张鹏张瑞
(1.上海大学计算机工程与科学学院,上海200444;2.上海大学材料基因组工程研究院材料信息与数据科学中心,上海200444;3.之江实验室,浙江杭州311100)
新材料的开发和应用几乎伴随着每一项人类历史上重大的科技进步,从铜和锌混合制成青铜,到作为数字技术的核心部件——高质量硅芯片.然而,传统的新材料研发方法[1],如经验试错法,因具有开发周期长、效率低、成本高等一系列缺点,很难满足当今社会发展的需求.目前,采用人工智能、机器学习的数据驱动方法[2],因计算成本低、能有效缩短开发周期,已被应用于材料制备、材料分析和材料设计等诸多领域[3],包括预测钢材的疲劳强度、合金材料的物理和机械性质[4]等.
特征选择通过从原始特征集中选择出最佳的特征子集,来提高机器学习算法的泛化性能.对材料数据进行数据挖掘和机器学习的过程中,需要对含有大量数据的特征集进行预处理.通过对特征数据的降维操作,不仅能够减少冗余特征,避免模型过拟合,还能提高模型的可解释性.同时,特征子集的选择是一个全局搜索的过程,采用遗传算法、粒子群算法等启发式算法来搜索最优子集很有必要.基于此,本工作提出一种基于强化学习的封装式特征选择方法,首先利用强化学习中的智能体探索可能的特征子集空间,然后根据封装式特征选择的评价标准——机器学习算法的性能优劣给强化学习分配不同的奖励,最终将获得最大奖励的决策序列作为最优策略,从而得到最优特征子集.与此同时,本工作在非晶合金的分类问题上进行验证.此外,为了提高模型的预测性能,本工作通过符号变换的特征构造方法,将低维特征映射到高维特征,最后利用强化学习从高维特征中选出最优的特征子集,并在铝基复合材料的力学性能预测上进行验证.
1.1 特征选择相关工作
特征选择的研究最早可以追溯到20世纪60年代,涉及机器学习、模式识别等多个领域.随着特征维度的上升,为了保证学习算法的预测精度,需要训练的样本数量大幅增加.因此,特征选择作为一种最直接的降维手段,得到众多学者的关注和研究.根据特征选择过程中使用的评价标准不同,特征选择方法大致可以分为3种:过滤式方法(filter)、封装式方法(wrapper)和嵌入式方法(embedded)[5].
过滤式方法独立于后续的机器学习算法,基于数据之间的内在特性筛选特征,其中针对内在特征的评价衍生出很多相关研究.Relief、ReliefF算法使用欧氏距离衡量特征和目标量之间的关系[6].该类算法考虑了特征和目标量之间的相关性,但是没有考虑特征之间可能存在冗余.Fisher方法来源于fisher准则——类内距离尽可能小、类间距离尽可能大,能够选出具有明显影响的特征[7].其他度量手段,如互信息、信息增益、加入冗余惩罚的互信息、条件互信息、归一化互信息等[8],都可归结为度量特征间、特征与类别间非线性关系的手段.
封装式方法将特征选择过程与后续的机器学习算法紧密结合,将模型指标作为筛选特征的标准.Guyon等[9]在2002年提出高效的封装式特征选择算法——支持向量机-递归特征消除(support vector machine-recursive feature elimination,SVM-RFE),该算法将SVM的分类准确率作为选择特征的标准,通过前向搜索寻找最优的特征子集,因其高效性目前仍被广泛使用.2014年,姚登举等[10]提出一种基于随机森林的封装式特征选择方法,通过随机森林对特征的重要性排序,用后向搜索的方法依次删去子集中重要性最低的特征,并重新训练模型,最后选择分类准确率最高的特征子集作为特征选择结果.封装式方法结合了具体的机器学习算法,每次评价都需要训练一次模型,因此运行时间较长,但该类算法通常能够选出具有良好解释性的、小规模的特征子集.随着计算能力的提高以及智能优化算法的发展,封装式方法也得到了广泛的应用.
嵌入式方法是将特征选择方法嵌入机器学习算法中,整个模型训练的过程也是特征选择的过程,模型训练结束就可以得到特征子集.决策树是典型的嵌入式特征选择方法,其特征选择的标准有信息增益、信息增益率和基尼系数等[11].另一类是基于L1正则化方法,通过将回归系数中0的特征删掉,最后留下来的特征就是选出的特征子集[12].
1.2 强化学习相关工作
1953年,Bellman提出了动态规划数学理论和方法,其中的贝尔曼方程是强化学习的基础之一.1957年,Bellman等[13]又提出了马尔可夫决策过程,为强化学习的发展作出重要贡献.20世纪60年代,Andreae等[14]开发了通过与环境交互进行试错学习的系统——STeLLA系统.1988年,Sutton等[15]首次使用时间差分(time difference,TD)学习算法.1989年,Watkins[16]首次提出了Q-learning强化学习算法,利用TD算法更新维护Q表,最终可以收敛到最优Q值.2013年,DeepMind团队利用智能体通过深度学习网络直接从高维度的感应器输入中提取有效特征,然后利用Q-learning的思想寻找最优策略,这种与深度学习结合的Q-learning强化学习也被称为深度Q-learning网络(deepQ-learning network,DQN)[17].2014年,Silver等[18]提出确定性策略梯度强化学习算法,相较于DQN,该算法可以选择连续的动作行为.2015年,Van Hasselt等[19]提出双Q-learning的深度强化学习,加速强化学习的收敛.2017年,DeepMind发布AlphaGo Zero,该智能体不需要人类专业棋谱,通过自我对弈,就超过了之前的AlphaGo版本[20].
强化学习是一种学习环境状态到智能体行为映射的机器学习方法.强化学习的主体——智能体,通过接收当前环境特征,对当前环境特征进行判断,做出相应的行为,使得自身在执行一系列行为后所得的累计奖励值最大.强化学习方法不需要类似监督学习那样被告知采取何种行为,而是通过奖励来“告诉”智能体当前所作行为的“好坏”,智能体通过不断尝试选择最优的策略即可.因此,整个学习过程中设计者只需要给出对应的奖惩大小.
2.1 强化学习原理
标准的强化学习框架如图1所示.智能体接收环境的状态编码,将其作为智能体输入,即感知当前环境状态s,然后通过自身决策策略选择动作a,将其作为智能体的输出.智能体执行动作a后,将导致环境发生变化,进入环境状态s′,与此同时,环境会给予智能体对应的奖惩信号r.智能体的目标是每次选择动作后,使得环境给予智能体的奖励尽可能大.为了完成目标,智能体会执行一系列动作,这些动作被统称为行动策略Π,Π={a1,a2,···,an}.当某个行动策略获得的奖惩信号r>0,强化学习过程会加强选择该类行为的趋势;对应地,当某个行动策略获得的奖惩信号r<0,则会减弱选择该类行为的趋势.而奖惩信号r的绝对值大小代表了增强或减弱趋势的幅度.

图1 标准的强化学习框架Fig.1 Standard reinforcement learning framework
强化学习过程中智能体探索环境和训练过程基于马尔可夫决策过程,该过程可由一个五元组表示:M=(S,A,P,R,γ),式中:S表示一组环境状态集合,st表示智能体在t时刻所处的状态,st∈S;A表示一组动作集合,at表示智能体在a时刻执行的动作,at∈A;P表示状态转移概率分布函数,P(st,at)表示在st状态下执行了动作at后,转移到其他环境状态的概率分布;R表示奖励函数,R(st,at)表示在st状态下执行了动作at后获得的奖励;γ表示折扣率或折扣因子,其值为[0,1].
智能体在状态st下执行了行为at,此后每个时刻所获得的收益都需要乘以γ.引入折扣率主要是出于两方面的考虑:其一是由于某些任务具有时限性,引入折扣率可以使得相同的奖励越早获得,总收益就会越大,则整个决策行为朝着越快获得更大奖励的方向执行;其二是由于距离当前环境状态越远,获得收益的不确定性就会越大,通过衰减因子来缩小未来的收益变化能够缩小误差.
强化学习的整个过程就是在寻求最优策略Π*,以使获得的折扣奖励和的期望v(s,Π)最大,这是由于状态转移函数是个概率函数,所以要求期望最大.v(s,Π)的定义为

式中:s0表示初始状态;rt表示t时刻获得的奖励.式(1)又可以被改写成

式(2)体现了执行策略Π所获得奖励总和等于当前状态下执行策略Π中的行为aΠ获得的奖励以及转移到下一个状态s′后执行后续Π策略行为所获得的累积奖励和.智能体通过学习状态转移函数和奖励函数,就可以通过迭代搜索得到最优策略Π*.
基于马尔可夫决策过程,研究者提出了多种不同的强化学习算法.本工作主要研究将强化学习应用于特征选择,根据强化学习的训练探索过程,抽象出基于强化学习的封装式特征选择模型,得到如下抽象关系:①状态集S,特征的不同组合方式组成的子集;②动作集A,添加某个特征或结束;③收益R,将特征子集在模型上的预测准确率作为收益.
以上关系可通过DQN求解最优策略,即通过DQN方法运行特征选择.
2.2 深度Q-learning网络
DQN是在Q-learning强化学习的基础上演进而来的,二者具有相同思想.Q-learning是一种基于价值的强化学习算法[21],其中的Q代表动作-价值函数Q(st,at),表示在某个时刻t的st状态下,采用动作at所得到的最大累计收益.Q值是由智能体选择行为后获得的即刻收益以及执行最优策略后得到的值,因此可表示为

Q-learning的主要思想是利用状态s和动作a构建出一张二维的Q表,表中的每一个值表示在当前状态下选择对应行为预期获得的奖励.基于Q表,当智能体处于对应环境状态时,不断选择预期奖励值最大的行为,直到流程结束,这个过程中选择的行为集合就是所需要的最优策略Π*.显然,Q-learning的训练过程就是训练出一张Q表,从而准确计算每个状态-动作对应的预期奖励.根据式(3),Q(st+1,at+1)和Q(st,at)是Q表中对应的两个值,R(st,at)是环境反馈的值.由于等式两部分初始化后存在误差,可以用式(3)迭代优化Q表,具体为

可以看到,优化只需要当前状态和下一状态的值,而不需要整个策略,因此有单步更新速度快的优点.整个Q-learning的训练流程如算法1所示.

算法1:Q-learning训练过程1.初始化Q表中的值,折扣因子γ,迭代次数i=0;2.while i≤最大迭代次数do 3.while所处的状态st不是终止状态do 4.根据当前所处的状态st,选择Q表中对应的预期奖励最大的动作at;5.执行动作at,进入下一个状态st+1,并获得奖励rt;6.根据奖励rt更新Q表对应的部分;7.end 8.i=i+1;9.end
Q-learning在机械控制、游戏智能等领域有着广泛的应用[22].然而,现实情况中的问题会很复杂,状态多到难以统计,使用二维表的方式去记录所有可能的状态和行为是不现实的.不过,在机器学习中,神经网络可以很好地解决此问题.DQN可以看作是Q-learning和神经网络的结合[17].DQN将环境状态作为神经网络的输入,经神经网络计算后得到每个动作的Q值.神经网络接受环境状态的信息,类似人类通过眼睛、鼻子和耳朵接受外界信息,通过大脑——神经网络,分析出每个行为未来可能带来的预期收益,然后选择收益最大的行为执行.整个过程是将当前智能体所处的环境状态编码,并将该编码输入神经网络,然后神经网络通过对当前状态的计算,输出其执行每个行为后能获得的预期奖励,选择预期奖励最大的行为作为接下来要执行的行为.选择行为过程如图2所示.

图2 DQN选择行为过程Fig.2 Process of DQN selection behavior
同时,DQN为了加快神经网络的收敛,还使用了经验回放机制和“冻结”Q-网络机制[19].根据Q-learning的更新方式,每执行一次动作转换到新状态就进行一次神经网络的更新,这导致神经网络频繁抖动而难以收敛.不同于Q-learning,经验回放机制是指训练过程中DQN会维护一个“记忆库”来存储四元组(s,a,r,s′),即从状态s执行动作a转移到状态s′,获得的奖励为r.DQN每次更新时都会随机抽取“记忆库”中的部分四元组进行学习优化,这种随机抽取部分内容的方式打乱了学习经历之间的相关性,使神经网络更新更有效率.同时,由于神经网络更新的数据来源于数据库,因此也不需要智能体真实地与环境进行交互,而是可以使用“别人的经历”.类似于人类学习,既可以从自己的“经历”中学习,也可以从他人告知的“经历”中学习.“冻结”Q-网络机制也是一套打乱相关性的方法,在DQN中,常使用两个结构相同但参数不同的神经网络,其中用来预测Q(st,at)的神经网络称作Q-估计网络,而用来计算R(st,at)+γQ(st+1,at+1)的神经网络称作Q-现实网络.每次更新DQN时仅更新Q-估计网络,而Q-现实网络使用之前的参数,经过一段时间后,才会使用最新的网络参数,即一段时间内“冻结”Q-现实网络的参数.通过这种方式计算出来的Q(st,at)和Q(st+1,at+1)降低了相关性,使得更新更有效率.综上,整个DQN的训练流程如算法2所示.

算法2:DQN训练过程输入:最大迭代次数T;两个完全相同的神经网络模型;训练步长step;训练样本数k;同步网络步长syn step;记忆库容量M;折扣因子γ.输出:预测Q值的神经网络.1.初始化迭代次数i=0;2.while i≤最大迭代次数do 3.while所处的状态st不是终止状态do 4.根据当前所处的状态st,选择Q表中对应的预期奖励最大的动作at;5.执行动作at,进入下一个状态st+1,并获得奖励rt;6.if记忆库当前大小m<M then 7.将四元组{st,at,rt,st+1}存入记忆库;8.end 9.else 10.删除记忆库的第一条记录;11.将四元组{st,at,rt,st+1}存入记忆库;12.if i % step=0 then 13.从记忆库中随机选择k个样本;14.根据样本用两个神经网络计算对应状态下的Q值;15.将(R(st,at)+γQ(st+1,at+1)-Q(st,at))2作为损失函数更新神经网络参数;16.if i % syn step=0 then 17.将Q-估计网络的神经网络参数同步到Q-现实网络;18.end 19.end 20.end 21.i=i+1;22.end
2.3 基于符号变换的特征构造方法
在通常情况下,数据中的很多特征信息都是通过观察、测量等手段获得的,这类信息往往含有干扰维度,且往往与要进行预测的目标相关性较低.尽管有很多类似核函数的升维方法,但升维选择的核函数较为单一,使得模型预测精度不能达到应用要求.基于上述问题,本工作提出了一种基于符号变换的特征构造方法,用来生成新的特征,以提高模型的预测精度.
符号变换的思想来源于符号回归[23],主要是将各维度的数据通过符号,即数学操作符、常量等,组成各种各样的数学表达式,而新组成的数学表达式空间可看作是构造的新的特征空间.符号变换的方法不需要假设特征和目标之间的相互关系,新组成的数学表达式由特征和符号组成,其中数学操作符包括“+”“-”“*”“/”和“lg”等.符号变换生成数学表达式的过程可以看作是特征从低维空间映射到高维空间的过程,通过取对数、幂函数等非线性方式,将原始特征互相组合,并进行非线性变换,使得生成的数学表达式特征相比于原始特征能够更好地描述目标变量.可以选择的符号算子如下:①布尔型特征:析取、合取、否定等;②数值类特征:最小值、最大值、加法、减法、乘法、除法、三角函数变换、对数、幂函数等.
通过一次符号变换所组成的特征不一定能很好地描述预测目标,因此可以重复迭代多次,将新组成的数学表达式空间看作是在一个原始特征空间上继续进行符号变换,最后将多次符号变换的结果作为最终构造的特征空间.然而,通过上述方式组成的数学表达式空间中存在大量的冗余和干扰特征,需要进行特征选择,使预测目标变量能够更加准确.本工作提出一种基于符号变换的特征构造过程和基于强化学习的特征选择过程,使得筛选出来的数学表达式特征能够更好地描述目标变量,整个框架如图3所示.

图3 结合符号变换的特征构造和基于强化学习的特征选择整体框架Fig.3 Overall framework of feature construction based on symbolic transformation and feature selection based on reinforcement learning
整个特征选择的过程首先是对数据源进行数据清洗、归一化等预处理操作;然后再用符号对每个特征进行变换,形成新的特征集合,整个过程不断迭代,直至满足条件产生新的更大的特征空间.特征构造过程可表示为如图4所示的树形结构,其中F1,F2,···,F8是原始数据特征,O1,O2,···,O7是符号变换.通过符号变换,将F1、F2等原始数据特征转化成新的特征,组成新的特征空间space1,之后再对新的特征空间继续进行符号变换,得到特征空间space2、space3.特征空间中新构造的每一个特征融合了多维原始特征,因此每一个新特征能够表现出多维原始特征的某些特性,具有更好的表达能力.在产生的新的特征空间中使用强化学习进行特征选择来降维,可去除大量冗余特征,进一步提升预测精度,得到最终选择出的特征子集以及模型.

图4 基于符号变换的特征构造过程举例Fig.4 An example of the process of feature construction based on symbolic transformation
2.4 基于强化学习的特征选择算法设计
结合封装式特征选择的特点以及强化学习中的DQN方法,本工作提出一种基于强化学习的特征选择(feature selection based on reinforcement learning,FSRL)算法.FSRL算法利用智能体的决策能力选择特征子集,通过训练一个收敛的价值网络得到最优特征子集.
FSRL算法流程如图5所示.环境状态编码是一个仅由0和1组成的n维向量,n是全部特征个数.若向量中第i个元素为1,则表示第i个特征已经被加入当前特征子集;若向量中第i个元素为0,则表示没有被加入.每次选择一个新的特征加入特征子集后,环境状态编码对应位置的数字由0变为1.流程开始时先对原始数据进行预处理,包括数据归一化、删除异常点以及过滤式特征选择等;然后初始化特征子集为空集,智能体可执行的行为有n种(n表示可选特征的个数),每次选择某个特征加入特征子集.同时,设定一个超参数表示最后选择的特征子集大小.若当前特征子集等于设定的特征子集时,将选择的特征子集输入分类器,测试当前所选特征子集的准确率,并将其作为环境反馈奖励大小的依据.但是,单纯使用准确率作为奖励函数,会使得整个训练过程中都是正奖励,即全都是增加选择该特征的趋势,不易收敛且很容易陷入局部最优解.因此,可以设置一个基准目标target,当分类准确率大于target,反馈正奖励;低于target,反馈负奖励,即对于特征选择后模型能达到的分类准确率有一个目标.具体的奖励score设置为

图5 基于强化学习的特征选择算法流程Fig.5 Flowchart of feature selection algorithm based on reinforcement learning

式中:α是比例因子,用于放大准确率accuracy和目标target间的差值.由于accuracy和target都是[0,1]的小数,仅仅以二者的差作为奖励会使得奖励都很小,整个训练过程的变化很慢,不容易收敛,因此需要引入比例因子进行适当放大.
同时,为了避免探索过程中持续选择同一个策略,即陷入局部最优解,可使用ε-贪心策略,即智能体有ε的几率按照最大预期奖励的方式选择对应的特征子集,同时也有1-ε的几率随机选择行为.通过该策略可以有效跳出局部最优解,从而尽量获得全局最优[24].此外,按照设定的方法选择特征,有可能出现当前特征已经被选进特征子集中,但是后续预测过程中选择该特征的行为的预期奖励最大,即依旧选择该特征,此时智能体会选择预期奖励第二大的特征.
为了验证算法的有效性,本工作将FSRL算法分别应用于两个材料数据集——非晶合金材料和铝基复合材料,两个数据集对应两个不同的预测任务:分类和回归.
3.1 非晶合金材料分类
非晶合金,又称为“金属玻璃”,是一类新型的多组元合金,因其具有高强度、高硬度、耐腐蚀、超塑性、软磁性等优异性能,被广泛应用于新能源、高端制造业等高技术领域[25].非晶合金的研发不同于传统材料,因此快速研判给定材料是否属于非晶合金在实际应用中具有重要价值.基于已有研究收集的非晶合金数据集,通过强化学习特征选择,从全部数据集的94维特征中选出固定的10维特征来预测非晶合金类型.BMG(bulk metallic glass)为大块金属玻璃,RMG(ribbon metallic glass)为带状金属玻璃,CRA(crystalline alloy)为结晶合金.数据集共包含5 935条数据,其中BMG类别有675条,RMG类别有3 708条,CRA类别有1 552条.对于分类问题而言,这是一个类别不平衡的数据集,若以常规的随机采样方式分割训练集和测试集,会使得分类器偏向于大类别,使准确率指标的参考性大幅降低.因此,本工作使用分层抽样的方法,即根据数据中3种不同的类别,将总体数据集分成3个不同的子总体(称为层),在每层中按照3类对应数据的比例随机抽取样本分成训练集和测试集.通过分层抽样方法使得测试集中含有的3个类别数据的比例和训练集大致相同,也使得各评价指标能够有效说明分类的结果.
在数据预处理阶段,通过计算特征之间的Pearson相关系数过滤掉一部分冗余特征.假设X、Y为两个随机变量,有N条记录,则X和Y的Pearson相关系数为

Pearson相关系数反映了两个变量之间的线性相关程度,因此式(6)可以看作是两个随机向量中得到的样本集向量之间夹角的余弦值.在实验过程中,对于Pearson相关系数大于0.85的两个特征,仅保留其中一个,即其中一个特征能够被另一个特征线性表示,则该特征是冗余的.通过数据预处理,仅保留50维特征.由于数据本身维度较高,并且分类任务相较于回归比较简单,因此在得到的数据集上没有使用基于符号变换的特征构造方法,仅在保留的50维特征上使用FSRL算法.同时,选择多个分类器来验证FSRL算法的有效性.
从表1可以看出,经过降维后,4种模型算法在准确率方面都有了不同程度的提升,其中决策树算法的提升最大.这是由于决策树本身是通过类似多叉树的方式进行分类,尽管有一定的剪枝策略,但决策树的优化常需要调参,并且这种通过人为调参避免过拟合的方式不容易找到一个合适的参数.通过特征选择的方式减少特征维度,使得决策树的选择范围变小,有效减小树的深度,避免了过拟合现象.

表1 使用全部特征和特征选择后的准确率结果Table 1 Accuracy results using all features and feature selection
为了从多个角度评价分类效率,表2对比了FSRL算法使用与否情况下4种机器学习模型在每个类别的精确率和召回率.从表2可以看出,通过FSRL算法进行特征选择后,大部分非晶合金类别的精确率和召回率都有明显的提升,且3个类别在召回率上的表现均是FSRL算法处理后的结果最优.在精确率上,只有RMG分类上的FSRL结果较全部特征差0.002.FSRL算法在总体表现上更加优异,能够很好地区分3类非晶合金材料,验证了在分类任务中通过FSRL算法进行特征选择能够有效减少特征数量,提升分类效果.

表2 使用全部特征和特征选择后的精确率和召回率结果Table 2 Precision and recall results using all features and feature selection
3.2 铝基复合材料性能预测
复合材料是指通过将两种及两种以上性质不同的物质,使用不同的成分配比混合制成的新型材料.复合材料克服了单一材料某些性能不足的问题,从20世纪中期开始,就受到材料领域的广泛关注和重视.根据复合材料中使用的基体种类不同,可以大致分成3类:树脂基复合材料、金属基复合材料以及陶瓷基复合材料.金属基复合材料由于具有更好的综合性能、更高的性价比和良好的发展前景,而受到研究人员的青睐.金属基复合材料中,由于铝具有成本低、抗老化性能好、可加工性好等优点,被更多地应用于复合材料的基体.目前,铝基复合材料已被应用于航空航天、电子和光学仪器等领域[26].力学性能是铝基复合材料的关键性能,其中抗拉强度和延伸率尤为重要.
本实验数据集由32条铝基复合材料的实验数据构成,其中特征10维主要包括成分特征(基体、增强体各2维)和工艺参数(热压温度、热压压力、固溶温度、固溶时间、时效温度和时效时间).预测的目标变量为抗拉强度和延伸率.
在应用基于符号变换的特征构造方法时,在原始特征基础上使用16种运算符组合生成第一轮特征空间space1,然后在space1上重复使用上述运算符,生成第二轮特征空间space2,重复上述过程3次,得到3个特征空间.这3个特征空间大约包含了109数量级的组合特征.最后,使用Pearson相关系数筛选相关性最大的前100维特征,对这100维特征使用FSRL算法进行特征选择.
在使用FSRL算法进行特征选择时,相比分类问题中的FSRL算法进行了优化.主要优化体现在,设定选择的最大特征数为20,同时设置可选行为有(n+n/2)种,这里n代表特征升维过程结束后得到的新的特征维度,其中前n个行为表示选择对应的第n维特征加入特征子集,之后的n/2个行为表示终止选择过程.对当前的特征子集进行评估,要尽可能降低选出空集的趋势,如果当前子集为空时,选择了第n到第(n+n/2)行为,则给一个负奖励.由于智能体探索到终止选择过程的概率比较低,所以需要增加n/2个行为终止选择,使得最后的特征选择的最优特征子集尽可能小(特征子集越小,越能避免过拟合).通过上述方法可以使得FSRL算法具有动态选择最优特征子集大小的能力,而不需要人为指定选择多少个特征后再停止.
实验结果为10折交叉验证结果,这里使用“1-平均绝对百分比误差”(mean absolute percentage error,MAPE)作为衡量指标:

式中:ytrue为实际值;ypre为预测值.
表3和4显示了铝基复合材料使用构造新特征中的100维数据以及FSRL两种特征选择方法的结果,同时也比较了动态选择特征和固定特征子集个数两种方式的结果,其中5种常见的回归预测模型作为基础模型,SVR(support vector regression)代表支持向量回归.

表3 铝基复合材料延伸率预测结果Table 3 Elongation prediction results of aluminum matrix composite
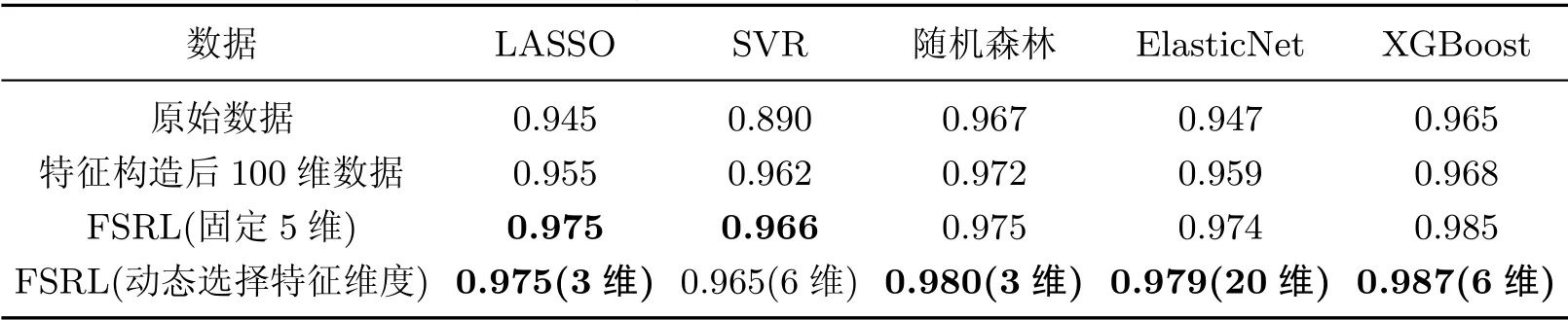
表4 铝基复合材料抗拉强度结果Table 4 Tensile strength results of aluminum matrix composite
从表3和4延伸率和抗拉强度的预测结果可以看出,基于符号变换的特征构造方法能明显提升多个基础模型的预测能力.同时,经过FSRL算法降维,减少了大量的冗余和噪声维度,能够进一步提升模型的预测精度.两组实验的预测结果显示,在大多数基础模型中,使用动态选择特征维度的方法比固定数据维度的结果要好(仅在抗拉强度的SVR模型预测中略低0.1%).这是由于动态选择特征维度后,搜索空间变大,在迭代次数足够多的情况下能够探索到更多可能的特征组合,而动态选择的数据维度不是5维的预测结果也从侧面印证了这一结论.
本工作提出了一种基于强化学习的特征选择方法,并将其应用到材料数据的特征选择过程中,可有效降低特征维度,去除冗余信息,提高模型的泛化能力.
首先,在非晶合金材料的分类任务中应用固定维度的FSRL算法.结果表明,通过特征选择使得4种基础模型的分类准确率得到了提升,最高提升了2.8%.同时,对于每个类别的精确率和召回率,只有在非晶RMG的分类上,FSRL算法的精确率结果较全部特征差0.002,其余均是FSRL算法最优,从而验证了FSRL算法在分类任务上的有效性.
其次,在铝基复合材料的回归任务中,先是通过基于符号变换的特征构造方法构造出新的特征,然后再用FSRL算法在新构造的特征集中进行特征选择.同时,由于回归任务较分类任务更为复杂,通过动态确定特征维度的方法扩大了搜索空间范围.结果表明,基于符号变换的特征构造方法能够将一些相关性较低的特征组合成相关性高的新特征,从而提高数据的表达能力.并且,动态确定特征选择维度相较于固定特征维度也更为有效.
未来的研究可以通过剪枝操作避开一些明显会对模型造成劣化的特征,缩小搜索范围,加快强化学习收敛速度.同时,DQN算法的稳定性和收敛性问题也是一个值得继续探索和改进的方向.
猜你喜欢 子集特征选择神经网络 基于神经网络的船舶电力系统故障诊断方法舰船科学技术(2022年11期)2022-07-15基于人工智能LSTM循环神经网络的学习成绩预测中国教育信息化·高教职教(2022年4期)2022-05-13高一上学年期末综合演练中学生数理化·高一版(2022年1期)2022-04-05K5;5; p 的点可区别的 IE-全染色(p ?2 028)华东师范大学学报(自然科学版)(2022年2期)2022-03-31MIV-PSO-BP神经网络用户热负荷预测煤气与热力(2022年2期)2022-03-09三次样条和二次删除相辅助的WASD神经网络与日本人口预测软件(2017年6期)2017-09-23基于智能优化算法选择特征的网络入侵检测现代电子技术(2016年23期)2017-01-12故障诊断中的数据建模与特征选择电脑知识与技术(2016年25期)2016-11-16reliefF算法在数据发布隐私保护中的应用研究电脑知识与技术(2016年15期)2016-07-04一种多特征融合的中文微博评价对象提取方法电脑知识与技术(2016年14期)2016-06-30