王晓明,王 莹
1.西安外国语大学 科研处,西安 710128
2.西安外国语大学 研究生院,西安 710128
3.西北工业大学 计算机学院,西安 710072
阅读眼动是人在阅读文字时的眼球运动行为,由一系列注视和眼跳组成,是人类语言认知过程的外显[1]。当前,人的认知行为研究方兴未艾,而阅读眼动建模是语言认知科学的研究热点[2]。从研究角度看,进行阅读眼动模型构建研究,会促进语言认知科学和阅读行为科学的发展。从应用角度看,阅读眼动可计算模型在机器视觉、自然语言处理、身份识别等领域都有重要的应用价值[3]。
已有的阅读眼动可计算模型归为5类,即:基于认知注意力转移[4-10]、基于视觉神经生理参数估计[11-14]、基于语言概率推理[15-19]、基于概率图模型[20-25]和基于神经网络的阅读眼动可计算模型[26-31]。然而,现有模型建模方法普遍较复杂,模型所需特征较多。为了解决这一问题,本文突破传统阅读眼动模型注视粒度处理和回视处理模式,提出阅读眼动注视序列标注方法,以构建简单模型,并通过最大熵马尔可夫模型[32](maximum entropy Markov model,MEMM)验证所提出模型的有效性和易实现性。
光在经过眼球的光学介质(角膜、晶状体、玻璃体)后要通过其他各层神经细胞,最后到达光感受器——这是视网膜中唯一对光敏感的细胞。光感受器按其细胞外段呈杆形或锥形,可分为视杆细胞和视锥细胞[33],统称为视细胞。视锥细胞主要负责昼光觉,有色觉,光敏感性差,但视敏度高。视杆细胞对暗光敏感,光敏感度较高,但分辨能力差,在弱光下只能看到物体粗略的轮廓,并且无色觉。
视杆细胞主要分布在视网膜中心周围,如图1所示[34]。人类视网膜平均有约12 500万个视杆细胞。1个光子就足以激发视杆细胞的活动,它对单个光子的敏感程度是视锥细胞的100多倍。也因此视杆细胞建立人类在夜晚最基本的视觉、暗视觉。视锥细胞则需要数十到上百个光子的激发。视网膜上的视锥细胞大约有600~700万个,主要分布在黄斑(macular)区。黄斑是人眼视网膜中央附近一卵圆形染色区域,直径约5.5 mm。视网膜在黄斑区的呈凹陷状态,形成中央凹(foveal)。黄斑之中的中央凹和黄斑凹都含有高密度的视锥细胞。黄斑的结构特点是高敏锐度视力的基础。这种结构特点有助于改善视网膜成像的清晰度和提高空间分辨能力。

图1 视杆细胞和视锥细胞在视网膜上的分布示意图Fig.1 Distribution of rod cells and cone cells in retina
一般来说,人的视觉区域中,中央凹视觉区能够提供高清晰的视觉,处在这个区域内的景物才可以被人看清楚,其他区域的景物都是模糊的。而这个能够提供高清晰视觉的中央凹区域仅覆盖了有限的约2°的视觉区域。相当于人在正常情况下,伸展手臂时的距离下,仅能看清一个指甲盖区域的范围。
为了能够看清楚视野范围内的所有景物,人眼需要通过连续地转动,以便将中央凹视觉区对准感兴趣的区域,这就是眼动的生理学原理。眼动的速度非常快,人们不会意识到,但心理学家100多年来,已经做了无数的实验确认了这个运动的细节。
眼动追踪(eye-tracking)是指通过测量眼睛的注视点的位置实现对眼球运动(eye-movements)的追踪。人们在阅读时,注视点并非平滑地划过所有文字,而是由注视(fixation)和眼跳(saccade)组成。一般注视的时间大于100 ms,典型的注视只持续0.1~0.5 s。
眼动轨迹图描述的是读者阅读文字时的眼睛运动轨迹,一般用圆圈表示注视,用线表示眼跳方向,如图2所示,这样在眼动轨迹图中,研究者既可以看到注视又可以看到眼跳。

图2 阅读眼动轨迹图(维基百科,Javal发表于1879年)Fig.2 Reading eye-tracking diagram(Wikipedia,Javal,1879)
为了更好地理解和认知人在阅读时的眼动轨迹规律,研究者构建了各式各样的阅读眼动模型,这些模型把文本作为输入,生成与人类阅读行为近似的注视时间和注视位置。然而,这些模型普遍较复杂,不易于用机器学习模型实现。
2.1 基本描述
本文将阅读眼动过程视为读者在文字上标注注视词的过程,将复杂的阅读眼动建模任务转化成了更加容易建模的序列标注任务。该任务的输入是一个线性文本序列,需要给线性文本序列中的每个元素(单词)打上标签集合中的一个标签,其中,标签集合仅有两个元素:{Fixation,Skip}。如果一个单词被标注为“Fixation”,则表示该单词在阅读过程中被“注视”;
同理,如果一个单词被标注为“Skip”,则表示该单词在阅读过程中被“跳过”。
对于一个文字序列“Kate quivered and went to the window”,经过阅读眼动注视序列标注处理之后,输出的标注序列为“Fixation,Fixation,Skip,Fixation,Skip,Fixation,Fixation”,如图3所示。可以看出,输出的标注序列与原文字序列同长。

图3 阅读眼动注视序列标注任务示例图Fig.3 Example diagram of reading eye-movement fixation sequence labeling task
在传统语言序列标注任务中,正确标注结果可能仅存在一个或几个,例如正确的分词、正确的词性标注、正确的命名实体识别。与传统序列标注任务不同的是,对于阅读眼动注视序列标注任务来说,因为每个人的眼动模式是不同的,所以并不存在一个唯一正确解。也就是说,即使对于同样一段文字,标注结果也会因人而异。
2.2 形式化描述
让R表示一组读者集合,单个读者r∈R。T表示词序为(w1,w2,…,wn)的文本。对于每个r∈R,根据T中的每个单词产生一个注视序列FRAW,FRAW服从:

这里的p(FRAW|T,r)是一个特定受试者阅读一段文本时的眼动模式分布。例如,有文本“Kate quivered and went to the window”,被表示为T=(Kate,quivered,and,went,to,the,window),一个可能的注视序列FRAW记为(Kate,quivered,and,Kate,quivered,went,the,win‐dow),相应的位置序列为(1,2,3,1,2,4,6,7)。以单词所在的矩形划分区域,与FRAW相对应的区域位置集合为{1,2,3,4,6,7}。对于所有的区域,若有注视点落入该区域,则该区域标记为1,否则标记为0,以IA表示区域标记序列,则相应的IA为(1,1,1,1,0,1,1)。IA的元素个数与T相同。
在做基于阅读眼动序列标记预测时,假设M是一个可计算眼动模型,给出一个文本序列T,读者r阅读T时的眼动注视序列f由推算出:

为了便于模型进行数据处理,使用IA序列代替FRAW序列,同时引入与T相对应的若干关于T的语言学特征序列A1,A2,…,An(n∈N),则An的长度与T相同,此时,所求的目标变为:

2.3 方法的合理性分析
研究者在以拼音文字为实验材料进行的眼动研究中发现,在阅读过程中,当读者注视某一个单词时,注视点往往落在该单词的开头与中心部分的中间位置,也就是大概在该单词开头的1/4处。该位置通常是读者的注视点首次落在某个单词的位置,因此被研究者们称为偏向注视位置(preferred viewing location,PVL)[35]。偏向注视位置描述的是注视点停落最多的位置,其分布近似高斯分布[36]。对于拼音文字来说,偏向注视位置的发现支持了读者的眼跳目标是以词为单位的观点,即读者在阅读过程中下一次眼跳选择的目标是单词,而不是字母[37]。受认知心理学上述研究启发,在本文所提出的阅读眼动注视序列标注任务中,规定任务所处理的元素粒度是单词(word)而非字符(character)。
在阅读过程中,读者通常会在文本上前向移动眼球,以获得新的视觉信息并进行处理。这些眼动是必需的,因为中央凹视觉区仅占视野的很一小部分,所以,每次注视仅能提取到一定量的信息[38]。但是,并非所有的眼跳都沿文字前向方向进行,有时也会跳回到已经阅读过的文字,对文字进行重新加工以获取信息,这种眼动现象称为回视(regression)。回视是为了满足对文字的理解需求而产生的,可以使读者纠正对文字的误解或理解缺失[39]。回视产生的原因与阅读材料难易程度,读者对阅读材料的熟悉度,读者的阅读习惯,读者的阅读环境,阅读任务的具体要求等因素都有关[40]。尽管产生回视的原因诸多,但有一点可以肯定:回视并非是一种好的现象,因为它降低了阅读的效率。高效的阅读者应该尽量避免或减少阅读回视次数。对于熟练读者,回视次数占总注视次数的不到10%[41],而本文所开展的研究基于阅读眼动语料库,被试恰恰均为熟练阅读者,所以,不考虑回视现象对所提出的阅读眼动注视序列标注任务模影响不大。
综上,本文提出的阅读眼动注视序列标注方法存在以下两个新模式:
(1)在基于单词的阅读眼动注视粒度处理模式中,处理粒度基于单词(word)而非字符(character);
(2)在基于熟练读者的阅读眼动回视处理模式中,不考虑阅读过程中的回视(regression)现象。
3.1 数据集
本文在模型构建工作中基于Provo语料库[42]评价不同可计算模型的效果,原因是Provo语料库规模较大(20万词量级)[43]。Provo语料库是一个英语眼动语料库,2018年发布。阅读材料包括55篇短文,内容涵盖在线新闻、科普杂志和通俗小说等题材。眼动数据采集所用的设备是SR Research EyeLink 1000 Plus眼动仪,以1 000 Hz采样频率记录右眼眼动数据。表1是Provo语料库中的关键变量。

表1 Provo语料库中的关键变量列表Table 1 List of key variables in Provo corpus
3.2 评价指标
阅读眼动注视序列标注任务,其实是一个把输入的文本序列根据上下文对当前文本进行分类的问题,因为输出空间仅有两个元素——注视和眼跳,所以更进一步,这是一个二分类问题。对于分类问题,准确率是最直观的一个评价指标,但是,在结果标签分布不均的情况下可能会出现问题[44]。例如,在实际阅读过程中,读者注视的单词要远多于被跳过的单词,有统计表明一段文字90%的单词在阅读时都被注视,如果模型仅简单地把所有的单词都标注为注视词,这种简单粗暴的做法使模型的准确率仍然达到了90%,这显然不合理。因此,实验评价指标使用兼顾精确率和召回率的F1分数(F1-Score)。
3.3 实验平台
本文的实验基于Python3.7+TensorFlow1.13+Keras2.2.4开展,实验相关代码可从网址https://github.com/wxmgo/eye_movement_in_reading/下载。实验平台相关介绍如下:
Python是一种解释性的高级编程语言,它有很多科学计算库,特别是一些高效的机器学习代码库,大大方便了研究者。
TensorFlow是一个免费的开源软件库,可用于神经网络机器学习。TensorFlow是Google Brain的第二代系统。TensorFlow可在64位Linux、macOS、Windows以及包括Android和iOS在内的移动计算平台上使用。其灵活的体系结构允许在各种平台(CPU,GPU,TPU)之间以及从台式机到服务器集群再到移动设备和边缘设备的轻松部署计算。在TensorFlow上的数据被称为张量(Tensors),有状态的数据在其上流动产生计算结果——这就是TensorFlow的名称来源。
Keras是在TensorFlow、CNTK或Theano之上的框架,它最大的特点是易用性,而且这种易用性并不以降低灵活性为代价。Keras也被认为是一个接口,而不是一个独立的机器学习框架。Keras开发主要由Google支持,而Keras API打包为tf.keras封装在TensorFlow中。微软也向Keras添加了CNTK后端,可从CNTK v2.0开始使用。
4.1 实验过程
为了证明本文所提出的阅读眼动注视序列标注任务的易实现性,下面使用最大熵马尔可夫模型来实现本文所提出的序列标记任务。实验基于Provo语料库开展。
在HMM中,观测序列由隐藏状态序列生成,在序列标注任务中寻找以最大概率生成指定观测序列的隐藏状态序列,HMM-viterbi计算观测序列和隐藏序列的最大联合概率。λ是模型参数。

而MEMM作为判别模型直接给出目标状态序列。

MEMM可定义更复杂的特征,在HMM-Viterbi查找序列标注时当前隐藏状态和上个隐藏状态相关,假定各观测状态之间互相独立,观测状态是生成目标,并不便于定义更多特征条件。

在MEMM中并不要求各观测状态独立,可使用特征函数对条件ot定义更复杂的分类特征(例如,大小写、上下文字符)。
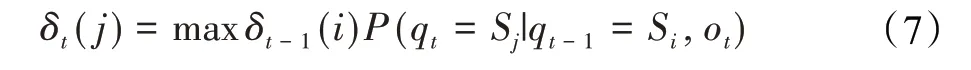
与HMM-viterbi类似,定义两个函数用于保存每个步骤的最大概率和最佳前驱状态。然后从前向后递归,最后回朔状态序列。但这里和HMM不同的是将联合概率定义为条件概率。

第一步,此时q0=0,本文认为,没有上一个隐藏状态本身就表示一种特殊状态(序列开始状态)

第二步,递归

第三步,回溯和结束。
4.2 实验结果
表2显示了使用Provo语料库基于最大熵马尔可夫模型进行阅读眼动注视序列标注的实验结果。实验所用的数据是1~3号被试的阅读眼动数据。从实验结果可以看出,随着迭代次数的增多,标注正确的注视词次数越来越多。

表2 基于MEMM的阅读眼动序列标注实验结果Table 2 Experimental results of reading eye-movement sequence labeling based on MEMM
与HMM相比,MEMM的最大优点是它在选择表示观察结果的特征方面提供了更大的自由度。在序列标记的情况下,使用领域知识来设计特殊用途的功能很有用。MEMM的缺点在于存在标签偏差问题(label bias problem),其中具有低熵跃迁分布的状态有效地忽略了它们的观察结果。
4.3 结果分析
本文还将MEMM同HMM和MEM模型做了对比,在四个性能指标上的比较结果如表3所示。

表3 四种性能指标对不同模型的评价结果Table 3 Evaluation results of four metrics on different models 单位:%
分析表3可以得出,与其他两个序列标注模型相比,本文提出的基于最大熵马尔科夫模型(MEMM)的注视词序列标注方法具有70.24%的召回率和69.90%的精确率,召回率和精确度均有高于另外两个模型。此外,F1值为70.08%,在三个模型中值最高,说明该模型表现出了更好的稳定性。从而进一步说明,将两种模型结合使用的注视词序列标注效果比单独使用隐马尔科夫模型(HMM)或是单独使用最大熵模型(MEM)更好。
4.4 与最新方法对比
2019年,VRIES[28]使用Provo阅读眼动语料库训练训练RNN模型和Rescorla-Wagner模型,以实现根据前一个词的词性标签预测Penn树库句子中的词性标签。两种模型预测都显示出与人类预测相似的偏向某些常见词汇类别的倾向。为了用模型结果解释人类预测误差的差异,将普通最小二乘法(OLS)模型拟合到结果上。估计量包括词性标签、词长和模型输出,RNN模型和Rescorla-Wagner模型的输出对OLS模型有显著贡献。使用本文所提出的模型,同样在Provo阅读眼动语料库上预测Penn树库句子中的词性标签。
2019年,Elsayed[29]提出了一种端到端的深度学习阅读眼动模型架构,引入了一个称为分位数层(quantile layer)的参数化统计聚合层,该分位数层使网络能够明确地拟合过滤器激活的分布。该体系结构由一维卷积滤波器的深层布置组成,这些滤波器从原始眼动信号中提取局部的短期模式,然后是分位数层,其输出表征了这些分布模式。作者设计分位数层的方式可以概括全局最大值、中位数和最小值。由于作者假设短期模式的分布信息最丰富,因此使用标准的非卷积卷积运算,而不是最近用于对时间序列中的更多长期模式进行建模的散卷积运算。本文使用与ELSAYED19模型完全相同的数据集和数据划分方法。
2020年,Jothi等人[31]提出了一种基于眼动行为的阅读障碍的预测模型。作者提出了一组小范围的眼球运动特征,这些特征有助于通过机器学习模型区分阅读障碍者和非阅读障碍者。作者使用统计方法、离散度阈值识别(I-DT)和速度阈值识别(I-VT)算法检测与眼球运动事件相关的特征,如注视和眼跳。利用基于粒子群优化(PSO)的SVM混合核(Hybrid SVM-PSO)、支持向量机(SVM)、随机森林分类器(RF)、Logistic回归(LR)和K-最近邻(KNN)等多种机器学习算法对这些特征进行了进一步的分析。实验结果表明采用SVM-PSO混合模型的预测精度为71.42%。提供高精度的最佳特征集是平均注视次数、平均注视持续时间、平均扫视运动持续时间、扫视运动总次数和平均注视次数等5个特征。
本文的方法与基于VRIES19、ELSAYED19、JOTHI20的实验结果对比见表4。从表4可以看出,在阅读眼动注视词标注任务上,所使用的基于最大熵马尔可夫模型的阅读眼动注视序列标记方法,尽管对眼动过程做了简化处理,仍然取得了与复杂模型相近的准确率和F1值。

表4 本文方法与最新方法的实验结果对比Table 4 Comparison of experimental results between proposed method and the latest method单位:%
同时,本文的方法是基于简化模型,模型使用了较简单的架构和较少的特征,因此使用较少的迭代次数就能达到收敛,在迭代次数和总的收敛时间上都明显优于其他模型,相关对比优势见表5。

表5 本文方法与最新方法的对比优势Table 5 Comparative advantages of proposed method and the latest method
综上,尽管本文的方法没有达到最新方法的预测精度,但该模型的优势是使用较少特征和较简单的模型,就能取得与最新方法相近的性能,模型在易实现性以及运算成本等方面的优势使其在工程应用领域具有一定价值。
4.5 讨论
本文通过引入基于单词的阅读眼动注视粒度处理模式和基于熟练读者的阅读眼动回视处理模式,对阅读眼动建模任务进行了简化处理,在阅读注视词标注任务上,可以实现使用较少特征就能取得与现有眼动模型相似的准确率。该方法仅在实验条件下取得成功,实验所使用的数据来自于经处理过的阅读眼动语料库。这些语料库由专业人士构建,数据采集对象是熟练读者(有熟练的阅读技能,但对语料本身不熟悉),因此,整个语料库的回视次数较少。在实际的阅读环境中,读者未必都是熟练读者,因此需要明确适用该模型的限制条件,主要包括两个方面:(1)对被试的限制性条件,即被试需为有着良好阅读技巧的熟练读者;
(2)对阅读眼动的回视次数限制性条件,即回视次数不能过多。未来需要进一步细化这两个限制性条件的具体参数。
本文把阅读眼动行为视为读者在文字上进行注视序列标注的过程,并给出了阅读眼动注视序列标注任务的具体描述和形式化描述。为了简化阅读眼动模型,本文对阅读眼动注视序列标注任务做了两个限制:(1)处理粒度基于单词(word)而非字符(character);
(2)不考虑阅读过程中的回视(regression)现象。通过在最大熵马可夫模型上实践,证明了该方法可以较好地描述阅读眼动任务,并且较易用机器学习模型进行实现。
本文实验基于拼音文字开展,未在中文等非拼音文字上应用,原因之一是我国在眼动基础数据方面较欠缺,缺少以中文为语料的阅读眼动数据集。未来应尝试构建中文阅读眼动语料库,在此基础上,扩展所提出模型应用的语种范围。
本文所提出的方法中,序列标注标签集合仅有两个元素Fixation和Skip,分别代表注视词和跳视词,未来需要结合阅读眼动数据的特点,引入注视时长(duration)、回视(regression)等至少两个元素,使本文所提出的模型不仅可以用于阅读注视词序列标注,还可以用于阅读注视行为预测。
猜你喜欢 眼动语料库单词 基于眼动的驾驶员危险认知汽车实用技术(2022年7期)2022-04-20基于ssVEP与眼动追踪的混合型并行脑机接口研究载人航天(2021年5期)2021-11-20平行语料库在翻译教学中的应用研究文化创新比较研究(2020年13期)2021-01-14《语料库翻译文体学》评介天津外国语大学学报(2020年1期)2020-03-25单词连一连阅读(快乐英语高年级)(2020年8期)2020-01-08海豹的睡眠:只有一半大脑在睡觉大自然探索(2019年7期)2019-12-13看图填单词智慧少年·故事叮当(2018年11期)2018-05-14静止眼动和动作表现关系的心理学机制天津体育学院学报(2016年3期)2016-12-18Playing with / i? /小学生时代·大嘴英语(2014年9期)2014-11-04语篇元功能的语料库支撑范式介入外语教学理论与实践(2014年4期)2014-06-13