是一个能表征数据同质性的代价函数C(·),如式(1)所示。当代价函数值越小时,表明数据越呈现出同一种统计性质;
反之,在一组性质相同的数据中引入一个突变点时,数据的代价函数值将增大。
式中:C(Yi)为第i段子序列所计算的代价函数,为提高实际应用时对不同企业、不同类型用电数据的适用性,不同分布类型的数据对应不同计算方式,详见附录A 式(A1);
βf(ω)为目标函数优化的附加惩罚项,用于平衡所计算的突变点数量,减少出现变点过多或过少的现象,其中β为惩罚因子,f(ω)为一个随变点数量增多而增大的惩罚函数。
令惩罚项f(ω)=ω+1,则求取F(n)的迭代式可由式(2)推导得出,进而将式(1)中求解全局最优解的问题转化为不断寻找前一个变点的过程。
设置初值F(0)=-β,在1 至n中循环计算,将满足目标函数最小的时间点作为新的变点,不断迭代求解出所有的突变点。此外,在每次搜寻过程中,去除不可能成为变点的数据索引,减少计算量。引入如下的判断条件:假设对于数据时间点t、s、l(t<s<l),存在一个常数K满足式(3),则当式(4)成立时,认为t不可能成为l之前的最后一个变点,将其排除[20-21]。
1.2 变点整合与环保工况类别提取
基于变点检测方法划分生产工况,并结合环保设备运行情况得到环保工况,步骤如下:
1)选择m个能够反映企业生产工况的特征数据{X1,X2,…,Xc,…,Xm},例如:在生产设备容量占比较大时,使用能直接体现总体用电量的功率型数据,如图1 实例中,选择各相有功功率(PA,PB,PC)与三相总有功功率P3ph数据;
又如主要生产设备是谐波、三相不平衡等干扰源时,也可选择电流总谐波含量、不平衡度等电能质量指标。
2)对m类特征时序分别计算变点,得到式(5)中的总变点集合O,时序波形示意图见图1(a)至(d),其中,平行于纵轴的直线即为变点所在位置。
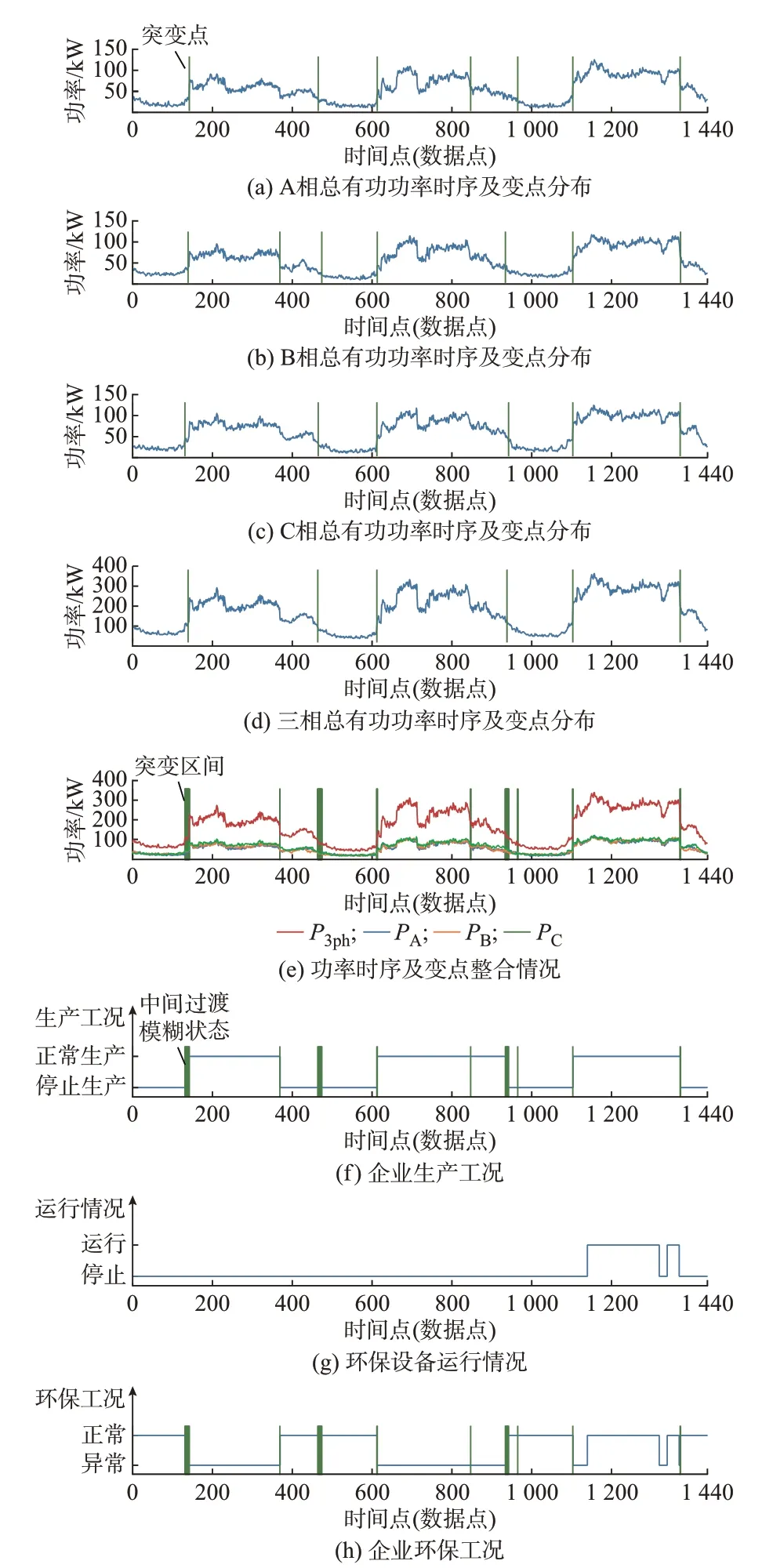
图1 污染企业环保工况提取示例图Fig.1 Example of extraction of environmental protection operation condition in polluting enterprises
式 中:X1至Xm表 示m类 时 序 数 据;
O1至Om表 示m类时序数据各自的变点集合;
tXm,i为集合Om中的第i个变点;
n1至nm为各集合中的变点数量。
3)由于实际中各相用电数据非完全平衡,各时序提取的突变点并非一一对应,且部分工况转换过程需持续一定时间而非瞬时完成。因此,考虑对式(5)中不同特征时序的变点进行归并,并将时间相近的变点整合为区间,如图1(e)所示。具体过程为:首先,将O1至Om做并集处理,并将得到的结果按照从小到大排列,得到Oall,如式(6)所示;
然后,设置过渡时间阈值ε(本文将该阈值设定为30 min,在实际应用时,可视环保监管要求的严格程度调整所容许的过渡环节时长);
最后,对Oall中的变点逐一判断,当满足ti+1-ti≤ε时,将前后两变点构成的区间[ti,ti+1]作为变化时段,得到新的变点集合O′all,如式(7)所示。
式(6)中t1<t2<…<ti<…<tn,i为1 到n之间的整数;
式(7)中[t2,t3]与[tk,tk+1]均表示整合后的变点区间。
4)采用k-means 聚类方法,对由变点分段后的各子段均值数据进行聚类,聚类数选为2,分别对应企业正常生产工况与停止生产工况,具体过程见附录B。此外,对于第3)步中计算的变点及变点区间,将其作为工况间切换的中间过渡模糊状态。最终,得到企业生产工况时序分布,如图1(f)所示。
5)根据环保相关工况提取规则(详见附录A 图A1),将第4)步中所得的生产工况与环保设备运行情况组合,可得到环保工况,对应于图1(f)至(h)。其中,过渡环节由于数量少、数据特征存在变化,在后续环保异常识别与监管过程中不作考虑。
由于在环保工况正常与异常2 类工况下,企业用电数据特征存在差异,如附录A 图A2 所示,图中展示的是A 相电流总谐波含量、B 相5 次谐波电流方均根值以及三相总有功功率数据,数据为图1(h)中各工况时段的均值。基于这种差异性,可将多维电能质量监测数据作为特征,环保工况作为标签训练分类模型,识别异常环保工况,具体分析见第2 章。
2.1 Stacking 集成分类原理
不同的机器学习模型由于原理与训练方式不同,存在各自的适用性与特点,如支持向量机(support vector machine,SVM)对高维数据与非线性问题的处理上更加稳健且对极值不敏感;
逻辑回归(logistic regression,LR)的概率原理清晰、实现方式简单高效,在线性问题上处理更具优势;
K 最邻近分类算法(K-nearest neighbor,KNN)不对数据进行假设,易于实现;
随机森林(random forest,RF)不易出现过拟合现象,可以处理高维度的数据;
梯度提升决策树(gradient boosted decision tree,GBDT)对数据异常值的鲁棒性较强。但实际中不同污染企业设备类型和用电情况多变、监测数据特征存在一定差异,单一的模型常难以适用于后续不明确的污染企业场景。为提高对实际数据的适用性,本文选择Stacking 集成模型作为污染企业环保工况识别的分类模型,通过对不同分类器的学习结果进行堆叠组合的方式,从多个模型不同的角度挖掘数据特征,取长补短,提高模型泛化能力与工况识别准确度[22-23]。
如附录A 图A3 所示,Stacking 模型结构通常由2 层构成。第1 层由若干个基分类器构成,其中,考虑到不同模型对数据的适用程度不同,基分类器的确定通常是分别利用SVM、LR、RF、KNN、GBDT等不同模型,在不同参数或限定条件下,对数据集进行初步测试并从中选取效果较优的3~5 个分类模型,训练的特征与标签分别为多维电能质量监测数据与环保工况。将原始数据在各个基分类器下得到的分类结果(概率得分形式)作为第2 层元分类器的输入特征数据,元分类器模型与基分类器类似,可选择为常用的单一机器学习分类模型,但由于其训练的特征仅余第1 层计算输出的结果,需适当降低模型复杂度以减少过拟合现象,如在LR 中增加正则化,在树模型中减少数量与深度等。最后,在第2 层元分类器中对基分类器计算所得的特征进行训练学习,计算出环保工况类别。
此外,Stacking 模型在各个分类模型训练的过程中采用k折交叉验证的方法,以减少样本不平衡与过拟合等影响,提高模型稳定性。如附录A 图A3中上半部分所示,k折交叉验证的具体操作为:在划分好训练集数据与测试集数据后,再将训练集数据平分为k份不交叉的数据,依次将其中1 份设置为验证集,训练余下k-1 份数据。将k次训练数据预测的得分求取均值,作为最终训练的结果。
2.2 环保工况异常识别流程
本文基于电能质量监测数据进行环保工况识别的主要流程如图2 所示,其主要步骤如下:

图2 环保工况分类识别流程图Fig.2 Flow chart of classification and identification of environmental protection operation conditions
1)原始数据源获取。考虑企业用电设备数量众多,存在不同的用电行为与电能质量特性,为了在后续分类模型的训练中更好地区分不同用电特征,选择的数据类型涵盖电流、功率这类基本电气参数以及谐波畸变率、不平衡度等体现企业电能质量特性的多维电能质量指标数据。此外,在具体场景中,还需考虑背景电网电能质量扰动情况以及其他干扰源负荷的影响,在中低压场景可筛选与用户发射特性相关性更高的电流类电能质量等特征参数。
2)环保工况标签获取。按第1 章所述方法获得环保工况标签。
3)环保工况分类模型训练。将第1)步中得到的电能质量监测数据作为输入特征,结合第2)步所得环保工况标签,对一定时段的训练数据进行Stacking 分类模型训练。
4)异常环保工况识别。对企业后续数据进行环保工况分析,识别异常环保工况。
3.1 仿真算例基本情况说明
在MATLAB/Simulink 环境中搭建污染企业用电工况仿真模型,验证本文方法对不同场景的适用性。考虑实际企业中一个含生产、治污等各类用电设备的完整生产单元通常由单段/条母线供电,仿真中以一段10 kV 母线进行模拟,并设置多个污染企业中常用的典型负荷,仿真电气接线示意图如图3所示。其中,在环保设备的选择上,通过调研可知:在水、气等污染治理过程中,变频、变流及自动控制技术得到广泛使用,如鼓风机、除尘风机、水泵以及成套污水治理设备均已采用相关自动控制技术进行转速、振动频率的控制,静电除尘设备还应用到升压与变流技术生成高压直流电场等[24-25],因此,将变频负荷4 与5 视作2 台环保治理设备;
在生产设备与其他厂务设备的选择上,设置了线性负荷、变频负荷以及部分单相负荷等不同特性的设备,用于后续组合出不同的用电场景。

图3 仿真算例电气接线示意图Fig.3 Schematic diagram of electrical connection for simulation case
参考实际电能质量监测设备的测量与数据统计方法[26],在10 kV 进线处模拟一个电能质量监测装置,进行特征指标计算与统计,通过等比例时间缩放,得到与实际监测数据相同的3 min 间隔的每个仿真天(24 h)共480 个点的95%概率值数据,数据类型包括各相电压与电流有效值、各相功率与总功率(有功功率、无功功率、视在功率)、功率因数、各相电压与电流的基波有效值、各相电压与电流的2 至49 次谐波含有率与有效值、各相电压与电流的直流分量、各相电压与电流的0.5 至15.5 次间谐波含有率、电压偏差以及电压与电流负序不平衡度。
3.2 不同生产工况场景设置说明
仿真算例中,对于负荷1 至5,在每个仿真天内设置不同随机数控制其启停时间,模拟环保设备与生产设备的不同运行情况;
对于负荷6 至9,设置为持续运行负荷,模拟实际企业生产过程中部分不间断运行的设备。共进行24 个仿真天的测试,得到不同的用电场景,详细的负荷接入时间见附录A表A1。
对于生产工况,分别将仿真中负荷特性不同、运行时间不定的生产负荷1、2 作为主要生产设备,设置3 类用电场景:
场景1:线性生产负荷1 运行时,视作正常生产工况;
场景2:变频生产负荷2 运行时,视作正常生产工况;
场景3:线性生产负荷1 与变频生产负荷2 同时运行时,视作正常生产工况。
以上场景中,主要生产设备未运行时均视为停止生产,且对主要生产负荷外的其余负荷是否运行不进行单独考虑,仅作为工况分类的干扰与不确定因素。
在生产工况划分的基础上,按照实际中环保部门要求的环保工况异常判定与监管策略,设置了2 类环保工况判定规则:
规则1:生产正常时,仅当2 台环保设备同时启动才视作环保工况正常,其中1 台环保设备关闭则为异常。
规则2:生产正常时,至少1 台环保设备启动,即可视作环保正常工况,2 台环保设备均关闭时为环保异常工况。
2 个规则下,生产工况为关停时均视为环保工况正常。
3.3 仿真算例结果与分析
首先,进行变点检测与工况聚类,获取不同场景中的生产用电工况。考虑主要生产负荷中负荷1 的容量占比最大、负荷2 为主要谐波干扰源,在场景1选择各相有功功率与三相有功功率数据,在场景2选择各相电流总谐波含量数据进行计算,各特征数据变点识别结果如附录A 图A4、图A5 所示。为说明本文变点检测算法的适用性与准确性,将本文算法以及其他几类常用变点检测方法的计算结果与仿真设置的生产负荷切换事件(2 个场景中单一负荷切换事件均为48 次)进行对比,如表1 所示。

表1 不同场景下的变点计算结果Table 1 Calculation results of change points in different scenarios
由表1 可以看出,本文方法在2 个场景中均能够较为准确地识别出预设变点,仅在场景2 中出现3 个漏识别的变点。同时,由于存在其他相似负荷的投切事件干扰,例如同为谐波干扰源的环保设备投切对谐波数据变点识别存在影响等,导致各方法都额外识别出了部分无效变点,但本文方法的敏感度较基于累积和(cumulative sum,CUSUM)与基于贝叶斯信息准则(Bayesian information criterion,BIC)的方法低,无效变点数量相对较少。此外,考虑后续工况分类时,将去除变点时刻数据,本文所得变点数量在合理范围内(场景1、2 占比分别为0.57%、0.91%)。
然后,对变点划分后各段数据的均值进行聚类,结果在附录A 图A6 中以三维示意图体现,分别对应正常生产工况与停止生产工况,可以看出二者存在差异。同时,将计算的生产工况与预设生产工况进行对比,如附录A 图A7 所示,其中,场景3 的生产工况计算则由场景1、2 组合而成,计算工况与预设工况基本一致,3 个场景准确度分别达99.44%、99.07%与98.72%,表明了本文方法准确有效。
最后,对3 个生产用电场景分别采用2 类环保工况判定规则,得到环保工况类别,取前18 个仿真天的数据作为训练集,模型参数设置见附录A 表A2,后6 个仿真天的数据作为测试集,在附录A 图A8 中对各场景与规则下的模型预测值与真实值进行对比,其中,1 与0 分别表示环保工况正常与异常。在数据选择上,考虑实际的低压配电网中监测点谐波电压、电压总谐波畸变率、电压偏差、电压不平衡度等电压质量参数受背景中其他电能质量干扰源的影响较大,并非与用户自身行为完全相关[29-30],本算例中选择与用户自身运行关联更密切的电流类型电能质量监测数据进行训练。从附录A 图A8 中可以看出,各场景与规则的分类效果均较好,真实值与预测值基本一致,仅少部分时段存在错误(如场景3 中红框所示)。
计算混淆矩阵进行量化分析,混淆矩阵表示模型识别的2 类环保工况结果相对真实值的情况,其4 个元素分别记为TP、FN、FP、TN,其中:TP、TN分别为分类器准确识别出的环保工况异常与正常的数量,FN、FP表示对2 类真实工况类别误判的数量。进一步,如式(8)至式(11)所示,从混淆矩阵中计算分类结果评价指标准确度SACC、精确率SPRE、召回率SREC与F1 得分SF1,其中:SACC是对整体工况分类的准确度评价;
精确率SPRE与召回率SREC表示对“环保异常”的识别精度与完整度,F1 得分SF1是精确率与召回率的调和平均值,体现分类器的综合特性。
限于篇幅,仅列出各个方案的混淆矩阵以及衡量综合分类效果的SACC与F1 得分SF1,如表2 所示。

表2 不同场景和规则下的分类结果Table 2 Classification results in different scenarios with different rules
由表2 分析可知,不同场景与规则下,环保工况正常与异常的数量不同,但均能得到超过95%的SACC与SF1,表明本文方法能够较好地适用于不同类型和数量的生产设备与环保设备所组合的用电场景。此外,为说明本文方法数据源选取的合理性,与下列数据特征选择方式下的结果进行对比,包括:1)选择全量电能质量监测数据;
2)仅选择电压、电流、功率及功率因数4 类基本数据;
3)仅选择电能质量指标数据;
4)仅选择电流质量指标数据;
5)参考文献[31]利用主成分分析法降维,选取贡献率为前90%的特征。在图4 中比较各方式下的分类SACC与SF1值。

图4 不同数据特征选择下的分类效果对比Fig.4 Comparison of classification effect with different data feature selections
由图4 分析可知,按本文所使用的去除电压质量等参数的方案以及选择全量特征时,在不同场景和规则下的分类效果均较好;
仅选择基本数据、电流质量数据与电能质量数据时,在场景2、3 中的分类效果出现一定波动;
而使用主成分分析降维输入数据时,SF1值在各场景与规则下的波动最大,稳定性较差。具体分析误判情况为:在第23 天(4~6 h)时段,几类方案易将异常环保工况误判为正常,可能原因在于这一时段2 台环保设备虽均未启用,但与环保设备容量相近且存在电能质量干扰发射特性的整流负荷3 正在运行,引起干扰。以上情况表明,当企业用电设备多、工况复杂时,将电能质量数据与基本用电数据结合,引入更多特征进行训练,能够覆盖更多用电特性,有利于分类效果提升。
4.1 污染企业基本状况与监测数据情况
以中国福建某制鞋企业为试点,进行环保工况识别,该企业电气接线示意图如附录A 图A9 所示,生产设备主要包括加热与冷却装置、异步电机、紫外线杀菌光源等;
环保设备主要为抽风机和UV 光解废气处理设备组成的排污和治污系统。企业在生产与环保过程中存在谐波与不平衡等电能质量发射特性,故在企业的电气入口处采集电能质量监测数据,用于后续环保工况识别。但考虑到该污染企业所处电压等级较低,频率以及电压类的电能质量易受电网背景波动与其他电能质量干扰源影响,因此,最终选择反映污染企业自身用电特性的电流类电能质量以及功率指标用于后续环保工况分类,指标详见表3,数据类型为3 min 的均值数据。

表3 用于环保工况分类的实测特征数据Table 3 Measured characteristic data for classification of environmental protection operation condition
4.2 企业环保相关工况提取
取2021 年1 月9 日 至25 日 共17 d 的8 160 条 数据进行分析。首先,利用变点检测方法,由有功功率数据计算出生产工况,结果如附录A 图A10 所示,经核实,与实际企业生产工况基本相同。随后,由环保设备处安装的监测终端获取环保设备运行情况,共同确定各时段的环保工况类别,如表4 所示。

表4 环保相关工况类别情况Table 4 Category of operation conditions related to environmental protection
4.3 工况分类识别与结果分析
对数据集进行缺失数据插值补齐,去除数值全为0 的特征,在附录A 表A3 中对这部分数据进行了示意。按8∶2 的比例将2021 年1 月22 日14:00 以前的数据进行模型训练,后续数据进行测试,在分类过程中设置基分类器为LR、SVM、RF 与GBDT,详细参数见附录A 表A2。采用5 折交叉验证进行训练,计算上述4 个基分类器单独作用以及在4 种集成方式下测试集的结果混淆矩阵,如附录A 图A11 所示。可以看出,Stacking 分类器的混淆矩阵非对角元数量相对于单一分类模型均有所减少。其中,以SVM 为元分类器的Stacking 模型下,FN、FP数量最少,分类效果最优。进一步计算分类结果评价指标,如表5 所示。

表5 分类结果的评价指标Table 5 Evaluation index of classification results
从表5 中可以看出,集成模型下,分类结果的各项得分值有所提高,其中,第2 种集成方案下的指标得分最高,SACC与SF1值均超过96%,相对各种单一基分类器提高了3%以上,表明基于Stacking 集成的工况分类模型可以在误判和漏判较少的情况下,识别污染企业存在的环保异常工况。最终,选择效果最好的以SVM 为元分类器的Stacking 模型作为该企业的后续工况识别模型。
4.4 实际应用效果分析
以下分析本文方法在实际污染企业环保监测系统中长期应用的适应性。利用4.3 节中选择的模型,从2021 年1 月22 日开始,以每日24:00 为时间节点,动态计算环保工况分类识别的累计SACC与SF1值,直 至2021 年3 月22 日,得 到 如 图5 所 示 的曲线。
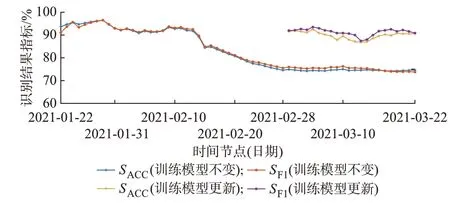
图5 环保工况长期累计识别效果Fig.5 Long-term cumulative identification effect of environmental protection operation conditions
由图5 可以看出,截至2021 年3 月22 日,2 个月的长期数据中,识别效果最终稳定至75%左右。其中前24 d 的测试数据中,两指标累计值均能达到90%以上,但在2 月中下旬,指标结果有一定幅度的下降,经过现场核实发现,2 月中旬为春节后企业复工初期,企业生产模式进行了一定调整,导致训练模型未能较好识别该时段的工况。为提高识别效果,将2 月的数据归入原始训练集中进行训练,最终在3 月测试的平均SACC与SF1分别达91.34%、89.74%,如图5 中更新训练模型后的结果曲线所示。可见,本文方法在实际应用中具备一定效果,但在实际用电场景模式变更后,模型识别精度有所下降,需要考虑使用现场核实过的数据更新识别模型等方法来提升结果准确度。
本文将污染企业环保监测问题转化为对环保环节相关用电工况的识别问题,利用电能质量监测数据进行学习训练,有效识别环保异常现象,得到结论如下:
1)相比于对企业生产、环保设备进行一一监测的传统用电监测方式,本文方法有效减少了所需监测终端成本以及对正常生产的影响,更易于实际工程实施。
2)本文通过滤除过渡环节、引入多维电能质量监测数据以及利用不同分类模型集成的优势,达到较好的准确度与适用性。
3)本文方法充分利用现有电力监测数据资源,是电力数据的跨行业应用,其思想与方法可拓展到更多电力以外的行业应用场景中。
本文方法应用过程中也存在一定的限制:本文仅考虑正常生产与停止生产以及环保工况正常与异常2 类,在未来需进一步开展细化研究工作,且在长期应用过程中,也需综合考虑模型更新成本、风险与识别结果准确性之间的关系,进一步优化企业用电状态不断变化时的模型更新策略。
本文相关实测和仿真电能质量数据已共享,可在本刊网站支撑数据处下载(http://www.aeps-info.com/aeps/article/abstract/20211203007)。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
猜你喜欢变点电能用电回归模型参数的变点检测方法研究数学物理学报(2021年4期)2021-08-30用煤用电用气保障工作的通知中国化肥信息(2021年12期)2021-04-19安全用电知识多中学生数理化·中考版(2020年12期)2021-01-18正态分布序列均值变点检测的贝叶斯方法湖北第二师范学院学报(2020年8期)2020-10-13基于二元分割的多变点估计河南科学(2020年4期)2020-06-03苹果皮可以产生电能奥秘(创新大赛)(2020年1期)2020-05-22独立二项分布序列变点的识别方法安徽师范大学学报(自然科学版)(2020年1期)2020-03-28电能的生产和运输小学科学(学生版)(2019年10期)2019-11-16海风吹来的电能小哥白尼(趣味科学)(2019年12期)2019-06-15为生活用电加“保险”中学生数理化·中考版(2018年12期)2019-01-31