郭羽含,田 宁
(辽宁工程技术大学 软件学院,辽宁 葫芦岛 125105)
随着移动设备的普及和互联网的快速发展,网络预约出租汽车(简称网约车)已成为城镇居民的主要出行方式之一。选择网约车出行有利于缓解城市交通拥堵,对提高交通资源的利用、减少环境污染具有积极意义。截至2020 年,滴滴出行、神州专车、首汽约车等大型网约车平台的用户规模已达4 亿。随着用户出行需求的逐年增长,依托上述平台从事网约车经营活动的汽车驾驶员数量也快速增加。面对数量巨大的服务提供者与用户需求,平衡供需分布成为网约车平台亟待解决的问题。若服务车辆分布与乘客分布差异较大,不但会导致乘客候车时间长、对平台的服务满意度降低,还会使服务车辆空驶距离增加、运营效率低下、运营利润减少;
若可用服务车辆被提前调配至需求热度较高区域,则平台的资源利用率和服务质量可得到显著提升。
引导服务车辆的前提为预测不同空间位置在不同时间范围的需求热度,但需求热度与时间、空间、环境等多种影响因素相关且动态变化,因此预测难度较高。针对以往的交通问题的预测,现有的研究模型或方法可分为以下四类:
1)基于历史数据或时间序列的预测模型。
基于历史数据的预测模型由于维度单一,无法准确反映多维影响因素,故预测准确率较低。基于时间序列的统计模型只能用于数据相对稳定、呈规律性变化的情况,如肖强等[1]利用泊松分布计算出租车的合乘概率和等待时间;
Jamil等[2]使用差分自回归移动平均进行时间序列的分析,预测需求的热点区域;
Moreira-Matias 等[3]把加权时变泊松模型与出租车传感器数据结合用于预测短期范围内出租车乘客的空间分布。然而,随着我国城市建设速度的加快,需求热点区域的频繁变化也导致仅凭历史同期订单数量无法准确预测当前时空点的需求热度。
2)基于机器学习的预测模型。
随着人工智能技术的发展,基于数据的机器学习方法逐渐成为解决短时交通需求预测的主要方法。传统机器学习方法[4-6]可对更复杂的数据进行建模,捕捉交通信息中更深层次的特征,因此预测准确度也相对较高,如:Zhang等[7]考虑到出租车的需求和供应,提出二次集成梯度提升决策树方法来预测二者的差距,避免了在不同的数据稀疏条件下带来的预测结果变差的问题;
Jiang等[8]以网约车短期需求预测为目标,提出了一种基于最小二乘基于向量机(Least Squares Support Vector Machine,LS-SVM)的预测方法,并与Lasso 线性回归、最近邻回归、决策树回归等算法对比,验证了其性能的高效性;
郭宪等[9]提出基于多源数据的梯度决策回归树需求预测方法,基于多元历史数据,可实时预测当天的下一时间片段内各个城市区域的实时需求。虽然上述三者都考虑了多维影响因素,但仍然较难准确反映复杂多维数据的非线性相关性。
3)基于深度学习的预测方法。
深度神经网络[10-15]被广泛应用于需求预测领域且收效良好。Hou 等[16]利用深度神经网络对不同路段的行驶时间进行了预测,使用单模型结构对交通网络中的所有路段进行准确的预测,不必为每个路段分别构建自定义模型,从而降低了建模的复杂度;
Zhan 等[17]提出了一种基于卷积神经网络(Convolutional Neural Network,CNN)的交通流预测方法,使用浮动车的GPS 轨迹数据来估算全市的交通量;
Yu 等[18]提出了时空图卷积网络框架,使用门控循环单元和图卷积进行了长期交通流量预测;
Ma 等[19]提出了一种大规模交通网络速度预测的深度卷积神经网络,将时空矩阵转换为图像作为CNN 的输入。后三者都改进了传统方法中长期预测任务经常忽略时空依赖性的缺点。
4)基于多模型的组合预测模型。
通过将不同的子模型组合,可以发挥每个模型对于不同特征提取的优势,如段宗涛等[20]使用CNN-LSTM-ResNet(Convolutional Neural Network &Long Short-Term Memory &Residual Network)组合模型对出租车需求进行了预测,采用残差神经网络的CNN 框架来分别模拟人群流量的临近性、周期性和趋势特征,使用长短期记忆(Long Short-Term Memory,LSTM)网络学习交通流变化的时空特征,为解决时空序列问题提供了新的思路;
Ke 等[21]利用LSTM 神经网络对天气等具有时间序列信息的特征进行了提取,再结合卷积LSTM 网络对时空特征进行了提取,对比其他单个模型实验,验证了融合模型的有效性。
综上可知,将时空数据应用于网约车需求预测中可取得较好成效,但由于不同类别的时空数据存在结构差异性,使用单一结构的模型较难完整捕捉不同结构、不同城市、不同规模时空数据的隐含特征,因此其预测准确度和鲁棒性仍有提升空间。此外,由于需求预测还存在空间关联性和环境关联性等其他复杂因素,全面完整地利用多维时空数据和深度学习技术对网约车需求进行准确预测仍然非常具有挑战性。针对上述问题,本文对网约车出行的时空需求进行了形式化定义,提出了一种深度聚合神经网络(Deep Aggregated Neural Network,DANN)模型以预测不同时空下的需求热度。通过多个子模型分别学习环境变量、时空变量和空间变量的隐含特征,并将子模型的输出进行多层次聚合得到最终的预测结果。
本文以时空需求热度表示一个空间区域在一段时间范围内的网约车乘客出行需求热度,其详细定义如下。
1.1 基本概念
定义1空间网格。设有给定地理空间区域S,其纬度最大和最小值分别为latmax和latmin,经度最大和最小值分别为lngmax和lngmin,则该空间区域S可被分割为p×q个二维网格,每个网格称为一个空间网格Si,j,其中i∈[1,p]⊂N 且j∈[1,q]⊂N。Si,j的长度hlat=(latmax-latmin)/p,宽 度hlng=lngmax-lngmin。
定义2需求。需求rk=(ek,latk,lngk)为乘客k的网约车出行订单,其中ek为乘客需要服务的时间(如实时出行则ek为当前时间),latk和lngk为乘客出发地纬度和经度。若latmin+hlat(i-1) ≤latk≤latmin+hlati且lngmin+hlng(j-1) ≤lngk≤lngmin+hlng j,则需求rk属于空间网格Si,j。
定义3时空需求热度。将一天的24 h 分割为等长的δ段,每个时段tl(l∈[1,δ] ⊂N)的长度为24/δh。对于每个空间网格Si,j和时段tl,其相应的时空需求热度Pij,l可以定义为空间网格Si,j中在时段tl范围内的需求数量。
1.2 时空需求热度变量
受时间、区域和天气条件等多种外部因素影响,城市不同区域需求热度变化规律复杂;
因此,使用单一变量作为模型输入很难准确预测求密度变化。本文将影响需求热度变化的变量分为外部环境变量、时空变量和空间变量。在外部环境变量方面,月份、日期、星期、时段、是否为节假日、温度条件、气象条件、空气质量均对出行需求有显著影响,故上述类别的12 种因子被选为环境变量。相邻时段、前天同时段、上周同时段的需求热度被选为时间变量特征。大量不同类别的兴趣点(Point Of Interest,POI)信息可从不同层面反映一个空间区域的繁荣程度;
因此,本文以12 种POI 的数量作为空间变量。上述特征的定义及其量化取值范围见表1。

表1 时空需求热度预测特征Tab.1 Features for spatio-temporal demand heat prediction

基于上述特征,时空需求热度的预测问题定义如下。
问题1 时空需求热度预测。根据给定的特征值Xe、Xg和Xs预测tl时刻Si,j区域的时空需求热度Pij,l,其中Xe=(xmo,xda,xtl,xho,xwe,xtt,xht,xwt,xra,xsn,xfl,xap),Xg=(xms,xjd,xyy,xsc,xly,xjs,xyl,xxq,xxx,xcz,xqy,xzf),Xs=(xlp,xlt,xlw)。
本文提出的深度聚合神经网络(DANN)由3 个子单元结构组成,分别为外部环境学习单元的长短期记忆(LSTM)模型、时空特征学习单元的卷积长短期记忆(Convolutional LSTM,ConvLSTM)模型和空间特征学习单元的卷积神经网络(CNN)模型,其总体结构如图1 所示。3 个子网络模型分别处理相应类别的时空数据,并将其输出经多层聚合获得最终预测结果。

图1 DANN结构Fig.1 Structure of DANN
2.1 外部环境特征学习单元
设Xe为外部环境因素的特征向量,由问题1 可知Xe=(xmo,xda,xtl,xho,xwe,xtt,xht,xwt,xra,xsn,xfl,xap)。由于外部环境变量,如日期、节假日、天气、空气污染指数等,都具有时间上下文相关性;
因此本文采用长短期记忆(LSTM)网络单元结构来捕捉其在时间维度的依赖关系。LSTM 在处理与时间序列相关的数据时表现优异,可较好处理长距依赖问题,且通过引入3 个门控神经元可有效缓解梯度爆炸和梯度弥散[22]。
LSTM 单元结构如图2 所示,其内部结构主要由遗忘门、输入门和输出门组成。假定当前时刻为t,xt为输入的外部环境变量向量Xe,yt为输出状态值,为记忆单元,pt为输入门状态值,dt为遗忘门状态值,qt为输出门状态值。遗忘门根据前一时刻的隐层信息yt-1以及当前时刻的输入xt,通过激活函数输出遗忘元素的比率,以及在原始记忆单元中丢失部分信息。输入门pt通过类似的结构筛选出输入数据中需保存至记忆单元的数据,并将其与通过遗忘门之后的记忆单元数据相加作为记忆单元的输出st。最后,隐藏层的数据通过输出门数据与新记忆单元数据进行逐点相乘计算得到yt。记忆单元的状态值由输入门和输出门共同控制。对于每个时间步长t,迭代计算过程如下:

图2 LSTM单元结构Fig.2 Structure of LSTM unit

其中:Wx、Wy分别为各单元xt、yt-1对应权重,b为相应偏置。σ(x)和tanh(x)为非线性主动函数,计算方法如式(7)(8)所示:

2.2 时空特征学习单元
时空需求热度在每日相同时段、每月相同星期存在周期性,因此具有时间自相关性;
此外,其空间网格间也具有空间相关性,因此本文采用卷积长短期记忆(ConvLSTM)单元结构[23]来捕捉其在时间和空间维度的依赖关系。ConvLSTM 将LSTM 单元中所有向量转换为张量,使得LSTM 单元可通过卷积操作进行连接,因此该单元结构既可捕捉时间依赖关系,又可提取空间特征,其结构如图3 所示。

图3 ConvLSTM单元结构Fig.3 Structure of ConvLSTM unit
如图3 所示,ConvLSTM 通过在状态到状态和输入到状态转换中实现卷积算子来计算某个网格单元的时空需求热度。通过t次迭代,每个ConvLSTM 层都可以映射一个输入的需求热度张量X=(X1,X2,…,Xt)到一个隐藏层张量H=(H1,H2,…,Ht)。同样地,堆叠形式的多个ConvLSTM 层会更好地发现需求热度的时空特征,提高本文模型的预测精度。
由定义3可得tl时段不同区域Si,j的时空热度Pij,l,令

假定当前时刻为t,Xt表示时空需求热度输入张量,Ht表示输出张量,Ct表示记忆向量,It表示输入门张量,Ft表示遗忘门张量,Ot表示输出门张量;
◦表示Hadamard 乘法;
*表示卷积操作;
W为卷积核,可提供权重共享。
2.3 空间特征学习单元
本文以区域内POI 数量表述空间特征。需求热度与区域及其周边土地利用模式密切相关,POI 涵盖城市各类设施位置与属性信息,通过多个卷积层可有效捕捉空间隐含特征,如图4 所示。由于高层特征图中的单个节点依赖于中层的多个节点特征映射,依赖于底层(即输入)中所有节点的特征映射,即多层卷积可捕捉较大范围内的POI 与需求热度之间的依赖关系。

图4 CNN结构Fig.4 Structure of CNN
为缓解卷积过程中损失需求细节,本文设计了一种三通道模式,将原始POI 热度图划分为3 个通道分别进行卷积处理,包括:低密度子图(只保留POI 数量小于θ的值)、原密度子图(原始值全部保留)和高密度子图(只保留POI数量大于θ的值),如图5 所示。由于不同通道的网络参数相互独立,此结构可有效降低密度差异性对预测效果的影响。

图5 需求热度图的通道划分Fig.5 Channel partition of demand heat map
2.4 子网络单元聚合
图6 展示了不同日期和不同时段需求总数量的变化情况,可以观察到该值存在周期性波动:在月范围内呈多峰状态,在日范围内呈现单峰状态。这表明时空热度受到近周期片段、日周期片段和周周期片段的影响,但影响程度存在着差异;
同样地,对于空间变量,划分的不同通道对时空热度也存在着不同影响,因此本文采取了基于参数矩阵的融合方式来调整时空热度受不同因素的影响程度。
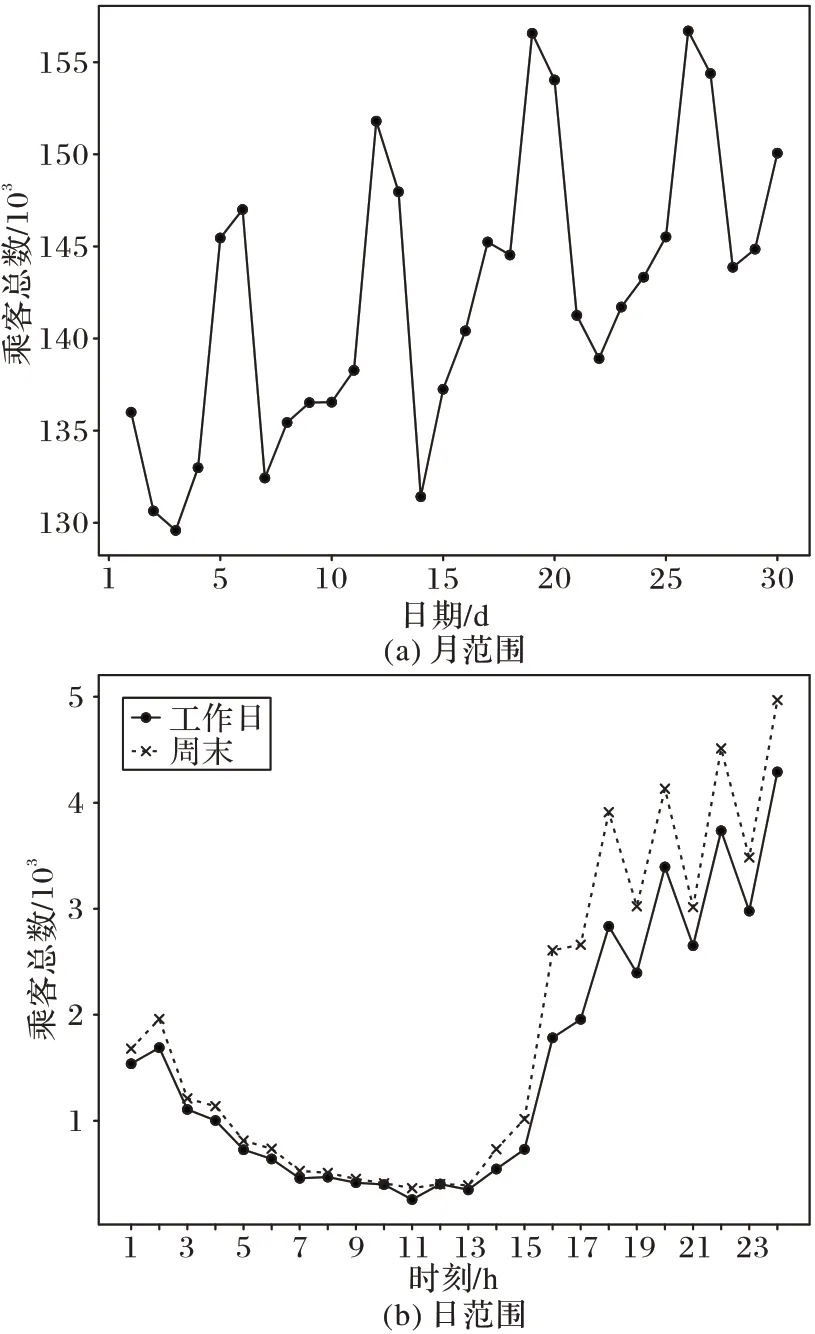
图6 乘客总数量变化示例Fig.6 Examples of total passenger number change
分别将时间特征学习模型的输出和空间特征学习模型的输出以基于参数矩阵的方式融合,如式(15)(16):

其中we、ws、wg为融合权重。
2.5 模型训练
模型训练的目标为使预测值与真实值Pt的均方误差(Mean Squared Error,MSE)最小化,从而获得上述全部权值w的最优取值。目标函数如式(18)所示,其中加入L2 范式正则化项以避免过度拟合,α为平衡参数。模型训练流程如算法1 所示。

算法1 模型训练流程。

本文基于真实数据进行了实验,对算法的预测精度和参数灵敏度进行了验证,实验环境见表2。

表2 实验环境Tab.2 Experimental environment
3.1 数据源和算法参数设置
实验数据源基于滴滴盖亚数据开放计划,采用成都市、西安市和海口市城市区域网约车订单数据,POI 数据通过百度地图应用程序编程接口(Application Programming Interface,API)获取,时空网格划分及乘客分布如图7 所示,数据集具体参数如表3 所示。

图7 区域划分及乘客分布示例Fig.7 Example of region division and passenger distribution

表3 数据集参数Tab.3 Dataset parameters
利用Keras 深度学习框架实验,优化器为Adadelta,DANN 训练参数设置标准为最优预测精度,模型主要结构具体如表4 所示。
表4 中Conv3D 为3D 卷积层,Conv 为2D 卷积层,Maxpool为最大池化层,激活函数如式(19)所示:
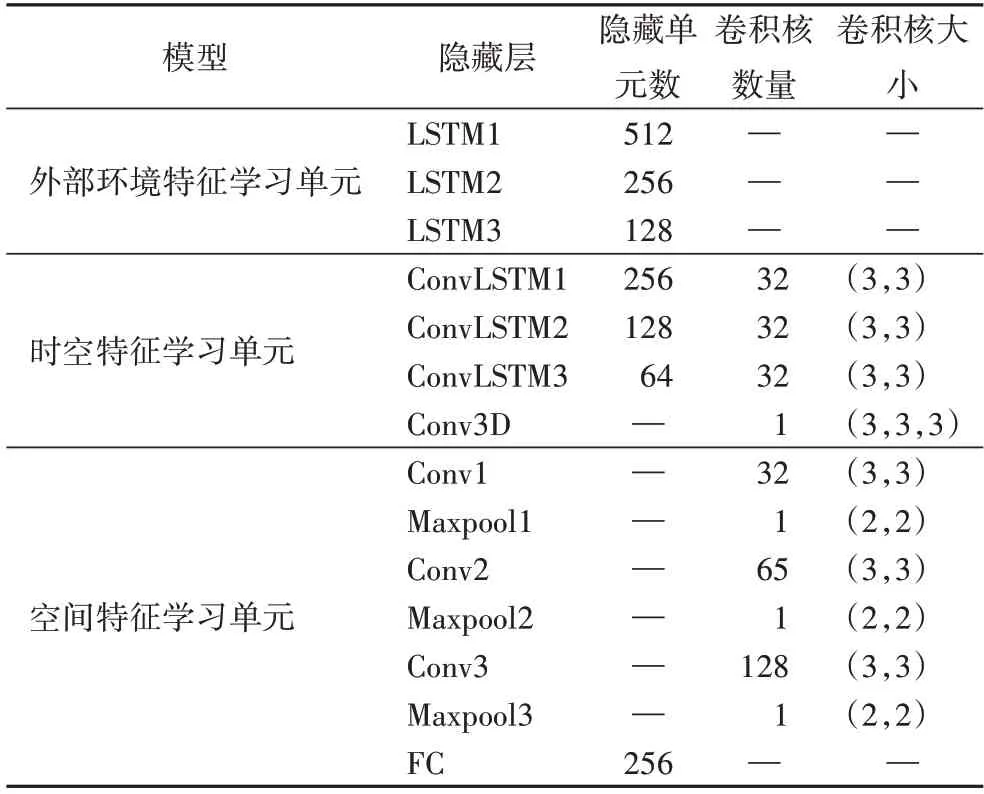
表4 DANN训练参数Tab.4 DANN training parameters

3.2 模型预测精度分析
本文将DANN 与下述8 种模型进行对比,各算法参数设置标准为最优预测精度,其具体值如下。


由于对比模型与本文中使用的特征及数据存在差异,为保证对比的公平性,对比模型进行了部分修改以保证与本文模型的对比条件一致。实验采用均方误差(MSE)、平均绝对误差(Mean Absolute Error,MAE)、R-平方(R2)和可释方差(Explained Variance Score,EVS)作为评价标准,对比实验结果见表5。
由表5 可见,本文模型在上述3 个数据集的4 种指标中均取得最高精度。从整体上来看,由于传统的机器学习算法(即前4 个模型)建模能力有限,考虑的影响因子较少,因此误差较大,3 个数据集的R2平均误差分别为22.83%、21.77%和27.01%;
而深度学习算法(即后5 个模型)相较机器学习算法在3 个数据集上的预测结果上有着较大提升,R2平均误差分别为12.69%、9.43%和13.80%。相较于LSTM,ConvLSTM 在建模时加入了空间特征的提取,因此表现优于前者,R2在3 个数据集上分别提升0.030 7、0.026 3和0.059 2。与FCL-Net模型和HDLN-Net 模型相比,DANN 在加入了空间维度POI 后,可较大幅度提升模型的预测能力,因此准确度优于前面两种方法。与区域预测模型相比,DANN 的优势在于空间特征提取时采取了3 个子模型分别卷积再融合的方式,缓解了卷积过程带来的细节损失,提升了预测的准确度。此外,在时空特征的提取上,本文采取了子模型再融合的方式分别处理了近周期时空图、日周期时空图和周周期时空图,因此DANN 在利用环境变量、时空变量建模的情况下提取到更多有效隐含特 征,其预测精度优于其他对比模型。
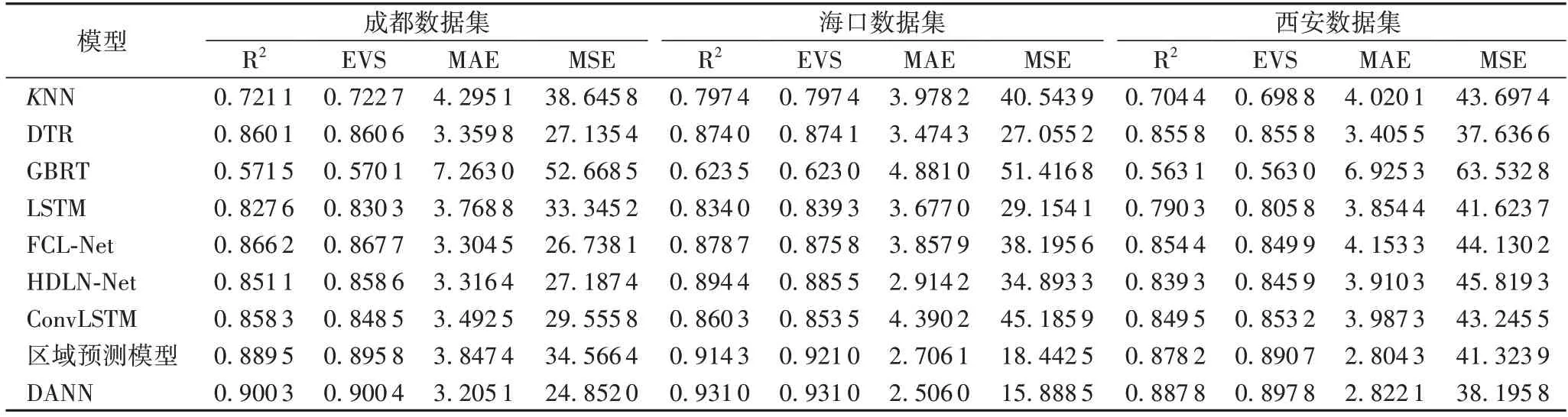
表5 实验结果对比Tab.5 Comparison of experimental results
图8 展示了真实时空需求热度(T)与DANN 预测值(P)的对比结果。图中以灰度表示时间需求热度的差异,较深的颜色代表较高的热度。从图中可以观察到,预测热度与真实热度高度一致。此外,由图8 可知,午高峰时段的需求强度显著高于睡眠时间的需求强度,且需求强度在空间上不平衡,部分网格的需求强度显著高于其他网格的需求强度。随着时间的推移,需求强度在不同的网格变化较明显,使得需求强度预测难度增加,而本文模型结合不同的变量捕获时空特征可以有效解决这个问题。

图8 真实值与预测值的对比Fig.8 Comparison between predicted and real values
3.3 子模型预测结果分析
为更加直观观察不同子模型以及单子模型和多子模型融合后对预测结果带来的影响,以成都数据集为例,在本节对不同的子模型预测结果进行了分析,评价方式同3.2 节,结果如表6 所示。

表6 不同子模型对比实验结果Tab.6 Experimental results comparison of different sub-models
由表6 可见,聚合模型DANN 的R2分别比时空特征学习单元(多模型)、空间特征学习单元(多模型)和外部环境特征学习单元这3 个子模型提高2.63%、12.78%和6.22%,说明聚合模型在预测结果准确度上优于单个子模型。由于聚合模型利用了不同子模型对不同特征提取的优势,因此达到了更好的预测效果;
此外,多子模型融合的结果也优于单子模型,说明基于周期的时空变量和基于图像点值的空间变量划分方法也提高了预测的准确性。
3.4 不同天气下的预测结果比较
为探究不同天气下DANN 的预测结果,将测试样本分别按照天气类型和空气污染指数等级进行分类,计算各类别预测结果的评价值(R2、EVS、MAE 和MSE),得出不同天气条件下的预测精度,其中,空气污染指数分为5 个等级:优、良、轻度污染、中度污染和重度污染,评价结果如表7、8 所示。

表7 不同天气类型下的预测结果Tab.7 Prediction results under different types of weather
由表7 可见,DANN 在大雨天气条件下的误差较大,而在其他天气条件下的波动较小,这说明时空需求在极端天气条件下的变化规律更为复杂。由表8 可见,DANN 在各个空气质量等级的条件下预测结果都较为稳定,误差未出现大波动。综上所述,DANN 在不同的天气类型和空气质量等级下的预测效果均较为稳定且精度较高,因此可用于不同天气条件下的时空需求预测。

表8 不同空气质量等级下的预测结果Tab.8 Prediction results under different air quality classes
3.5 模型灵敏度影响分析
以成都数据集为例,对本文模型的结构和参数进行了分析。图9(a)显示了迭代次数对实验精度的影响。如图9(a)所示,R2在初期显著增加,然后趋于平缓,说明该网络最开始有较高的收敛速度,随着训练次数的增加达到平稳状态,而训练40~80 次的效果差异性较小。
图9(b)展示了网络层数的影响:随着网络层数增大,模型的R2 先增大后减小,说明网络层数越深预测效果也会越好;
但当网络层数过深时,模型会变得很复杂,这时往往容易出现欠拟合现象,因此预测效果逐渐变差。卷积视野的范围由所使用的卷积核大小决定的。在这里改变卷积核的大小从2×2 到5×5,从图9(c)可以看到,3×3 的卷积核具有较高的R2,表明其具有更好的空间依赖建模能力。从图9(d)中可以看出卷积核数量为128 时得到的结果更好。

图9 参数调整与灵敏度分析Fig.9 Parameter adjustment and sensitivity analysis
最后,对多步预测进行了敏感度分析,图10 表明,R2的最小值高于0.86,优于其他对比模型。同时,R2的值缓慢下降,没有出现较大波动,表明该方法可以较好地适应多步预测任务。
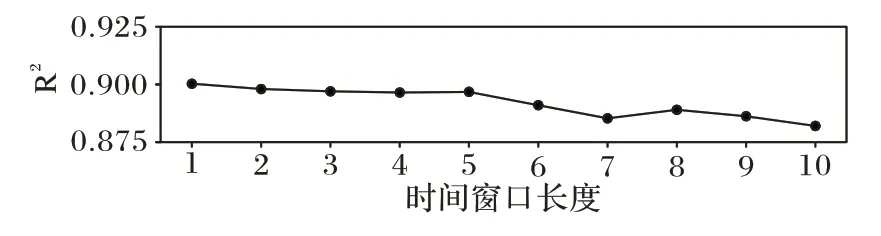
图10 多步预测敏感度分析Fig.10 Sensitivity analysis of multi-step prediction
本文为准确预测网约车需求,针对差异化结构的多维数据,提出了一种深度聚合神经网络模型。该模型综合考虑了环境变量、时空变量等多维影响因素,提出了基于周期的时空变量和基于图像点值的空间变量划分方法;
依据数据特点构建了不同的子神经网络结构并提出了多种异类子神经网络的聚合方法及聚合权重的设置方法。本文模型可作为网约车需求预测的有效手段,预测结果可有效解决服务车辆与乘客间的供需不平衡问题,提升服务车辆的运营效率和利润,同时降低乘客等待时间并改善其对服务平台的满意度;
但需要指出,深度学习模型对训练数据量要求较高,且其预测结果的因果可解释性存在一定限制。未来研究将通过优化模型网络结构进一步提升预测能力,并探索具有更好可解释性的机器学习方法。