张伟娟,韩 斌
(江苏科技大学计算机学院,江苏镇江 212003)
大数据的爆发式增长导致知识图谱的数据规模不断增加,由此对知识图谱进行查询时载入内存的存储空间也消耗过大。针对以上问题,目前广泛采取的解决措施有:分布式或者并行处理、使用便宜且空间大的硬盘以及使用压缩技术减少空间。分布式并行处理时存在通信开销大、存取结构复杂以及数据安全难以保障的问题,而空间大的硬盘价格又相对较高。为了实现高效查询,本文在图数据存储形式上采取图压缩技术[1]以减小知识图谱规模。
对知识图谱的压缩是为了更好地进行查询,获取用户所需要的信息。可达性查询[2]是图查询方向的一个重要内容。随着知识图谱的不断发展,如何在知识图谱上进行可达性查询具有非常重要的现实意义。本文在图压缩的基础上对知识图谱[3]进行可达性查询,通过查询结果判断压缩后的图数据是否会影响查询效率。
很多研究针对不同的图数据结构进行压缩。当数据结构为邻接表时,Alexandre 等[4]通过聚类和适当的顶点重排以放大邻接表的复制特性,实现更好的压缩比。这种方法适用于图分析任务的核心,如计算PageRank 值,可以很好地节省一部分存储空间。数据结构为矩阵时,Yu 等[5]在GOFMM 算法基础上通过消息传递接口将其拓展到分布式内存设置上,并且提出一种异步式算法,因此可以从分布式方向上实现分层压缩思想。针对图数据的分布式压缩方向,Payam 等[6]通过Slepian-Wolf 定理导出分布式无损压缩的速率区域,而分布式压缩数据使用还需要考虑耦合性等方面的影响。
传统的图压缩技术已经非常成熟,但是针对知识图谱而言的图压缩技术还有待研究。一般图数据分为有向图、无向图,而知识图谱是带有语义信息的有向图形式的知识库。现有的图数据压缩方法不会考虑到知识图谱中的语义关系,因而要针对知识图谱设计符合其特性的图压缩方法。Katsuhiko 等[7]基于知识图向量嵌入模型方面提出一种二值化的B-CP 分解算法,这种算法通过二进制值替换实值参数以减小模型规模,虽然减少了知识图的嵌入模型规模,但不适用于图数据结构方向的压缩。李高超等[8]提出的GComIdx 算法就是利用有序的键值存储节点和边,为查询提出二级索引和节点索引,并采用传统压缩算法降低磁盘空间,这种压缩方式只是单纯利用压缩完的数据块载入时间和解压缩时间小于整体直接载入的时间。这种方式不仅要将图数据转化为数据集,还要划分归类,并不适用于知识图谱的存储模式,反而适用于关系数据库。而适用于知识图谱存储模式的结构概要模型的图压缩技术ASSG 算法[9]就是根据节点的标签及其rank 值划分节点,这种方法比较粗糙,因为rank 值只是用来衡量节点和出度等于0 的节点的最大距离值。再如OBSQ 压缩方法[10]也是计算节点语义相似度,将计算好的阈值节点划分到一起,然后在原本图结构的基础上构建边,不断调整得到最终压缩图。这两种方法只是单纯考虑了节点和框架,并没有考虑到边标签的语义信息,因此这两种方法并不适合语义丰富的知识图谱。Wahyudi 等[11]提出一种图属性模型的压缩方式-GPC 算法,这种压缩方法虽然适合语义丰富的知识图谱,但为了进一步消除节点以及对节点无关的边,使得图的规模进一步缩小,不能完整地保存图谱的结构信息。
针对图数据结构的查询有多种方式,如可达性查询和子图匹配查询,不同查询方法采用针对不同查询的图压缩设计。本文提出的压缩算法将节点合并、边压缩,在查询过程中若采用子图匹配查询,则已经压缩的图数据还需要将其还原并进行子图匹配,会极大延长查询时间,若采用可达性查询,无须还原压缩后的图数据,只需判断两点之间是否可达,即实体之间是否存在关系,用来检验压缩之后的查询效率十分方便。因此,本文采用可达性查询检验压缩后的查询效率。该方法主要用来判断两个节点之间是否可达。早期的可达性查询研究方法可以分为3 类:Hop 类标签[12]、传递闭包和在线索引类。针对Hop 类查询算法而言,不需对原图进行遍历并且不需要传递闭包,从时间和空间复杂度上取得了较好的均衡。其典型算法除传统的2 跳标签[13]、3 跳标签[14],在2 跳标签的基础上又提出了PLL 算法[15]、PPL 算法[16]以及分布式算法[17]。本文采用效果较优的PLL 算法检验压缩后图的查询效率。
本文涉及的一些基本概念如下:
定义1资源描述框架(Resource Description Framework,RDF)[18]是一种用于表述万维网资源的标记语言。通过RDF 以节点—边—节点的形式展现对资源的描述,其中第一个节点可看作主语(Subject,S)、边看作谓语(Predicate,P),第二个节点可看成宾语(Object,O),SPO 就是一条三元组记录。用“小李子的英文名是Leonardo DiCaprio”表示的三元组如图1 所示,其中“www.kg.com/person/8”是国际资源标识符(Internationalized Resource Identifier,IRI),用来唯一标识“小李子”这个实体,“Kg:EnglishName”用来表示实体和实体之间的关系。

Fig.1 Example of triples图1 三元组示例
定义2资源描述框架模式(Resource Description Framework Schema,RDFs)[19]是在RDF 的基础上,提供了一个以“http://www.w3.org/2000/01/rdf-schema#”为命名空间的词汇表,作为用户描述特定领域中类和属性的标准。其本质是在RDF 的基础之上描述RDF 数据,使之具象化。比如人和动物、工具这3 个类之间的关系,3 个类分别可以有具体的多个属性,3 个类之间的关系也可以建立多个属性值。因此,知识图谱的数据可以用RDF 数据进行存储,也可以以有向图的形式进行存储。
如表1 所示,这组三元组表述了spinach3 为一种蔬菜,spinach1 是一种绿叶蔬菜,蔬菜类是绿叶蔬菜类的父类,farmer 管理蔬菜,farmer1 管理着spinach2 等。以RDF 图的形式呈现如图2 所示,其中“rdf:type”“rdfs:range”“rdf:sub-ClassOf”均是RDFs 用来描述数据,依次代表资源与类之间的实例关系、值域、类与类之间的继承关系。

Table 1 RDF graph example表1 RDF图实例

Fig.2 RDFs in directed graph form图2 有向图形式的RDFs
定义3 原图数据结构可用G=(V,E,T,L)表示,其中G为有向图,V为所有顶点的集合,记V={vi|vi∈V,0 ≤i≤|V|},E为所有边的集合,记为E={ei|ei=(s,t) ∈E,s,t∈V},T为所有属性值的集合函数,L为边标签集合函数。
定义4 等价关系标签是在对原图进行压缩时提出,即不同边的属性值相同,记为T(E1)=T(E2)。
定义5 简图是原图基础上压缩过后的图,用G1(V1,E1,T1,L1)表示,其中V1 为简图中顶点的集合,E为简图中边的集合,T为简图中属性值的集合函数,L为简图中边标签集合函数。
查询过程中所用符号说明如表2所示。

Table 2 Description of symbols used表2 所用符号说明
针对ASSG 算法存在的压缩粗糙问题,本文在此基础上进行改进优化,提出一种适用于知识图谱的等价关系的压缩算法CER(Compression based on Equivalence Relation)。在划分节点时不再采用具有相同标签和rank 值的等价节点进行划分,而是采用具有语义关系的等价关系标签划分节点。等价关系标签可能导致的结果有两种:一种是实体的属性值一致,另一种是实体属性值不一致。当多条相同关系(等价边)的两个实体(节点)具有相同的属性值(节点等价),则这多条边可压缩为同一条边;
当多条相同关系(等价边)的多个实体(节点)具有不相同的属性值(节点不等价),则将这多个实体(节点)划分为一类并排序。这种保存不会像ASSG 算法模糊边及边标签信息。通过这种压缩划分,n个节点会划分为一个新的节点,而边则不会再冗余,从而构建出一个全新简洁的知识图谱,方便载入内存及查询。
以上文的RDF 实例图为例,基于等价关系的压缩算法主要分为两个步骤:①遍历知识图谱上所有边标签信息,若边标签相同且一端存在度为1 的节点,则将具有相同属性值的边划分为一类,得到知识图谱中的关系集合S={S1,S2,S3,...Sn},其中Si为具体相同属性值的边标签集合;
②判断Si 一端的节点属性值是否相同。若其中一对节点属性值不相同但另一对节点属性值相同且度为1,则将已经划分在边集合的边分裂开来,将具有相同属性值的节点划分为一类并在内部进行编码排序;
若两对节点的属性值均相同且其中一对度为1,则将边标签进行压缩,并将具有相同属性值的节点划分为一类,即得到知识图谱中相同属性值的节点集合。若不满足上述两个条件,比如两对节点的属性值均不相同,或者一对节点属性值不相同但另一对节点属性值相同且度不为1等一系列情况,则将边分裂开来。
该算法从知识图谱的边标签上进行划分,并不会影响知识图谱的结构。等价关系的知识图谱压缩方法具体示例如图3所示。

Fig.3 Compressed graph based on equivalence relation图3 基于等价关系的压缩图
在图3 中,按照CER 压缩算法顺序,首先找到具有相同属性值且一端存在度为1 的节点的边标签为“rdf:type”、“far:host”;
然后判断边集合内两端节点的属性值,以边标签“rdf:type”为例,经判断其一端属性值相同,为根圆锥状、鲜绿色等属性,而另一端蔬菜和绿叶蔬菜的具体属性值并不相同,因此将其边标签“rdf:type”从边集合中分裂出来,将“en:spinach1”、”en:spinach3”度为1 且相同属性值合并到同一个节点集;
而以边标签“far:host”为例,度数为1 的节点为“en:farmer1”和“en:farmer2”,经判断其属性值相同,均为劳作、勤劳等属性;
另一端的节点属性值相同,则对边标签“far:host”进行压缩,并将节点“en:farmer1”和“en:farmer2”放在一个顶点集合中。经过以上压缩,得到最终压缩图。CER 压缩算法思路如算法1所示。
算法1等价关系的压缩算法(CER)


本文算法中,第1 行对压缩图进行初始化,第2 行遍历边标签;
第3 行到第4 行是找到相同的边标签,并将其存放入S集合。第5 行到第8 行是判断边标签两端节点的属性值,若只有一对节点属性值相同且度数均为1,则对压缩进S集合的边(s,t)进行分裂,同时将属性值相同的节点存放进节点集合Pi。第9 行同理可得,当节点u和节点s的属性值相同且度数值均为1 而节点v和节点t的属性值不同时,分裂(s,t),Pi集合存放v、t。第10 行到第13 行是针对两对节点的属性值均相同且其中一对度为1 的情况,压缩边标签,划分顶点集。第14 行描述了第3 种情况,即不满足上述条件的剩余情况下,将存放进S集合的边标签分裂出来。等价关系的压缩算法主要是对边标签进行操作,划分节点集合,时间复杂度为O(|E|log|V|)。此压缩算法压缩力度不大,但是可完整保存图的结构信息,并保全知识图谱的语义信息。
本文通过PLL 算法检验CER 压缩算法之后是否可提高查询效率。PLL 算法是在2-hop 的基础上改进而来,通过剪枝减少遍历节点数目。传统的2-hop label 只是通过出、入节点的标签判断是否可达,而PLL 算法是在判断出、入标签时若已经满足可达条件,则无需进行BFS 遍历后续节点。计算步骤为:首先计算各节点的(|outG(u)|+1) ×(|inG(u)|+1),按照结果进行降序排列,然后进行广度优先遍历,在入标签Lin中加入遍历得到的节点;
同理反向广度优先遍历得到出标签Lout的值。若在构建标签的过程中发现出标签和入标签中已经存在相同的节点值,即可达,则中断遍历,对下一个节点进行遍历。遍历结束,得到出入标签之后,查询是否可达只需要判断Lout和Lin中是否存在交集。经过预处理将知识图谱转化为简化有向图,其中节点1和2的属性值、5和6的属性值相同,如图4所示。
在图4 中,右图为压缩后的有向图,其中A={a1,a2,a3,...,ai}代表边标签相同且节点类型不相同的顶点集合,B={b1,b2,b3,...,bi}代表边标签相同且节点类型相同的顶点集合。对于右图使用PLL 算法构建索引如表3所示,按照计算结果排序为3、4、a1、b1、6。以节点3 为例,对节点3 进行正向广度优先搜索,得到节点b1、4,则在b1、4 的入标签中加入节点3;
反向广度优先搜索得到节点a1,则在a1 的出标签中加入节点3。在反向遍历节点4 这一步时,得到节点3、a1;
由于节点a1 到节点4 已经通过节点3可达,则无需将节点4放入节点a1的入标签中。
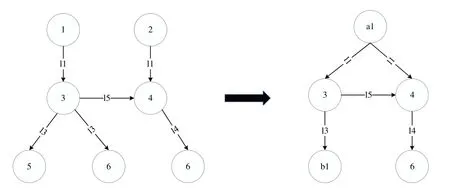
Fig.4 Simplified directed graph图4 简化的有向图
可达性查询,比如Query(a1 →6)=1,这是因为存在相同节点3。

Table 3 PLL labels of vertices in compressed graph表3 压缩图中顶点的PLL标签
3.1 实验环境
本文实验所用的机器CPU 配置为Inte(lR)Core(TM)i5-8250U CPU @ 1.60GHz 1.80GHz,内存为8.00G,硬盘为500GB,操作系统为Ubuntu16.04 LTS,算法使用C++语言编写完成。
3.2 实验数据
本文所采用的3 个知识图谱来自各领域的公开泛用数据集,用来评估所提出算法的压缩率、压缩时间和查询时间。其包括Yago 的部分数据集、CN-DBpedia 数据集和XLore 数据集。其中,Yago 的部分数据集包含Wikipedia、WordNet 和GeoNames 3 个来源;
CN-pedia 是来源中文百科网站的结构化数据集,其层级为8,有110 万+个属性值;
XLore 是来源于清华大学的多语言知识图谱,包含44 万+个属性和丰富的语义关系。这些数据需要预处理对实体进行编码,整理为有向图的形式,数据集中的顶点集和边集的信息如表4 所示,其中|V|代表节点的数量,|E|代表边的数量。
3.3 压缩效率比较
本文主要比较ASSG 压缩算法、OBSQ 压缩算法、GPC压缩算法和CER 压缩算法在3 个数据集上的压缩率、压缩时间等性能度量,具体如表5所示。

Table 4 Data sets information表4 数据集信息
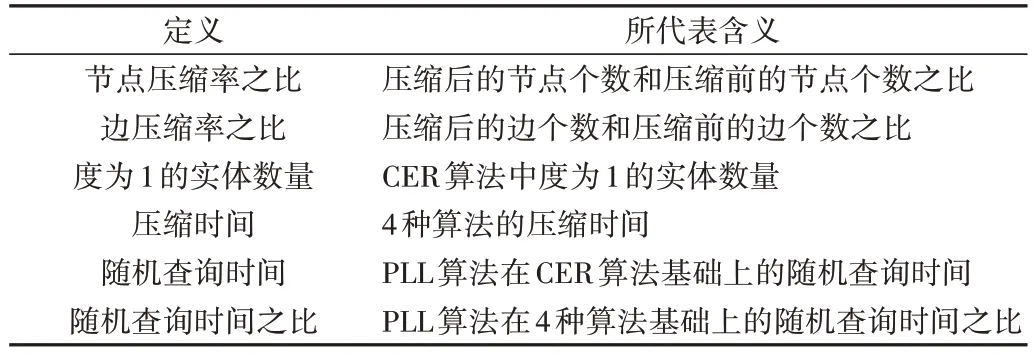
Table 5 Description of the performance metrics used表5 所用性能度量说明
通过节点和边两个方面比较整体压缩效率,压缩率越低压缩效果越好。节点压缩效率为压缩后节点个数和压缩前节点个数之比;
边的压缩效率为压缩后边的个数和压缩前边的个数之比。
如图5 所示,CER 算法在节点压缩效率上优于OBSQ算法和ASSG 算法,稍逊色于GPC 算法,CER 压缩算法在压缩完成后的节点压缩率均值为39%。这4种算法都是节点压缩的算法,但是OBSQ 算法和ASSG 算法仅通过图的结构特征进行划分压缩,GPC 算法通过消除节点的方式极大降低了节点压缩率,却使图结构变得粗糙。而CER 考虑了边标签信息以及节点之间的属性值,同时保留了图结构。针对同一个类型的实体可以全部吸收兼并,极大减少了重复的边标签,比如针对属性值均为植物类节点所在的同一边标签均可进行压缩,实现压缩效率最大化。

Fig.5 Node compression ratio图5 节点压缩率之比
从图6 可以看出,CER 算法的边压缩率比OBSQ 算法和ASSG 算法及GPC 算法低,节点压缩率的均值为45%。可以看出,边的压缩效率不如节点的压缩效率,这是因为OBSQ 算法和ASSG 算法都是考虑节点和前驱后继节点之间的关系以压缩边,而不考虑边标签信息。GPC 算法是消除节点和边以达到压缩目的,类似剪枝,边压缩率相对前两者有所提高,但是并没有考虑压缩过后的图结构;
而CER 算法更大程度地考虑了图结构,并非只要边标签相同就进行压缩,提高了压缩精度。综上,从节点压缩率和边压缩率而言,CER 压缩效率优于其他3种算法。
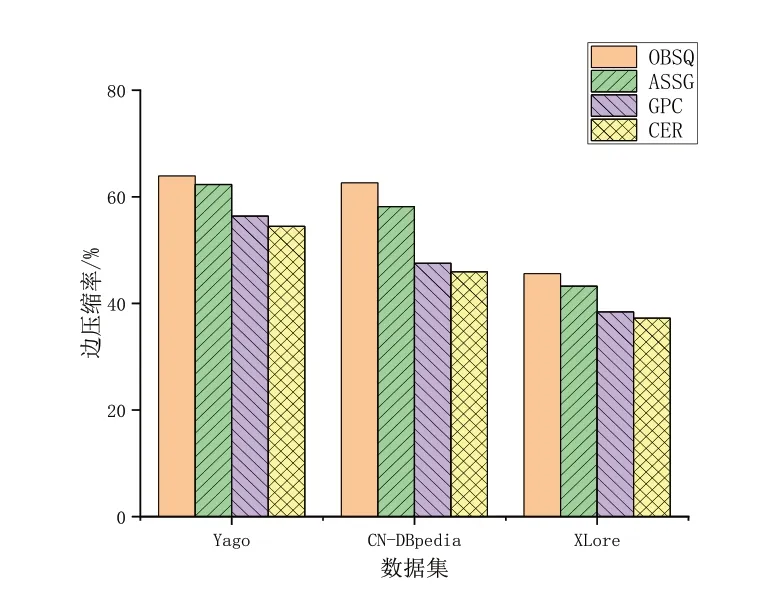
Fig.6 Edge compression ratio图6 边压缩率之比
表6 展示了在3 种数据集上度为1 的实体数量。度为1 的节点不一定都会被压缩,因此节点压缩率之比大于等于度不为1 的顶点数占比。表6 验证了图5 的节点压缩率之比的合理性。

Table 6 Number of entities with degree 1表6 度为1的实体数量
从表7 的压缩时间看,本文CER 算法的压缩时间小于OBSQ 算法和ASSG 算法,略接近于GPC 算法。OBSQ 算法由于在遍历图谱时需计算各节点间的语义相似度,还要划分到给定阈值,因而计算所需的时间远大于压缩时间;
ASSG 算法由于需要计算rank 值,计算也耗时过长。GPC算法和CER 算法需遍历整个图并直接进行压缩,压缩不深入,相比其他两种算法,这两种算法压缩时间较少。GPC算法从节点和边同时入手,而CER 算法从先找出相同属性值的边标签集合入手,所需时间与GPC 算法基本持平。
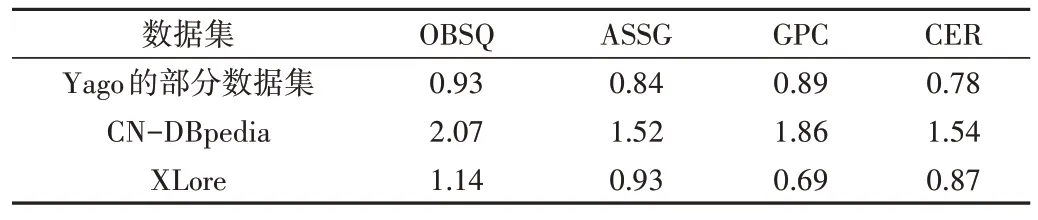
Table 7 Compression time(1 000×s)表7 压缩时间(1 000×s)
表8 描述了PLL 算法在原图和压缩图上针对100 000节点对的随机查询时间。在压缩图上的随机查询时间均小于在原图上的查询时间。这是因为CER 算法在原图基础上进行压缩之后边标签的压缩极大减小了原图规模,节点合并缩短了构建出入标签的时间,即构建索引的时间减少,从而使得查询时间也随之减少,在一定程度上提高了查询效率,降低了查询难度。

Table 8 Random query time(ms)表8 随机查询时间(ms)
图7 展示了基于4 种压缩算法的随机查询时间之比。其中,CER 算法的随机查询时间相对较快,这是因为GPC算法和CER 算法的节点压缩率和边压缩率高于其他两种压缩算法,而GPC 压缩算法是将消除的点和边均保留在实体节点中,从而在构建PLL 出入标签时由于索引空间过大而导致查询时间也相应增加。

Fig.7 Random query time ratio图7 随机查询时间之比
本文提出了面向知识图谱的等价关系压缩算法CER,通过该压缩算法上的PLL 查询算法检验压缩后的查询效果。实验结果表明,相对于其他压缩算法,该算法在边压缩效率和查询时间上有较大提升,且适用于大规模的知识图谱。这种方法保证了原图谱的结构和语义信息,也从一定程度上减少了原始图谱的空间规模。该方法考虑的是边标签方向的压缩,节点压缩方向也是后续可以研究的问题。该方法只针对度为1 的节点的压缩,在未来工作中可尝试在此基础上进行再次压缩;
或者不仅仅局限于度为1的节点,而是对其他节点压缩方法也进行更为深入的研究。