李 扬,腰彩红,高冠群,王建春
(天津市农业科学院 信息研究所,天津 300192)
我国是世界草莓属植物种类分布最多的国家,草莓种植面积超13万hm2,年产量超200万t,产值达300亿元。在我国北方,温室栽培环境下,草莓通常在每年9月定植,1月初成熟,生长期一直持续到次年5月。草莓按次序先后开花结果,造成果实的不定期成熟,即同一时期可能有多种状态的果实同时存在,需要人工不定期判断、采摘。如果错过采摘最佳时机,容易导致草莓过度成熟,甚至腐烂,影响收益。因此,采摘在草莓生产过程中的人力消耗较大[1],在草莓生产环节占有重要地位。
目前草莓采摘主要靠人工完成,周期长、次数多、劳动强度大、成本高[2]。近年来,人工智能的发展为草莓采摘自动化提供了可行性,而草莓的自动识别,则是机器采摘的前提,通过算法准确识别成熟草莓已经成为了研究热点,研究重点主要在模型的准确度和检测效率两方面。
检测模型准确度方面,科研人员已经取得了较好的效果。赵玲等[3]研究了在HIS颜色空间模型下的草莓成熟度识别,准确率达到90%以上,为草莓成熟程度判断提供了方法。刘晓刚等[4]针对白天、傍晚、夜晚3个时间点,采用基于YOLO v3的方法实现了复杂环境下成熟草莓的检测,mAP(平均精度均值,Mean Average Precision)达到87.51%,取得了较好的识别效果。Chen等[5]使用无人机从顶部拍摄草莓图像,使用深度神经网络对草莓果实进行检测和产量预估,检测准确率达到了84.1%。Zhang等[6]采用Faster R-CNN检测框架对草莓植株的低空遥感图像进行检测训练,用来对草莓生长健壮程度进行评估。Lin等[7]提出了基于草莓花的数量进行产量预估的方法,使用Faster R-CNN对草莓花进行检测,准确率达到了86.1%。在目标检测方面,现有的成果主要基于成熟草莓进行检测,偶有对花期、植株进行检测的,主要面向采摘应用,缺少对不同生长期草莓的检测。
检测效率是目前科研人员关注的另一重点,只有高效的检测模型,才能够最终在实际生产中得以应用。马瑛等[8]研发了基于ARM和FPGA智能控制模块及双目机器视觉技术的草莓采摘机器人成熟果实及避障控制系统,当果实轮廓存在1/2以上时,该系统可以很好地识别出成熟果实目标,相对误差在2.5%以下,具有一定的参考价值。李长勇等[9]设计了基于STM32F103vet6芯片的机器人,使用双目定位识别,成熟草莓识别率达到95%以上。谢志勇等[10]提出一种基于Hough变换的成熟草莓识别方法,当成熟草莓轮廓信息丢失小于1/2时,无论单个分离的成熟草莓,还是被遮掩、重叠或紧靠的成熟草莓,皆有很好地识别效果,识别平均相对偏差为4.8%,能满足草莓采摘机器人对目标识别精度的要求。丘强等[11]设计出一款草莓采摘车,实现了采摘时对草莓成熟度识别、自动采摘及位置移动等功能。Zhang等[12]改进了YOLO v4-tiny模型实现了对成熟期草莓的检测,检测精度比YOLO v4-tiny低了0.62%但检测速度提升了25.93%,并在Jetson Nano上验证了检测效率,达到了25.2FPS,可以满足实时性需求。
综上,现有的研究成果大都是以成熟草莓为识别对象,对不同生长阶段的草莓进行检测的研究较少。事实上,花期和未成熟的草莓数量是农户决定如何开展生产管理和预估下一次采摘时点的关键,而针对不同生长阶段草莓的识别,是可以伴随着采摘机器人同步识别完成的。因此在识别成熟草莓的基础上,进一步开展基于嵌入式环境的不同阶段草莓生长期果实识别,对于草莓采摘、生产管理和产量预测都具有十分重要的意义。本文以温室土壤栽培草莓为研究对象,构建了多阶段草莓检测模型,实现了对各个生长期的草莓检测,为草莓生产管理机器人的研发奠定基础。
1.1 试验材料
天津市北辰区鼎牛农业园2号日光温室,种植草莓品种为‘红颜’。
1.2 数据采集
本研究使用轨道式移动车(图1)模拟机器人采集视角,采集距离固定为30 cm。数据采集于温室中不同位置共计10畦草莓的生产视频,每隔7 d采集1次,共采集到视频80个。

图1 轨道式移动车
1.3 数据分割
使用Python对采集到的视频进行分割,每一段视频拆分为15张图片,共拆分1 200张图片。
1.4 数据处理
使用LabelImg按照花期、幼果期、青果期、膨大期、转色期、成熟期6个阶段对图像进行标注。其中,成熟期草莓为红色着色面积超过70%的草莓。标注结果如图2所示。按照8∶1∶1的比例将标注好的数据随机分配为训练集、验证集和测试集,分别包括960、120、120张。

图2 草莓图像标注
1.5 检测方法
目前目标检测任务主要包括两阶段(Twostage)模型和单阶段(One-stage)模型2类。经典的两阶段模型如Fast-RCNN、Faster-RCNN等,检测精度高,但检测速度慢,对硬件要求较高。单阶段模型相比两阶段模型,精度略低,但检测速度快,推理时对硬件要求相对较低,更适合嵌入式应用场景,现阶段主要的模型包括YOLO、SSD等。针对采摘系统的目标检测任务是典型的嵌入式应用,需要综合考虑检测精度与速度,因此单阶段模型更适合此任务场景。YOLO系列算法是现阶段应用最广泛的目标检测算法,其中YOLO v5是目前较新的YOLO版本之一,保持了YOLO系列的整体架构,包含输入(Input)、骨干网络(Backbone)、颈部(Neck)和检测头(Prediction)4个部分。根据网络深度和宽度的不同,主要分为5种,包括:YOLO v5n、YOLO v5s、YOLO v5m、YOLO v5l、YOLO v5x。其中YOLO v5n和YOLO v5s模型较小,主要面向嵌入式环境使用,而YOLO v5m虽然模型略大,但随着新的嵌入式设备的不断开发、升级,也可以应用在嵌入式设备中,因此本次目标检测任务主要使用YOLO v5n、YOLO v5s和YOLO v5m版本进行试验效果对比。
YOLO v5模型架构如图3所示,其中输入为草莓图像,通过马赛克(Mosaic)数据增强后的组合图像。马赛克数据增强方法是将多张图像通过缩放、剪裁、拼接等处理形成一张图像,作为模型的输入,可以有效提升模型的训练速度和网络的精度。同时YOLO v5使用了一种自适应锚框计算与自适应图片缩放方法,简化了原先使用YOLO v4时需要单独使用Kmeans算法进行初始锚框计算的步骤。

图3 YOLO v5模型架构
YOLO v5的骨干网络和颈部主要通过CBL结构、CSP1结构、CSP2结构、SPPF结构、拼接操作(Concat)和上采样操作(UpSample)构成。其中CBL结构是由卷积、归一化和Leaky激活函数构成的组合。CSP1和CSP2结构均为CSPNet的改进版,二者结构图如图4所示。SPPF结构如图5所示,由卷积、多个最大池化和拼接操作构成。YOLO v5模型通过调节CSP1和CSP2的深度和宽度倍数构建不同版本的模型。
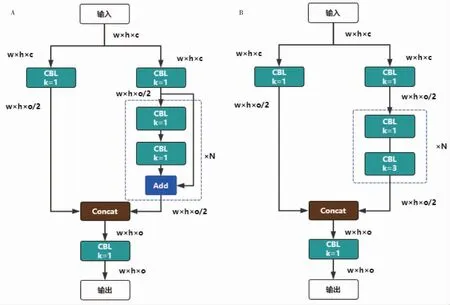
图4 CSP结构

图5 SPPF结构
YOLO v5的检测头部分损失函数包括3个部分,边框损失(Bounding box loss)、分类损失(Class loss)和目标损失(Object loss)。对于一个模型预测出的边界框,它与样本真实边界框的交集和二者并集之比称为交并比(Intersection over Union,IoU),如公式(1)所示。

式中,B为预测框;
Bgt为真实框。最初的YOLO系列算法使用IoU计算边框损失,在后续的YOLO版本中,陆 续 引 入 了GIoU(Generalized IoU)、DIoU(Distance IoU)和CIoU(Complete IoU),对于模型识别效果有较大的提升。YOLO v5的边框损失默认为CIoU,较之前的IoU,考虑了重叠面积、中心点距离、长宽比3个方面对于边框损失的影响。在CIoU基础上,Zhang等[13]进一步考虑了宽高分别与其置信度的真实差异,将纵横比拆开,提出了EIoU(Efficient IoU),并且加入Focal聚焦优质的锚框。Gevorgyan[14]提出了一种新的损失函数SIoU(SCYLLA-IoU),考虑了所需回归之间的向量角度,并重新定义了惩罚指标。Heo[15]提出了Alpha-IoU,对小数据集和噪声较大数据集有较好的效果。本文使用CIoU、EIoU、SIoU和Alpha-IoU和YOLO v5n、YOLO v5s和YOLO v5m构成了12种模型,并对比其检测效果,相应计算公式如下。

式中,b、bgt分别为预测框和真实框的中心点;
c为预测框和真实框之间的最小外接矩形的对角线距离;
w、h、wgt、hgt分别为预测框和真实框的宽、高;
cw、ch为以预测框和真实框中心点为对角线的矩形的宽和高;
cx、cy是预测框或真实框的中心点坐标ρ为欧氏距离。
分类损失采用交叉熵损失函数(Binary cross entropy loss,BCELoss),BCELoss计算公式如下:
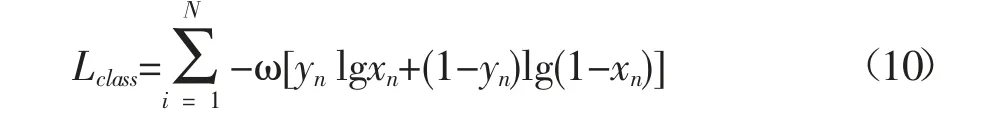
式中,N为一次训练的样本数;
xn表示第n次输入的预测值;
yn表示第n次输入的实际值;
ω相关系数,取值为1/N。
目标损失采用BCElogitsLoss(Binary cross entropy),其公式如下:

1.6 评价指标
精度P(Precision)、召回率R(Recall)和mAP是目标检测常用的评价指标,需要使用混淆矩阵进行计算,混淆矩阵如表1所示。

表1 混淆矩阵
以成熟期果实为例,真正例(True Positive,TP)是指预测类别和位置IoU都超过阈值,预测正确的结果,如图6-A所示。假正例(False Positive,FP)包括类别错误FP和定位错误FP,分别指预测类别小于阈值但预测框与真实框IoU大于阈值和预测类别大于阈值但预测框与真实框IoU小于阈值的情况,如图6-B和6-C所示。假反例(False Negative,FN)则是指漏检的情况,如图6-D所示。而真反例(True Negative,TN)则是对于成熟期这一类别,其他类别的预测框,如图6-E所示的青果期预测框,对于成熟期这一真实框来说是真反例。

图6 检测结果分类
通过以上定义可以计算出精度和召回率,如公式(13)和公式(14)所示。

某一类别的平均精度(Average Precision,AP)就是该类别的PR曲线下所包围的面积,如公式(15)所示。

mAP就是每个类别下AP的均值,如公式(16)所示。

mAP@0.5是指IoU≥0.5时的mAP值,本研究主要使用mAP@0.5评价模型效果。
2.1 训练及嵌入式环境
模型训练平台使用Intel○R Xeon○RE5-2620 v2(6核2.10 GHz)处理器,GPU为NVIDIA○R GeForce RTX 2080Ti显卡,显存为11GB;
操作系统为CentOS 7.9;
运行环境为Python3.8,、Pytorch1.9.1、Cuda10.2。
模型训练完成后的推理过程在Jetson Nano和Jetson Xavier NX两款在嵌入式领域应用广泛的开发板上运行,验证本系统在嵌入式环境下的应用效果。Jetson Nano开发板,GPU为128-core Maxwell,显 存 为4GB 64位LPDDR4,CPU为ARM○RCortex○RA57@1.43GHz。Jetson Xavier NX开发板,GPU为384-core Volta@110MHz+48 Tensor Core,显存为8G 128位LPDDR4,CPU为ARMv8.2(6-core)@1.4GHz。2个开发板系统为Ubantu 18.04 LTS,运行环境为Python3.6.15、Pytorch1.10.0、Cuda10。
2.2 模型训练
模型共训练500次,初始学习率0.01,动量0.937,当模型损失在100个epoch中没有改进时停止训练,输入图像尺寸为640,批量大小设置为16,权重衰减系数0.000 5。使用YOLO v5n、YOLO v5s、YOLO v5m 3种模型与4种IoU组合后的12种组合结果进行训练,其边框损失、分类损失和目标损失曲线如图7、图8、图9所示。由图7可以看出,边框损失和分类损失在第50次迭代之后基本趋于平缓,目标损失则在第100次迭代之后区域平缓。

图7 边框损失曲线

图8 分类损失曲线

图9 目标损失曲线
由表2可以看出,对于YOLO v5n、YOLO v5s、YOLO v5m 3个模型均是使用SIoU可以获得更好的效果,精确度、召回率、mAP@0.5和mAP@0.5∶0.95均表现最优,而YOLO v5s比YOLO v5n的精度高了3%,模型大了10 MB,YOLO v5m比YOLO v5s的精度高了5.9%,但模型尺寸是YOLO v5s的3倍。
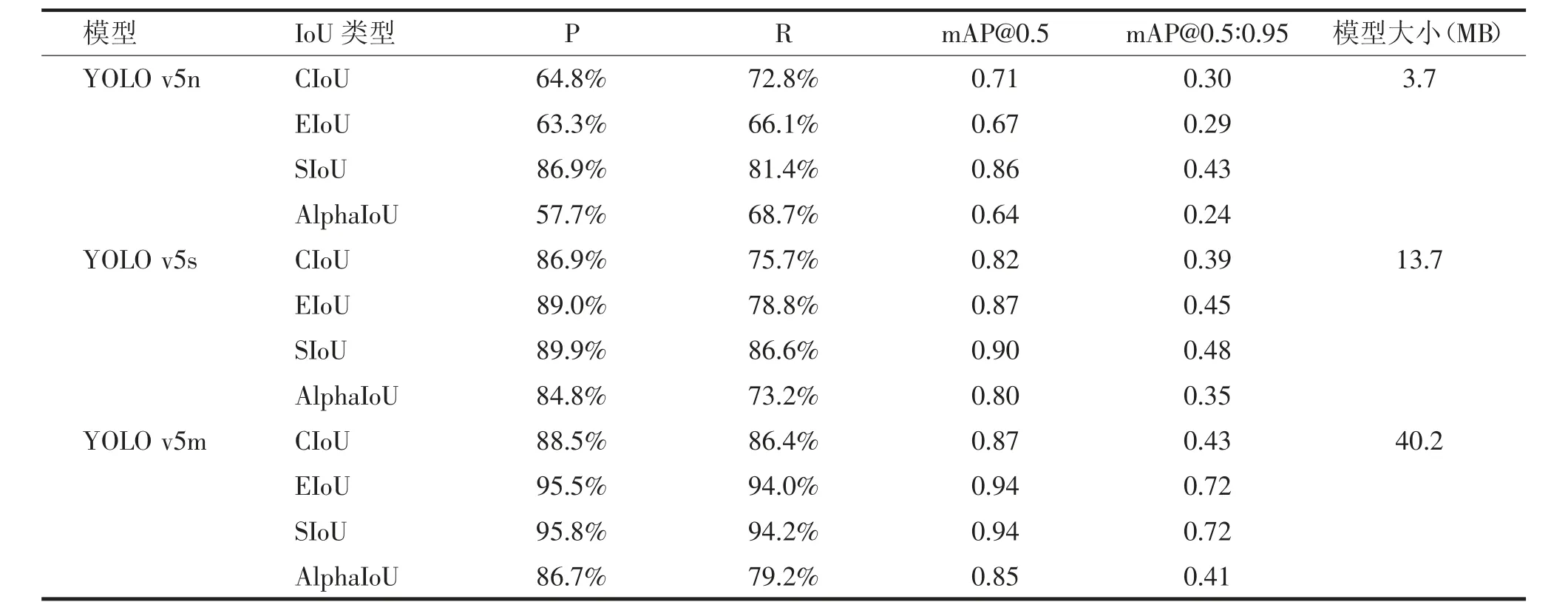
表2 模型测试结果
对比3个模型的精度、召回率、mAP@0.5和mAP@0.5∶0.95的曲线如图10所示,相应指标已趋于稳定,进一步证明使用SIoU的YOLO v5模型在草莓多阶段的目标检测任务中更有效。

图10 精度(A)、召回率(B)、mAP@0.5(C)和mAP@0.5∶0.95(D)
实际检测效果图如图11所示。对比可以看出,YOLO v5n有3处误检(图9(b)中A-C);
YOLO v5s有1处漏检和1处误检(图9(c)中D和E),YOLO v5m检测效果较好。

图11 检测效果
展开分析3个模型各个类别的检测结果如表3所示。由表3可以看出,花期和成熟期的识别准确率更高一些,这与这2个阶段形状或颜色特征比较明显有关,而幼果期、青果期、膨大期、转色期的草莓由于其形态近似度高,所以检测准确率相对低一些。

表3 分阶段识别效果
2.3 运行效率对比分析
将模型在嵌入式环境下应用,测试对比运行效率,结果如表4所示。由表4可以看出,Jetson Nano开发板上如果使用YOLO v5m模型单张图片平均处理时长达到了397.5 ms,如果开发板还要再叠加其他处理任务的情况下,难以满足实时性要求,而YOLO v5s和YOLO v5n平均处理时长分别为196.7、168 ms,相差30 ms左右,差别并不大,但在2.2节试验中YOLO v5s精度比YOLO v5n高了3%。如果使用Jetson Nano开发板作为机器人控制主板的情况下,建议选择YOLO v5s+SIoU模型。而Jetson Xavier NX开发板上YOLO v5m单张图片平均处理时长为120.3 ms,比YOLO v5s和YOLO v5n长了不到1倍,精度高了将近6%,而Jetson Xavier NX开发板本身配置更高,尚有处理余量。如果使用Jetson Xavier NX开发板则建议使用YOLO v5m+SIoU模型。
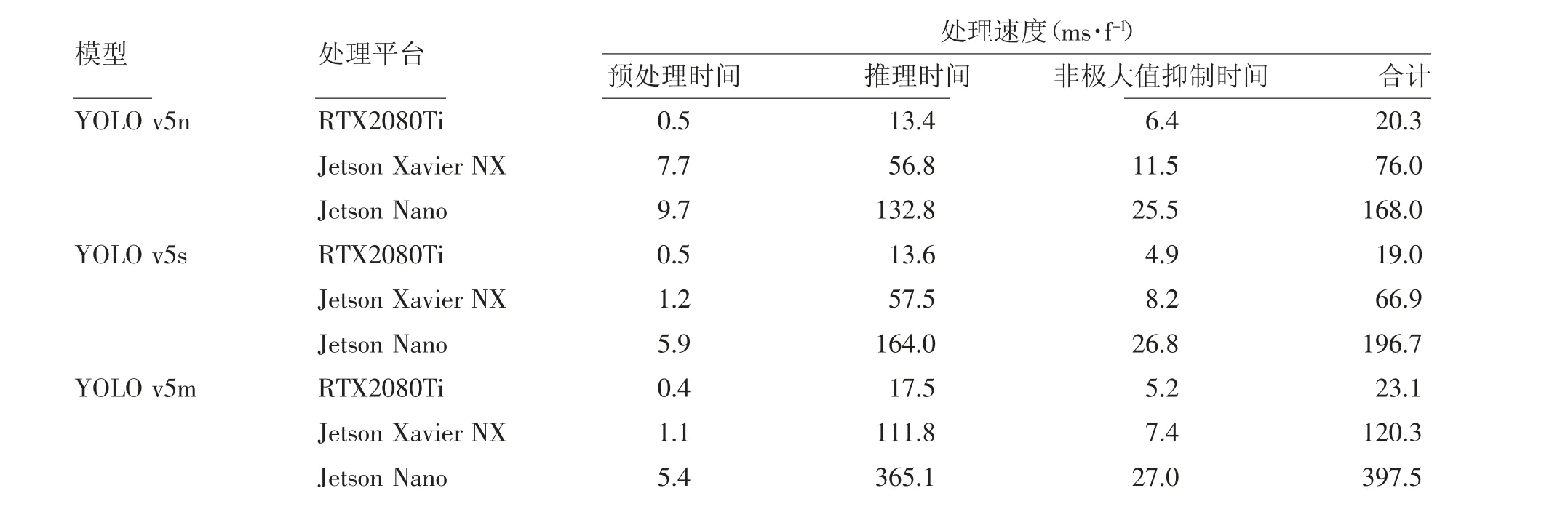
表4 模型推理效率对比
本研究主要关注成熟期草莓的位置和各阶段草莓的个数,面向为采摘机器人提供识别模型、产量预估和测算下一次采摘的时间等需求,是未来规模化智能化生产所必需的研究基础。本研究首先构建了草莓多阶段数据集,使用了YOLO v5n、YOLO v5s和YOLO v5m 3种不同复杂度的网络模型,结合CIoU、EIoU、SIoU和AlphaIoU 4种损失函数,共计12个模型进行对比试验,最终确认使用SIOU的算法在草莓生长期多阶段检测中更有效。在Jetson Xavier NX和Jetson Nano两款嵌入式开发板上进行的推理效率测试,证明算法可以满足实时性需求,明确了在Jetson Xavier NX上更适合使用YOLO v5m+SIoU组合的算法,在Jetson Nano上更适合使用YOLO v5s+SIoU的组合算法,为草莓智能化生产提供技术支持。
猜你喜欢 开发板嵌入式草莓 基于IMX6ULL的嵌入式根文件系统构建汽车实用技术(2022年13期)2022-07-19Focal&Naim同框发布1000系列嵌入式扬声器及全新Uniti Atmos流媒体一体机家庭影院技术(2021年7期)2021-08-14基于STM32H7的FDCAN通信系统设计与实现∗舰船电子工程(2020年5期)2020-07-09基于ARM嵌入式的关于图像处理的交通信号灯识别电子制作(2019年15期)2019-08-27TS系列红外传感器在嵌入式控制系统中的应用电子制作(2019年7期)2019-04-25草莓阅读与作文(小学高年级版)(2017年10期)2017-10-11开发板在单片机原理及接口技术课程教学中的应用职业·中旬(2017年8期)2017-09-13ARM宣布mbed Enabled Freescale FRDM—K64F开发板通过微软认证物联网技术(2015年11期)2015-11-26MiniGUI在基于OMAP5912开发板上的移植现代电子技术(2009年8期)2009-06-25