赵小芬,张开生
(陕西科技大学电气与控制工程学院,陕西 西安 710021)
语音识别技术作为当今人工智能时代的热点然而也是难点问题,广受国内外专家学者关注[1-2]。随着科技的不断进步,动态编程技术飞速发展、设备性能快速提高。传统的语音声学系统,如高斯混合模型[3](Gaussian Mixture Model,GMM)以及隐马尔科夫模型[4](Hidden Markov Models,HMM)正在被深度学习模型所替代[5]。学者们[6-8]对深度神经网络(Deep Neural Networks,DNN)在语音识别声学建模进行了研究,并取得一定的效果。在2015年ILSRVC挑战赛中DNN被证明在分类任务中表现卓越,但是这种优越性是以高计算复杂度为代价[9],因此,如何降低训练参数规模、减少内存消耗、提升训练效率,从而提高语音识别率就尤为重要。
据相关专家考证[10-13],卷积神经网络(Convolutional Neural Networks,CNN)在声学方面优于DNN。ZHANG Q等[14]提出的基于卷积神经网络的连续语音识别,针对连续语音识别的问题,根据卷积神经网络在图像处理任务中具有平移不变性的特点;
另外,通过在标准语料库TIMIT上验证,其研究结果表明,与DNN相比,CNN对于神经网络模型尺寸的减小具有显著的作用,与此同时也可以获得更佳的识别精度。黄玉蕾[15]等提出的MFSC系数特征局部有限权重共享CNN语音识别,输入形式采用语音信号的二维阵列映射,并引入卷积神经网络,根据语音信号的局部特征构建出有限局部权重共享卷积神经网络学习算法,从而达到识别的目的。YOSHIOKA T等[16]充分利用CNN中的卷积能力,将CNN用于远场语音识别,对语音特征向量的短时相关性进行建模,并与全连通DNN进行比较,结果证明CNN的性能优于全连通DNN。
如何优化CNN在语音识别中的性能,进一步提升语音识别率,依然是CNN应用于语音识别时所面临的挑战,因此仍需进一步地研究[17]。本文结合语音识别技术对CNN的结构展开研究,提出一种三层结构优化的卷积神经网络,并将其应用于语音识别,旨在为解决传统卷积神经网络存在梯度消失、识别精度不高的缺陷,以及进一步提升语音识别率提供有效的方法。
CNN一般包含输入层、卷积层、池化层(采样层)、全连接层和输出层。结构呈现堆叠状,前一层的输出作为后一层的输入,一般与最后一层连接的为分类器,输出得到最终结果。CNN具有共享权值及局部连接的特点,与其它神经网络相比其参数更少,并且因其具有良好的平移不变性,可以更好地克服非平稳信号的时变性,因此被广泛地应用于图像处理、语音识别领域等。图1所示为典型的CNN体系结构图。

图1 CNN体系结构图
1.1 改进卷积层
CNN中每个卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。卷积运算的目的是采用局部连接和权值共享的方式提取输入的不同特征。
卷积层中一般有5种激活函数,其中Sigmoid函数的倒数为非零值,运算起来比较容易,故被广泛使用,但是Sigmoid函数存在梯度消失的问题。神经网络中常用的激活函数还有ReLU函数,其特点是当输入值大于0时,倒数不为0,从而允许基于梯度的学习,但是当输入为负值的时候,其学习速率下降,有可能造成神经元无效的情况。ReLU激活函数中还包括ELU函数,ELU函数的特点是当输入值小于0时,增添一个非0输出,这样做的目的是防止出现静默神经元,使倒数可以收敛到零,进而使学习率得到提高。SoftPlus函数也是神经网络的激活函数,其倒数非零并且连续,故能够防止出现静默神经元,但是由于它具有不对称性,并不以0为中心,会出现干扰网络学习的现象,并且可能出现梯度消失的问题。Tanh函数解决了Sigmoid关于零均值化的输出问题,其导数范围变大,在(0,1)之间,而Sigmoid在(0,0.25)之间,梯度消失问题有所缓解,但是由于其幂运算的计算方式致使计算成本代价大,并且依然存在梯度消失的问题。
为了改善上述激活函数存在的缺陷,本文引入文献18中新型log函数作为卷积层的激活函数,log激活函数依据生物神经元特性,若输入进神经元的特征值为负的时候,log激活函数便会将其输出值进行强制转化为0值。当输入值为正时,其输出值便随输入值的增大而增大,这与生物神经元的特性是相符的,从而能更好地缓解梯度消失的问题。
1.2 改进池化层
池化层也叫采样层,位于连续的卷积层之间,可以用于压缩数据及参数的数量,减小过拟合。其基本操作与卷积层比较类似,但是其矩阵间数据计算的规则是不同的,卷积层通过最大池化或者平均池化操作的方式,并且不必经过反向传播的修改。
通常池化操作的方法有最大池化和平均池化两种方式,最大池化的过程及时选出最大数值作为输出矩阵相应元素值,这种方法可以使具有代表性的特征点尽可能的保留。另一种池化操作方法为平均池化方法,就是将每个小窗口的4个数字计算平均值作为输出矩阵的相应元素值。
一般来说,提取特征时其误差主要来源于估计值方差增大,这种现象往往是由邻域大小受到一定的限制造成的,另一种误差主要来源于在估计均值的时候存在估计偏移。平均池化操作主要是降低前者所造成的误差,最大池化可降低后者产生的误差,但是各自都有不足,都无法准确地提取池化域特征。本文借鉴何鑫等[19]研究的方法,结合二者的优势和互补特性,采用中间池化方法(middle-pooling),从而减小特征提取的误差和增强稳定性。优化后的函数表示为:
Pij=(T+2a2)/2,
(1)
(2)
上式中Fij表示输入语音特征域大小,池化大小为s×s,s表示每次移动的步长,a2为偏差大小,max表示最大池化操作。
1.3 改进全连接层
全连接层将池化处理后的语音特征进行全连接,通常出现在整个网络的最后几层,对上一层输入的特征的求加权和,全连接中每一个神经元都与上一层的神经元进行全连接,但是实际应用中发现全连接层可由卷积实现。对于传统的CNN(即包含全连接层)输入的语音信号大小要求是固定的,这就要求全连接层与上层连接时,参数数量要预先设定好,这会使网络结构更加复杂,且模型的泛化能力降低。卷积层与全连接层具有相同的特点,二者都是由上一层输出与参数矩阵相乘而得到下一层的输入,故将卷积层代替全连接层,不仅可降低模型复杂度,增强其可移植性,而且可以有效地解决全连接层的缺陷。
由于CNN在时间和空间上具有平移不变性的特点,而语音信号本身具有多样性,所以本文利用CNN卷积不变特性来克服说话人多样性。CNN用于识别时网络的输入方式类似于图像识别,其输入形式如图2所示。首先将声学特征转换为二维矩阵,其中时域表示一个维度,频域表示一个维度。假设一段输入语音信号被分为n帧,这n帧语音信号的包含3种形式,分别是静态形式、一阶差分与二阶差分。

图2 语音信号二维映射形式
将经过三层优化之后的CNN用于语音识别,其网络模型如图3所示,包含输入层、卷积层1、卷积层2、卷积层3、全连接层以及输出层。本文CNN结构的全连接层使用卷积层来代替。

图3 优化后的CNN结构示意图
(1)输入层。输入层为二维语音特征矩阵。
(2)卷积层1。第2层为卷积层。该层卷积层采用5×5大小的卷积核作为采样窗口,使用改进的对数函数作为激活函数,能够更好地模拟生物神经元特性,缓解梯度消失的情况。
(3)卷积层2。第3层仍为卷积层,采用5×5的卷积核,对第二层特征图进行二次卷积,并提取相应的特征,同样采用新型对数函数作为激活函数。
(4)卷积层3。第4层采用4×4大小的卷积核,并增大其步长,进一步提取语音特征。
(5)全连接层。采用卷积层代替传统的全连接层,降低网络结构的复杂度,增强特征信息。
输出层。通过Softmax实现特征分类,得到最终的结果输出。本文CNN结构参数设置见表1。

表1 CNN结构参数设置
3.1 实验数据集及评价指标
为保证实验可靠性,本文选取TIMIT英文语音数据集[20]及ST-CMDS中文语音数据集两种语音数据集[21]作为实验数据来源,其中,TIMIT数据库包含630个不同说话人信息,为评价说话人识别系统中最权威的语音数据库。本文选取430个说话人语音作为训练集,选取60个说话人语音作为测试集,并且训练集与测试集间无重叠。中文语音数据集选用ST-CMDS数据集,该中文语音数据集是由一家AI数据公司北京冲浪科技发布的中文语音数据集,其中包含10万条语音文件,100 h以上的语音数据,数据内容以平时的网上语音聊天和智能语音控制语句为主,855个不同说话者,同时有男声和女声,适合多种场景下使用。再选取其中450个不同说话者的900条语音作为训练集,120条语音作为数据集,且训练集与测试集间无交叠。
本文采用3-gram模型作为实验的语言统计模型。语音的特征参数选用文献22中所述的FBANK声学特征[22],该语音特征帧间关联性较强,改善传统MFCC特征提取时能量值发生偏置造成的提取不准确从而对识别结果产生的影响。实验分别采用词错率(Word Error Rate,WER)以及模型损失值作为算法的评价指标,其中WER的表达式为
(3)
上式中,S为语音解码时,连续语音与人工标注统计出的替换词的个数,D为删除词的个数,I为插入词的个数,N为语音库中正确词的总数量。
上述模型的损失值可以有效反映模型与实际数据之间的差距,通过模型损失值可以更直观地进行不同模型之间的比较。
3.2 对比实验结果及分析
为了更好地反映本文算法的有效性,本文选择目前常用的隐马尔科夫模型(HMM)、深度神经网络(DNN)和传统卷积神经网络(CNN)用于语音识别作为对照组,与本文优化后的CNN网络结构进行性能比较,当然目前也存在其它的网络应用于语音识别,相对来说并不十分成熟,缺乏一套完善或者公认的量化指标去进行评价,因此这里并未选其作为对照组。具体方式根据上述2种评价指标,其中采用HMM进行语音识别时,其本质为最大概率的计算。根据训练集数据计算出模型的参数后,依据Viterbi算法,取概率最大的为识别结果。
DNN实现语音识别时,先构造一定数量隐含层的深度神经网络,一般采用Sigmoid函数或者Tanh函数作为激活函数;
再利用反向传播算法对网络进行训练,建立目标函数。实验对不同声学模型的词错误率进行多次统计,随机取其中10组结果,其中在TIMIT语音数据集下结果见表2,在STCMDS中文数据集下的结果见表3。

表2 TIMIT数据集下不同模型词错误率 单位:%
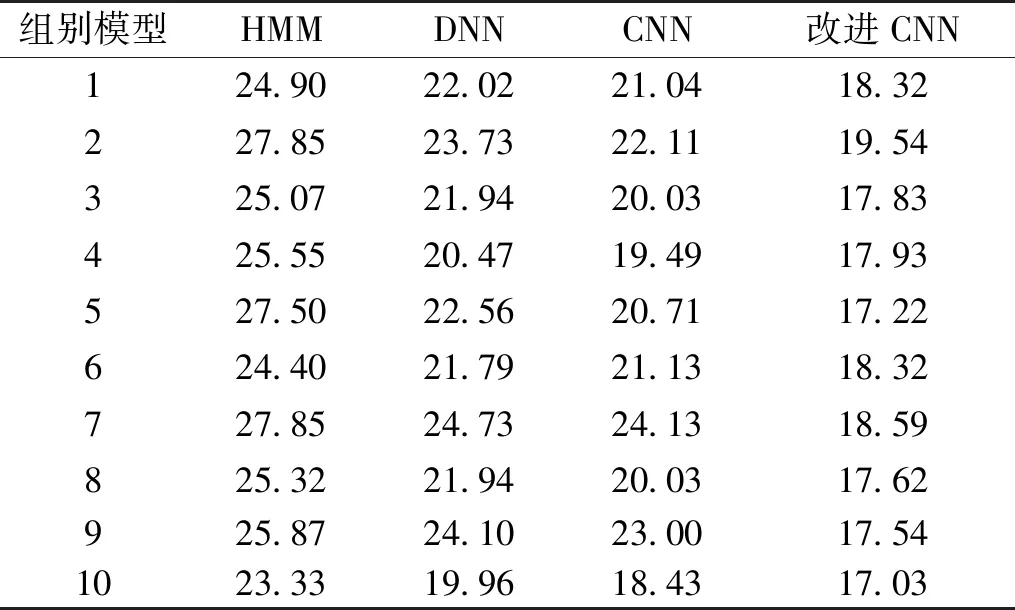
表3 ST-CMDS数据集下不同模型词错误率 单位:%
由表2、表3可以看出,两种数据集下WER值的变化趋势基本一致。3种神经网络模型相对于传统HMM模型,错误率显著降低。总体来说,本文改进CNN相对于对比模型,错误率均降低。在TIMIT数据集下,相对于HMM模型、DNN模型、传统CNN模型其平均错误率分别下降31.52%、16.43%、12.87%。在ST-CMDS数据集下,相对于HMM模型、DNN模型以及传统CNN模型,其平均错误率分别下降30.58%、19.80%、14.76%。可见,本文经过三层结构优化后的CNN语音识别率明显提升。
由表2和表3还可以看出:本文算法无论是在英文语音数据集还是中文语音数据集,其语音识别率均得到有效的提高。
图4为4种模型的损失变化曲线。整体上看,HMM、DNN、传统CNN、改进DNN的损失值呈现下降的状态。随着训练数据量的上升,各个声学模型逐渐趋于收敛,最终损失值趋于一个固定的值。其中HMM趋于35,DNN趋于33、传统CNN趋于30而改进后的CNN最终损失值趋于18,可见损失值明显减小,有助于训练更深层次模型。

图4 不同训练模型损失值的比较
另外,本文还对改进后模型训练及测试时间进行了统计,随机取10组其训练时间见表4。

表4 改进CNN模型训练及测试时间
(1)本文提出了三层结构优化的卷积神经网络的语音识别,通过分析CNN结构的特点,据此分别对卷积层、池化层以及全连接层进行改进。
(2)针对传统CNN卷积层的激活函数容易出现梯度消失的问题,将一种更符合生物神经元特性的新型对数函数作为激活函数;
结合平均池化及最大池化各自的优势改进池化层;
使用卷积层代替全连接层,降低模型的复杂度。
(3)将改进后的算法与HMM、DNN、传统CNN声学建模方式分别在TIMIT英文语音数据集及STCMDS中文语音数据集下进行对比实验。结果显示,在TIMIT数据集下相较于对比方法,词错误率分别降低31.52%、16.43%以及12.87%;
在ST-CMDS数据集下,词错误率分别降低30.58%、19.80%及14.76%;
模型损失度明显减小,在一定程度上提升了模型的泛化能力。