耿新青,王正欧
(1.鞍山师范学院 数学与信息科学学院,辽宁 鞍山 114007;2.天津大学 系统工程研究所,天津 300072)
网页文本挖掘是对网页文档的内容进行分析,从网页文档内容中发现知识的过程。网页文本挖掘的对象可以是无结构的平面自由文本、半结构化的超文本和结构化的文本数据[1-3]。聚类是网页文本挖掘中一个重要方面[5]。模糊C均值聚类(Fuzzy C-means,FCM)[6,7]算法是一种经典的聚类算法,其应用到模式识别、图像处理、分类和聚类等领域[8-10]。FCM算法性能受初始聚类中心,权重指数等因素影响[11,12],一些学者对其进行了改进[13-15],但FCM算法仍存在3个问题:(1)聚类数事先是未知的,需采用有效的聚类标准获得聚类数。(2)初始化聚类中心是人为设定的。(3)模糊聚类算法受数据点分布的影响。Cobweb算法是一种增量式分层聚类算法,然而Cobweb聚类结果会受实例出现的顺序影响。文本聚类特征提取使用向量空间模型(Vector space model,VSM),每一个特征向量包含关键词权重,传统词频-逆向文件频率(Term frequency-inverse document frequency,TF-IDF)不能处理语义之间的依赖性和子主题结构。近年来,主题模型获得了关注,如David Blei提出隐含狄利克雷分布(Latent Dirichlet allocation,LDA)主题模型,以概率分布的形式表示文档集中的每篇文档的主题,用于文本分类的前期处理[16]。主题模型对于分析大文本集是有效的,能够将单词自动聚类到主题并找到文件集中文本之间的关系[18,19]。网页是一种特殊的文本,LDA在文本挖掘中存在网页文本挖掘涉及语义问题[20,21]。
针对当前文本挖掘方法存在缺陷,本文提出了基于增量式模糊聚类算法(Incremental fuzzy clustering algorithm,FCLDA)的文本挖掘方法,对文本集中的关键词的出现次数排序,优先选择出现次数多的关键词作为文本集的主题,利用LDA模型获得文档—主题概率分布,该分布组成的矩阵作为FCM算法的隶属度矩阵,在FCM迭代过程中采用模糊信息熵作为聚类数确定的标准,并对隶属度值调整,降低孤立点对聚类准确率的影响。随着主题词的增加,模糊信息熵达到最小值时,聚类数确定下来,即实现了增量式模糊聚类。本文隶属度矩阵是文档和主题构成的概率分布,不需要降维,因此本文算法在效率方面具有很大的优势。
1.1 LDA模型
LDA模型是一种无监督技术,用于在多个文本文件中发现主题,由于主题抽象,一段文本可能含有多种主题,因此将主题模型理解成一个黑箱,LDA模型的工作原理如图1所示。

图1 LDA模型框架
1.2 FCM算法
在FCM算法中[22,23],设{xi|i=1,2,…,n},n个样本组成的样本集合,假设c1,c2,…,ck是k个聚类中心,目标函数为
(1)

在模糊C均值的迭代过程中,还用到以下计算聚类中心的公式
(2)
在不同的隶属度定义方法下最小化的目标函数,得到不同的模糊聚类方法。
(3)
1.3 Cobweb分层聚类算法
Cobweb算法使用了分类树用来指导分类[24],构建分类树。在分类树中实现概念分层,完成概念聚类。
(1)建立一个类(簇),使用第一个实例作为它唯一的成员。
(2)对于每个剩余实例,在每个树层次(概念分层)上用一个评价函数决定选择以下两个动作之一执行。
①将新实例放到一个已存在的簇中。
②创建只具有这个新实例的新概念簇。
在Cobweb中,评价函数是一种对概念分类质量测量的指标。Cobweb算法使用了一种启发式评价方法—分类效用(category utility,CU)来指导分类。CU定义了聚类的好坏,值越小聚类较差,值越大聚类质量越好。
CU的计算公式如下
(4)
式(4)中包含3个概率。式中:
I.P(Au=Vuq|Cj)表示在类Cj的全体成员中,属性Ap为Vuq的条件概率;
II.P(Au=Vuq)表示在整个数据集中属性Au取值为Vuq的概率;
III.P(Cj)表示每个类Cj的概率。
2.1 主题词确定
首先数据预处理将无关字符过滤,文本分词、去掉停用词,数据归一化处理;然后统计文本集中单词的出现频率,对单词出现的频率作降序。单词出现的频率高低与聚类关系密切,优先选单词出现频率高的作为主题词,根据主题词个数确定主题词。
2.2 文本的特征表示
(5)

2.3 聚类数的确定
在信息论中,信息熵是信息的不确定程度的度量。当信息熵越大,信息就越不清楚。信息熵达到最小值时,聚类的结果确定下来。模糊聚类是以隶属度的形式表示类别的归属,当数据点的隶属度值越大,聚类划分的越明确。模糊信息熵将模糊的隶属度和信息熵相结合,本文采用的模糊信息熵公式如下所示
(1-uij)×log2(1-uij)]/N}
(6)
式中:uij是样本i属于类j的程度,H达到最小值时所对应的聚类数就是最佳聚类数。
2.4 隶属度的改进
对FCM算法的隶属度值加一个权值,使孤立点对聚类准确率的影响降低。隶属度改进公式为
(7)

2.5 本文算法-FCLDA
本文经过分词和特征选取得到的特征向量,确定主题词,模糊信息熵作为聚类数确定的标准,当迭代结束,聚类数确定。算法如下:
步骤1设定初始聚类数k为2,迭代次数为p=1,并选择指数权重m和迭代停止阈值ε。
一松了口气,她浑身疲软像生了场大病一样,支撑着拿起大衣手提袋站起来,点点头笑道:“明天。”又低声喃喃说道:“他忘了有点事,赶时间,先走了。”
步骤2LDA模型的主题数与聚类数一致,α取值为0.1,根据式(5)得到的文档—主题概率分布θ,构成向量矩阵A。
步骤3将矩阵A作为FCM算法的隶属度矩阵U(0)和H(0)。
步骤4根据式(2),计算聚类中心C(p)。
步骤5根据式(3),计算隶属度矩阵U(p)。
步骤6根据式(7),改进隶属度。
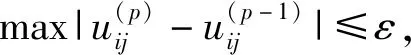
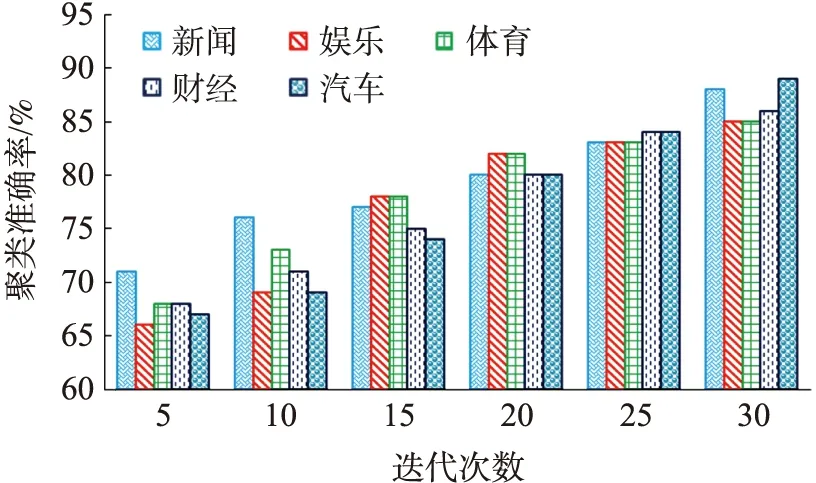
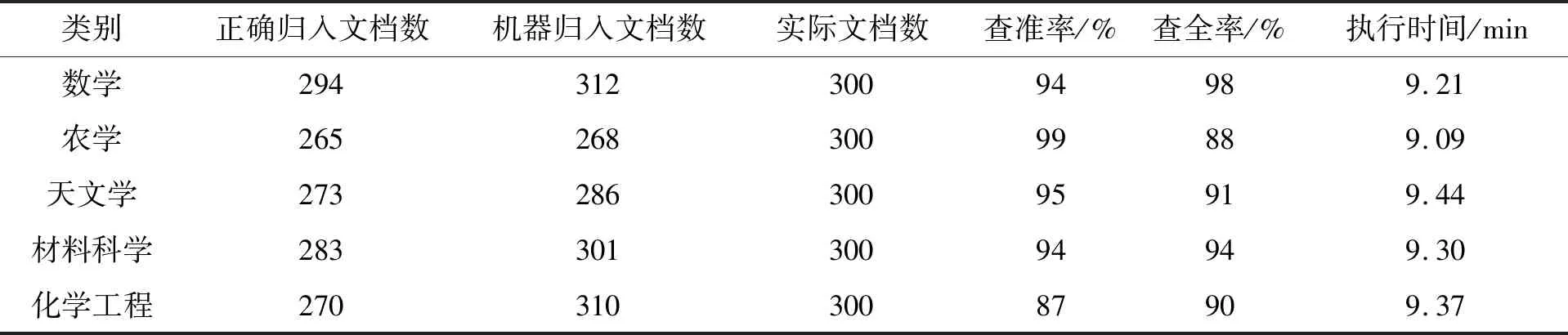
步骤8根据式(6),计算H(p),如果H(p) 将从网上获得的文档进行分词预处理,得到文本的特征向量,利用LDA模型得到文档的主题-概率分布,该分布构成向量矩阵作为FCM算法的输入,并对FCM算法的隶属度做了改进调整。随着主题词的增加,当模糊信息熵达到最小值时,聚类结果确定下来。本文算法文本挖掘过程如图2所示。 图2 文本挖掘完成过程 硬件试验环境:CPU为Intel(R)Core(TM)i5-6267U,内存8G。软件试验环境:操作系统为Windows 10(64位),python3.9。本文试验主要使用python语言的python-jieba库和scikit-learn库实现,参数m指数权重m控制聚类结果的模糊度,一般取值为2;ε控制算法的迭代收敛,一般取值为0.01;α取值为0.1。γ为0.2的运行效率高于γ为0.8,γ为0.2的聚类准确率低于γ为0.8,本文共做了3个试验来验证FCLDA算法的有效性和优越性。 为了测试FCLDA的文本挖掘方法的通用性,选择标准数据集和一些网站的数据进行仿真试验。标准数据集为:UCI数据库中选取3个数据集,分别是iris,class和wine。网站的数据为:知网上的数据和网易上的数据。 (8) 表1 混淆矩阵 (2)查准率和查全率。机器归入文档数是指算法运行后得到的分类结果。机器归入文档数包括正确分类结果和错误分类结果。 (9) (10) 3.4.1 UCI数据的试验结果 γ取值为0.2,将本文算法FCLDA,FCM算法进行对比试验,结果如图3所示。从试验结果来看,数据集iris的聚类效果比数据集class和数据集wine准确率高,本文FCLDA算法在数据集iris准确率为97%,在数据集class和wine的聚类准确率分别为89%和86%。总体上来说模糊聚类算法的聚类准确率要高于K近邻(K-nearest neighbor,KNN)算法。 图3 3种算法在3种数据集上的聚类准确率对比图 3.4.2 网易上的数据结果 本文取自网易新闻2016年5月1日至2016年5月14日的新闻文本,每个文件为一个新闻文本,对原始数据进行处理,生成便于处理的文本文件。处理过程采用如下步骤:数据清洗完成抽取语料文件中的正文内容,剔除空格、回车等空白字符。这些文章经过分词处理和特征选取后,有2 513个特征词,分为新闻、娱乐、体育、财经、汽车5大类。设定LDA模型的主题个数,利用文档-主题分布公式得到θ,θ作为FCM算法的隶属度矩阵,在FCM算法的迭代过程,对隶属度值做调整。当模糊信息熵达到最小值时,聚类数确定下来。当K为5时,完成聚类。FCM算法、KNN算法、FCLDA算法、KNN算法的对比结果如图4~6所示。随着迭代次数的增加,所有算法的聚类准确率在提高,当迭代次数为30次时,算法的聚类准确率达到最高。从表2结果来看,随着迭代次数的增加,FCLDA算法聚类准确率高于FCM算法和KNN算法。 图4 FCM算法的网易文本聚类准确率(%) 图5 FCLDA算法的网易文本聚类准确率(%) 图6 KNN算法的网易文本聚类准确率(%) 3.4.2 知网上的数据结果 本试验数据来自于http://www.cnki.net。文本集包括数学、农学、天文学、材料科学、化学工程5大类。聚类结果如表3~4所示。从聚类的结果来看,将LDA模型与模糊均值相结合得到FCLDA算法,由于该算法不需要降维,主题-文档概率分布作为FCM算法的隶属度矩阵,解决了语义模糊性的问题;在FCM算法迭代过程,逐渐增加主题词,并对隶属度进行改进调整,模糊信息熵作为聚类评价标准,完成增量式模糊聚类。克服了传统模糊算法需预先指定初始隶属度矩阵的缺陷,本文算法具有很大的优越性。在相同试验条件下,本文FCLDA算法执行时间约为10 min;由于FCM算法和KNN算法需要降维,FCM算法执行时间约为15 min,KNN算法执行时间约为20 min。FCLDA算法效率高于FCM算法和KNN算法,3种算法的聚类结果如表2~4所示。 表2 KNN算法的聚类结果 表3 FCM算法的聚类结果 表4 FCLDA算法的聚类结果 本文采用LDA模型的文档-主题概率分布作为FCM算法的隶属度矩阵,逐渐增加主题词,模糊信息熵确定文本聚类的聚类数,完成增量式模糊聚类,解决了传统模糊聚类需预先确定隶属度矩阵的问题。本文算法不需要降维,在算法迭代过程中对隶属度做了改进调整,仿真结果表明FCLDA算法的聚类结果精度高于FCM算法和KNN算法,模糊聚类解决了中文语义的多样性和归属的模糊性问题,本文算法更适宜于解决一般的文本聚类问题。下一步研究重点放在多源异构大数据的表示与语义理解,并将提出的算法与传统模糊文本聚类算法做比较研究。2.6 FCLDA算法在文本挖掘中的应用

3.1 试验环境设置
3.2 数据来源
3.3 定义评估标准




3.4 结果与分析